The browser fingerprint mechanism poses a major challenge to automation scripts, particularly in web scraping. The issue lies in the fact that most tools used to build scraping bots set generic, predictable fingerprints.
In this post, I’ll dive into the world of browser fingerprinting, showing you how it works, why it matters, and how you can effectively spoof it to avoid detection.
Before proceeding, let me thank Decodo, the platinum partner of the month. They are currently running a 50% off promo on our residential proxies using the code RESI50.
Browser fingerprinting is a technique used to identify and track users online by collecting a set of unique data points from their browser and device settings.
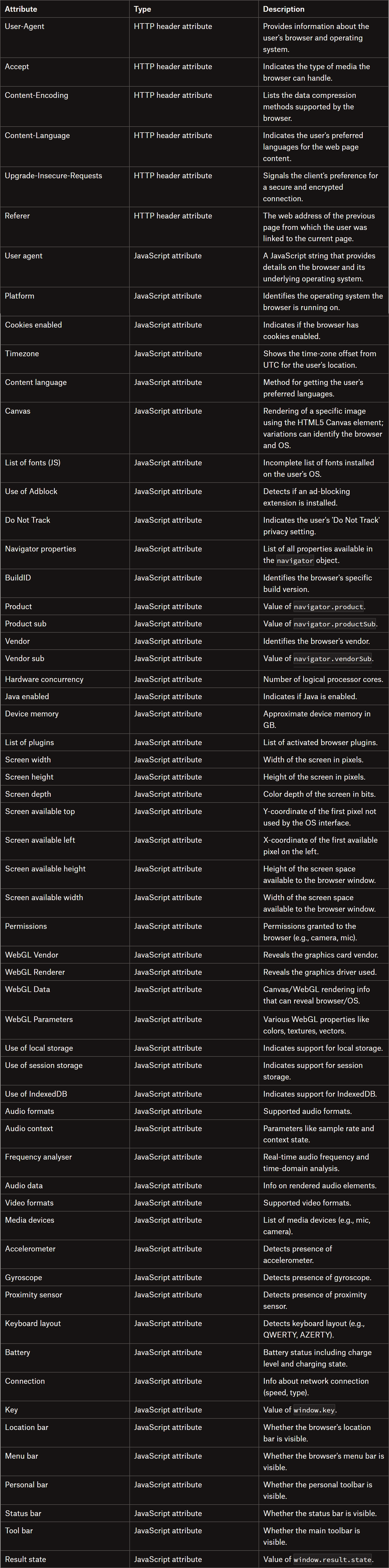
The data collected to produce the fingerprint usually includes browser type and version, screen resolution, language settings, time zone, installed fonts, supported audio/video formats, and more. Some of this information is available through JavaScript APIs in the browser, while other parts come from the HTTP headers automatically sent by the browser when a request is made.
If you're wondering how that's possible given privacy concerns, keep in mind that all that information is accessible either through HTTP headers or directly from the frontend via JavaScript. You can even verify it yourself in your browser’s console:
Accessing browser fingerprinting data in the console via JavaScript
This episode is brought to you by our Gold Partners. Be sure to have a look at the Club Deals page to discover their generous offers available for the TWSC readers.
So, this isn't a "shady" technique. Quite the opposite, it's simply based on publicly accessible data that any web page/server can read/access.
A browser fingerprint can be generated directly on the client using information collected via JavaScript, or more commonly on the server by combining client-side data with information extracted from the HTTP request. The goal is to gather enough attributes and aggregate them to create a unique fingerprint.
That fingerprint can then be used to track a user across browsing sessions and even across different websites (e.g., if they are all served through the same CDN like Cloudflare) to tailor website content and user experiences. Still, it’s mostly implemented to distinguish legitimate users from bots as part of anti-scraping and anti-abuse measures.
Aspects That Count in the Calculation of Browser Fingerprints
There’s no single recipe for generating a valid and unique browser fingerprint, and the ingredients can vary from one implementation to another. However, some habitually collected data points include:
Main browser fingerprinting calculation aspects
Verify Your Browser Fingerprint
If you're curious to see what your browser fingerprint looks like, you can visit sites like Am I Unique?
My browser fingerprint test results
Or, similarly, you can get useful information about your browser on Browserleaks.
Why Browser Fingerprinting Matters in Web Scraping
As I mentioned earlier, one of the main uses of browser fingerprinting is to tell bots apart from real users. But how does that actually work?
These tools let you programmatically control a browser instance via code. The problem is, the browser environment they spin up is almost identical across bots. That means the browser fingerprint they produce is extremely common.
If a bunch of data points in your fingerprint are too generic, it’s likely you’re a bot. Why? Because real users tend to personalize their browsers (e.g., installing extensions, setting different languages, and so on). The same applies to their device. All of that creates a “unique” fingerprint (“unique” because most fingerprints aren’t really 100% unique). And that “uniqueness” is what helps distinguish a human from a bot.
So, when a browser fingerprint looks “too standard,” it can trigger suspicion. You might get blocked instantly or be shown a CAPTCHA by a WAF (Web Application Firewall) or an anti-bot system to double-check you’re human.
Deep dive: That’s exactly what Cloudflare does. It collects info from your browser (which is why their check takes a few seconds), sends it to their servers for analysis, and if your fingerprint (together with other signals) looks shady, you get the Turnstile CAPTCHA:
Browser fingerprinting verification in Cloudflare
Before continuing with the article, I wanted to let you know that I've started my community in Circle. It’s a place where we can share our experiences and knowledge, and it’s included in your subscription. Enter the TWSC community at this link.
The second way browser fingerprinting is used against bots is tracking. Even if you tweak your browser automation tool to produce a convincing fingerprint, if you always use the same one, web pages can start recognizing you. Over time, they might notice bot-like behavior patterns through UBA (User Behavior Analytics), and that’s when the red flags go up.
This is why rotating your browser fingerprints regularly is just fundamental. It makes it harder for servers to track and block you, especially when combined with proxy-based IP rotation.
How to Spoof Browser Fingerprinting
Let’s see how to customize Playwright (similar principles apply to Puppeteer and Selenium) to generate a fingerprint that’s less bot-like and more human.
Step #1: Get the Fingerprint for Vanilla Playwright
Start by launching a vanilla Playwright instance and instruct it to visit Am I Unique?. Wait for the fingerprint to be generated and then take a screenshot of the result:
from playwright.sync_api import sync_playwright
import time
with sync_playwright() as p:
browser = p.chromium.launch()
context = browser.new_context()
page = context.new_page()
# Navigate to the fingerprinting test page
page.goto("<https://amiunique.org/fingerprint>")
# Close the privacy policy banner
page.click(".v-snack__wrapper [type=\\\\"button\\\\"]")
# Wait 30 seconds for the fingerprint result element to appear
time.sleep(30)
# Take a screenshot of the result
page.screenshot(path="vanilla_fingerprint_result.png", full_page=True)
# Close the browser and release its resources
browser.close()
Note: For more realistic results, run this on the server where you plan to deploy your scraper (or in a Docker container that mimics that environment). Running it on your personal computer may produce a fingerprint influenced by your device’s custom settings, giving a false impression that Playwright’s default fingerprint is already not standard.
This will produce a result like:
Browser fingerprint result for vanilla Playwright on a Linux server
The colored bars shown by Am I Unique? can be confusing at first. Why are the bars red when the likelihood values are low? Doesn’t that mean you're more unique? Actually, it's the opposite, because the data collected by the site originates from real human users, not bots.
While every browser setup is technically unique, most real users share common traits and configurations. So even if their fingerprints are distinct, they still follow recognizable patterns. When your browser shows too rare values (traits that don’t appear often among regular human users), it likely signals automation.
In short, low-probability values in Am I Unique? don’t mean you're safe. They mean your fingerprint stands out in a suspicious way, which is why the bars are red or yellow.
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
viewport={"width": 1536, "height": 960},
locale="en-US",
timezone_id="America/New_York",
# Add other custom settings here...
)
Consider installing popular browser extensions and tweaking additional settings to make your fingerprint appear more natural and harder to detect.
Step #3: Test the New Fingerprint
Here is the complete Playwright code for a tweaked instance:
from playwright.sync_api import sync_playwright
import time
with sync_playwright() as p:
browser = p.chromium.launch()
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
viewport={"width": 1536, "height": 960},
locale="en-US",
timezone_id="America/New_York",
# Add other custom settings here...
)
page = context.new_page()
# Navigate to the fingerprinting test page
page.goto("<https://amiunique.org/fingerprint>")
# Close the privacy policy banner
page.click(".v-snack__wrapper [type=\\\\"button\\\\"]")
# Wait 30 seconds for the fingerprint result element to appear
time.sleep(30)
# Take a screenshot of the result
page.screenshot(path="custom_fingerprint_result.png", full_page=True)
# Close the browser and release its resources
browser.close()
This time, the fingerprint you get should be more credible:
Best Browser Fingerprint Generators and Spoofing Solutions
As I covered before, the browser fingerprinting game isn’t just about being unique. If your fingerprint is too unique, it might raise suspicion that you're a bot. The key is to have a unique combination of data points where each resembles those of real users.
Also, some data points are more important than others. For example, if you set a clearly bot-like user agent, you will likely get blocked regardless of how unique your other settings are.
Thus, configuring the right browser fingerprint isn’t a piece of cake—given you should also rotate fingerprints regularly to avoid long-term tracking. As a result, fingerprint management is an ongoing challenge, not a once-and-done problem.
That’s why I recommend using specialized libraries designed to automatically modify browser fingerprints:
Best browser fingerprint spoofing libraries
These packages simplify the injection of realistic browser fingerprints into popular browser automation tools. Yet, this technique is no longer considered the most modern approach.
Based on my experience, it generally makes more sense to use browser automation solutions developed specifically for scraping—such as Camoufox, SeleniumBase, or NoDriver—which come with advanced anti-detection features out of the box.
On top of that, there’s a myriad of commercial anti-detect browsers on the market, like Kameleo or GoLogin, just to mention two of them. Their main purpose is to create the best browser fingerprint possible for automating your scraping or browsing operations.
The Web Scraping Club is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Conclusion
The goal of this post was to uncover the nuances behind browser fingerprinting. As I discussed throughout the article, crafting a valid fingerprint is a balancing act between uniqueness and plausibility.
I hope you found this technical guide useful and learned something new along the way. Feel free to share your thoughts or experiences in the comments—until next time!
Open‑source is great for learning and prototyping, but at scale we often see teams burn a lot of valuable engineer hours on endless fingerprint tweaks. For long‑term reliability, a specialized paid vendor is usually more cost‑effective. It costs much less than a single engineer‑day, while your team can focus on your core product.












Thanks for the mention and for a thoughtful deep‑dive!
Humbly, we’re working hard to build what we hope is the best fingerprinting browser.
-My co‑founder/CTO has been hacking browser fingerprints since 2014
-Since we founded Kameleo in 2017, most of our R&D has gone into masking browser fingerprints in a consistent way
-We ship browser kernel updates weekly to stay on top of the cat-and-mouse game (https://kameleo.io/browser-kernel-releases)
Open‑source is great for learning and prototyping, but at scale we often see teams burn a lot of valuable engineer hours on endless fingerprint tweaks. For long‑term reliability, a specialized paid vendor is usually more cost‑effective. It costs much less than a single engineer‑day, while your team can focus on your core product.