
THE LAB #65: Scraping Datadome protected websites with Camoufox
Discovering the features of Camoufox, a custom and stealthy version of Firefox

Last-minute update: While Camoufox still works for most websites using Datadome, the example shown in the code stopped working today just before the article was published. I decided to publish it anyway since Camoufox is a great tool worth discovering, regardless of the particular case of the Hermes website.
Second update: Now the code in the repository works; I needed to change the entry point on the website. Thanks to Daijiro for finding the quick workaround.
If we think about the list of features a browser should have for being used as a scraping tool, especially when we encounter websites protected by strong anti-bot solutions like Datadome, it should contain the following:
A fingerprint spoofing and rotation management
human-like mouse movement library
headless and remote connection
cannot be detected by CDP test techniques
Traditional anti-detect browsers allow you to spoof fingerprints and can be used in a headless mode but rarely contain a human-like mouse movement library.
Camoufox is an open-source package maintained by daijiro (the author of hRequests, BrowserForge, and other interesting packages). It has all these features, so today, we’re going to test it against a website that is heavily protected by bots, Hermes.com.
It also gained popularity among our Discord community thanks to its usability and capability to bypass the most popular anti-bot solutions.


While it’s still a work in progress and unsuitable for a production environment, it’s interesting to see it working against these challenging targets.
The script is in the GitHub repository's folder 65.CAMOUFOX, which is available only to paying readers of The Web Scraping Club.
If you’re one of them and cannot access it, please write to me at pier@thewebscraping.club so I can add you to the team.
Camoufox features
Fingerprint spoofing
As mentioned, fingerprint spoofing is one feature we cannot miss on a browser used for web scraping. In fact, without that, every spider we would run on a server will be easily detected and blocked.
Camoufox changes the fingerprint of your scraper by mimicking an installation of Firefox on consumer-grade hardware, so your requests will go unnoticed by anti-bot software.
For example, this is the fingerprint detected by BrowserScan for my Mac Studio, and this is the fingerprint I got from the same computer by running a sample script with Camoufox.


In fact, Camoufox embeds a previous project by Daijiro, Browserforge (which will be soon deprecated), that forges browser fingerprints and inject them in your Playwright scraper, as we have seen in our previous article.

Our first run's output looks legit, but it’s forged natively without using any of the additional options available. As the documentation shows, we can set the exact values of several parameters if we’re brave enough, but in our test, we’ll see that it won’t be needed.
Finding the most efficient way to scrape a website is one of the services we offer in our consulting tasks, in addition to projects aimed at boosting the cost efficiency and scalability of your scraping operations. Want to know more? Let’s get in touch.
Stealth Patches
Camoufox also includes a set of patches for the most well-known anti-bot detection techniques.
One of the most well-known tests is CreepJS, where, with my Mac Studio and Brave Browser, I get a meager trustability score of 7%.
Here’s the test with Camoufox

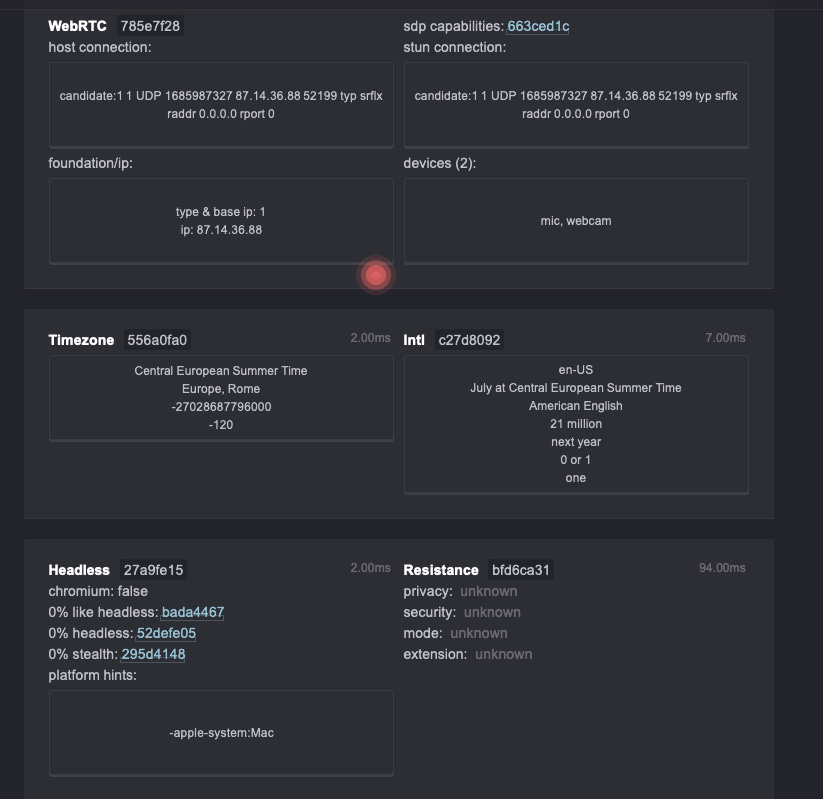
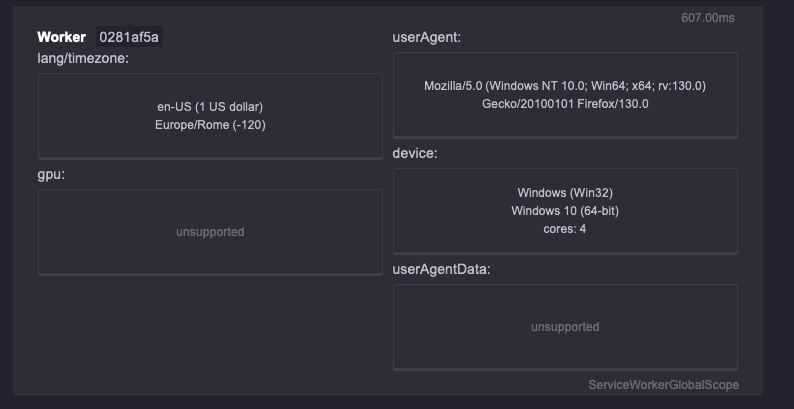
There are no red flags, and it's a good 68% score. Again, the documentation contains the list of patches applied to Firefox to make it undetectable, and it’s quite impressive.
I wanted to know more about what happens under the hood and reached out Daijiro directly for some technical details about this sentence in the documentation
In Camoufox, all of Playwright's internal Page Agent Javascript is sandboxed and isolated. This makes it impossible for a page to detect the presence of Playwright through Javascript inspection.
Here’s his explanation:
Playwright's page agent manages interactions between Playwright and the web page. Normally, Playwright injects some JavaScript into the page such as window.__playwright__binding__ and to perform actions like querying elements, evaluating javascript, or running init scripts, which can be detected by websites. In Camoufox, these actions are handled in an isolated scope outside of the page. In other words, websites can no longer "see" any JavaScript that Playwright would typically inject. This prevents traces of Playwright altogether, and avoids the cat and mouse game of injecting more JavaScript to evade bot detection.
Human-Like Mouse Movement
The latest main feature is human-like mouse movement, which allows us to draw more plausible trajectories with the mouse cursor when moving it between two points on the page.
To achieve this, you need to interact with the browser and automate its operations in a way that is not detectable. Camoufox uses a patched version of Juggler for this.
Again, I’ve asked Daijiro to explain to us what is Juggler and how it is used in Camoufox
Juggler is a custom protocol that's maintained by the Playwright team to automate Firefox. It doesn't rely on native automation APIs in Firefox which could give away it's being remotely controlled. Camoufox uses a modified version of Juggler that includes patches to avoid JavaScript detection, natural cursor movement, relaxes Playwright's default behaviors, and remains fully compatible with the original Playwright library.
Writing a scraper with Camoufox
Now we understand more about the library, we can start using it.
After the installation, which is available via pip, we can start building our scraper in Python, just like we would with Playwright.
with Camoufox(humanize=True,
proxy={
'server': 'http://IP:PORT',
'username': 'USER',
'password': 'PWD'
},
headless="virtual", geoip=True
) as browser:
page = browser.new_page()
page.goto("https://www.browserscan.net/")
page.wait_for_load_state()
time.sleep(100)
page.goto("https://abrahamjuliot.github.io/creepjs/")
page.wait_for_load_state()
time.sleep(100)Let’s examine this small example. In the first line, using the code with Camoufox(humanize=True, we’re starting a new instance of the Camoufox browser and adding the human-like mouse movement, setting the humanize option to true. In this particular example, it is not needed since we don’t have to click anywhere, but we’ll use it on the Hermes code later.
Like in Playwright, we’re setting up the proxies by using the following syntax,
proxy={
'server': 'http://IP:PORT',
'username': 'USER',
'password': 'PWD'
},and then we can set up the headless option. In addition to the standard True and False values, we have a third value, virtual, that makes the scraper run on a virtual server (on Linux) using xvfb. This is particularly useful if the traditional headless mode gets detected, but we don’t want to spawn an actual browser window.
Lastly, we have the GeoIP option, which matches the browser’s timezone to the one belonging to the IP used by the scraper. It will also spoof the WebRTC IP to the scraper IP, avoiding any leak of the source IP. This is extremely useful when using a proxy, like in this case, so that all the data regarding the IP used for scraping is coherent.
Scraping Hermes data with Camoufox
