
A deep dive into device fingerprint
What is device fingerprinting, how it is used and why it's important for web scraping.

What is device fingerprinting?

A device fingerprint - or device fingerprinting - is a method to identify a device using a combination of attributes provided by the device itself, via its browser and device configuration. The attributes collected as data to build the device fingerprint depend on the solution used to build it, but typically the most common are:
operating system
screen size and resolution
user-agent
system language and system country
device orientation
battery level
installed fonts and installed plugins
system uptime
IP address
HTTP request headers
Since most of these parameters are read from the browser settings, we can also use the term “browser fingerprinting” with the same connotation.
If you want to test which machine features are leaked from your browser just by browsing a web page, you can use this online test to check with your eyes, simply with a Javascript executed on the server.
Consider also that most of the common anti-bot solutions use this basic information and enrich them with more complex test results, like Canvas and WebGL fingerprinting, to add even more details to these fingerprints.
The point is: the more pieces I add to the fingerprint, the more granular it becomes (because it’s less likely for two users to have the exact same device configuration). In this way, I can abstract a small niche of users with one fingerprint and track their behavior, without using cookies.
And this is key in these times when cookies are under the scrutiny of GDPR, CCPA, and other internet regulations and users are getting more aware of them, deciding to opt-out or wipe them from their machines. But it’s not only a matter of marketing, but also anti-fraud and anti-bot in general are involved in developing this kind of technologies. In fact, detecting fingerprints that contain some incompatible data or outliers in configurations, can raise some red flags in the traffic.
How a device fingerprint is collected?
As we have seen, a fingerprint is a collection of single pieces of information collected when a device connects to a server.
Depending on the method used for collecting this information, we can divide them by active and passive fingerprinting techniques.
Active fingerprinting is when a server interacts with the device, using a challenge that the browser needs to solve. An example can be the Canvas fingerprinting or WebGL fingerprinting technique. In both cases, an image with a text overlay is rendered off-screen. On different hardware, this image and its result hash string are rendered differently, so we have different fingerprints for different hardware.
Passive fingerprinting is when the server simply gathers the information passed by the browser and the different HTTP connection layers: IP address, request headers, user agent, screen resolution, operating system, and so on.
Modern anti-bot softwares combines both these families of techniques and integrate them with behavioral analysis and AI to detect incongruences in the settings of the device and the scraper.
If you’re curious about the number and the type of information that can be gathered via your web browser, you can have a look at deviceinfo.me, an online test where you can discover all these details.
As you can see from the following images, the description of your device is quite accurate.

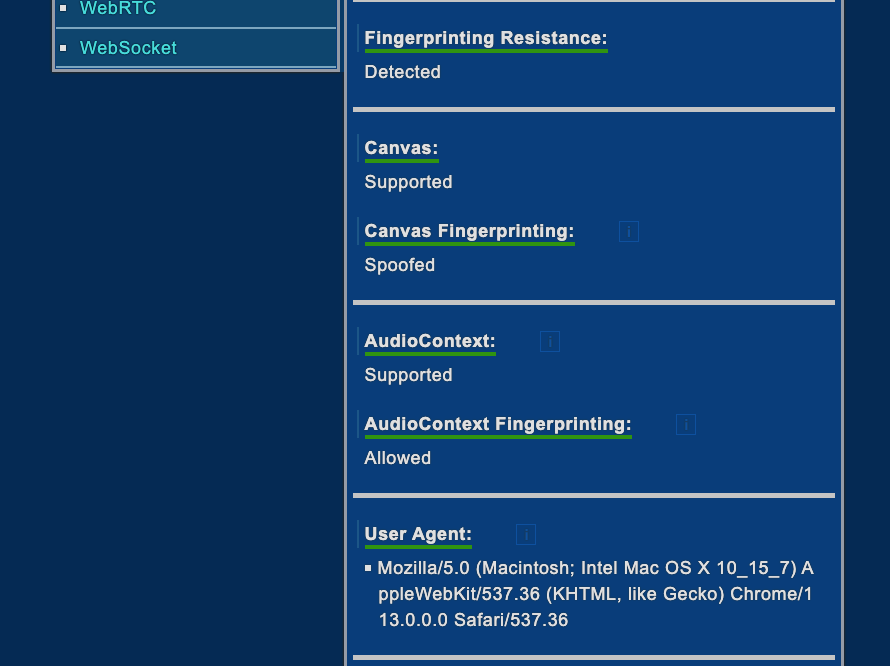
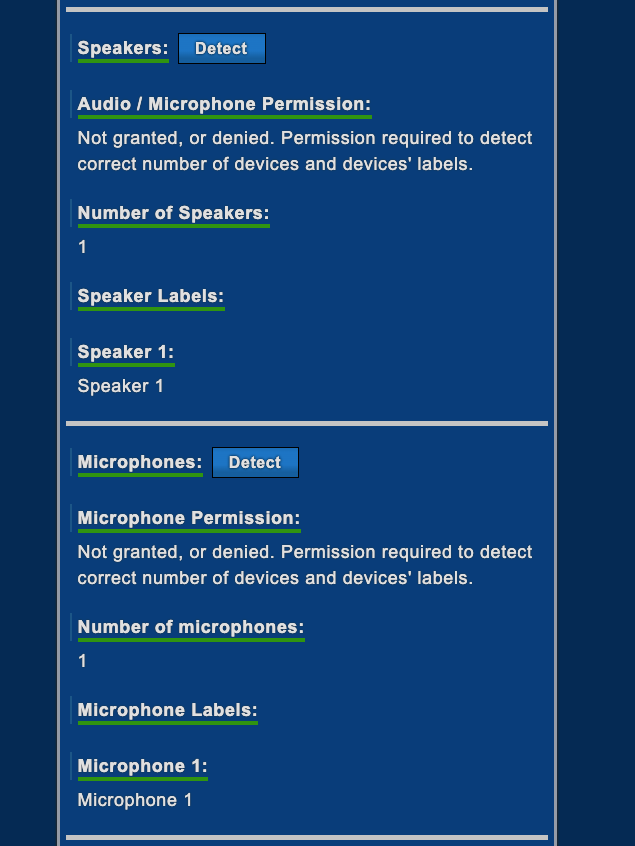
Fingerprinting and privacy concerns
As we mentioned before, fingerprinting techniques are gaining traction not only in the anti-bot industry but also in the marketing one, since more and more people are concerned about cookie usage by websites. Since it’s possible to accept or decline the cookie usage of websites and, since they are stored in the user's device, they can also be deleted, their efficacy for marketing purposes is declining.
But if you’re using a fingerprinting tool in your online marketing solution, maybe you have a less granular detail than the single users’ cookie collection but there’s no way to opt out for them. So you can create very granular clusters of customers, like “people from city X using the latest Mac laptop model, with a second screen, browsing via Chrome v. 113 with Y extension installed, and connecting with ISP Z”. It is such a detailed description that the European think tank about online privacy called Article 29 Data Protection working party, expressed its opinion about fingerprinting and European data protection laws.
To make a long story short: collecting all these pieces of information from the browser to create a unique fingerprint makes the ePrivacy directive applicable to this technology. This implies that visitors of a website, just like what happens for cookies, should be informed if there are any fingerprinting techniques used on the website, unless they are meant only to make the website work correctly.
How to mask your fingerprint
Having a look at the deviceinfo.me website, we can notice the several layers of information gathered to create a fingerprint.
Connection layer
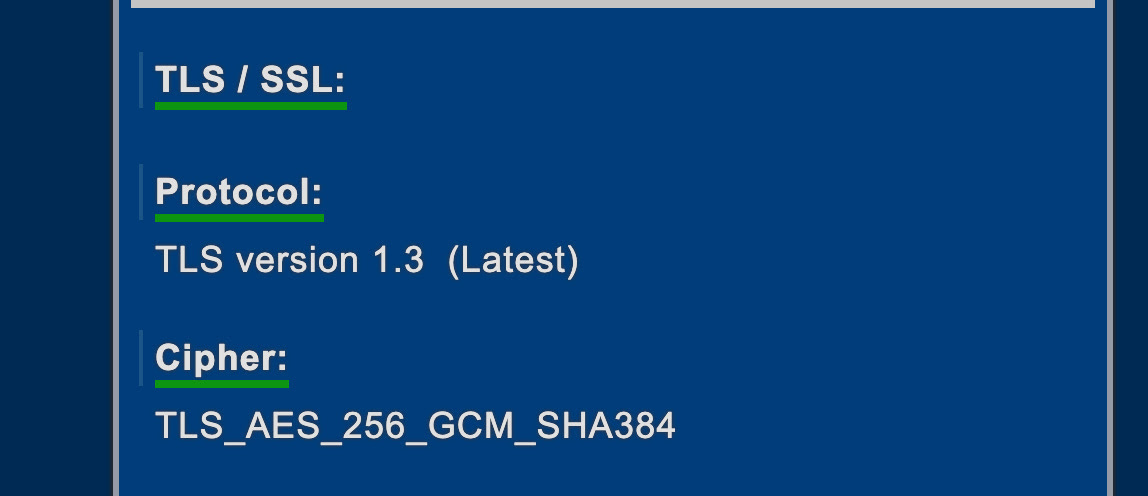
A TLS fingerprint is created using the handshake packets that client and server exchange before establishing an HTTP connection, as seen in our previous article dedicated to TLS fingerprinting. It’s a quite common technique used by major anti-bot provider, as we can see from this Cloudflare article.
To avoid raising red flags when scraping, you can use real browsers with Playwright or Selenium, which will use ciphers not in blacklist, or change ciphers in your Scrapy project’s settings.
Of course, the server knows also the IP address of the device who is connecting and can derive from it several additional info, like your country, state, ISP and so on.
We can change all these details by using a proxy provider and depending from your needs, you can use datacenter, residential or mobile IPs.
Speaking about proxy providers, a bit of self promotion.

Next Wednesday, together with Martin Ganchev (we’ve already met him on these pages), we’ll talk about the web scraping industry, its evolution, and the challenges we as scrapers need to tackle.
I’ll bring in my 10+ years of experience and my opinions so, if you’re curious about that and want to know better who’s writing on these pages, you can subscribe down here.
Thanks to the Smartproxy team and to Martin for inviting me, I think we’ll have fun.
Browser layer fingerprint
Most of the other information used to fingerprint you are coming from your browser settings and how the browser reacts to Canvas and WebGL active fingerprinting.
Typically, if you’re trying to scrape a website protected by a modern anti-bot solution, you cannot use solutions like Scrapy but you’ll need to use a webdriver or a real browser to bypass the protection.
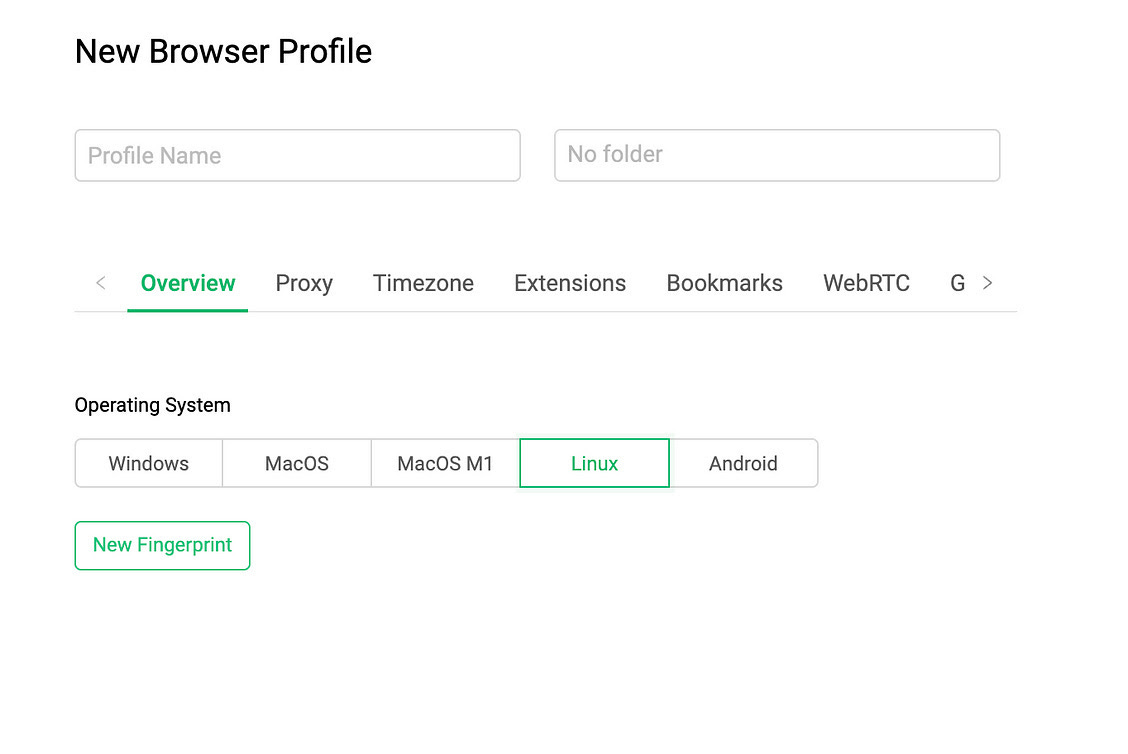
In these cases, providing plausible machine setup with no discrepancies in the settings, is key to create a fingerprint that seems as legit as possible.
As an example, using Playwright and Chrome in headless mode should trigger some red flags, since it’s easy to detect it, as we can see from deviceinfo.me screenshots.


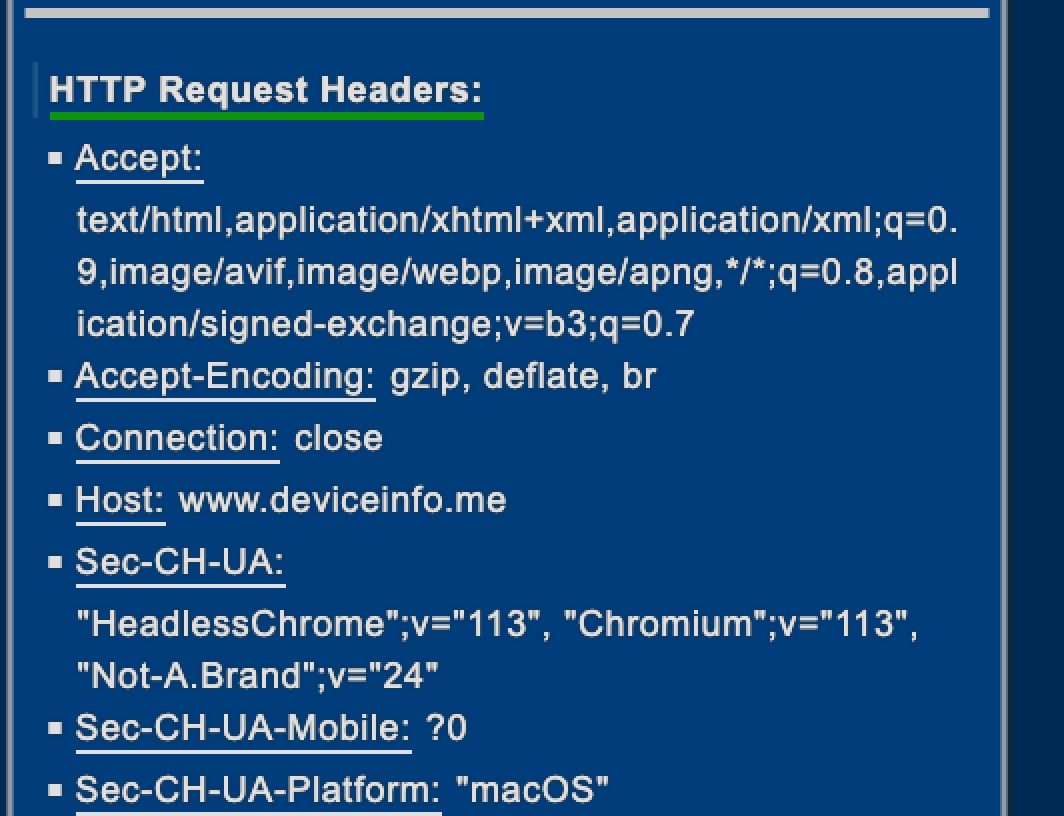
While in headful mode seems perfectly legit, while much more computing intesive.

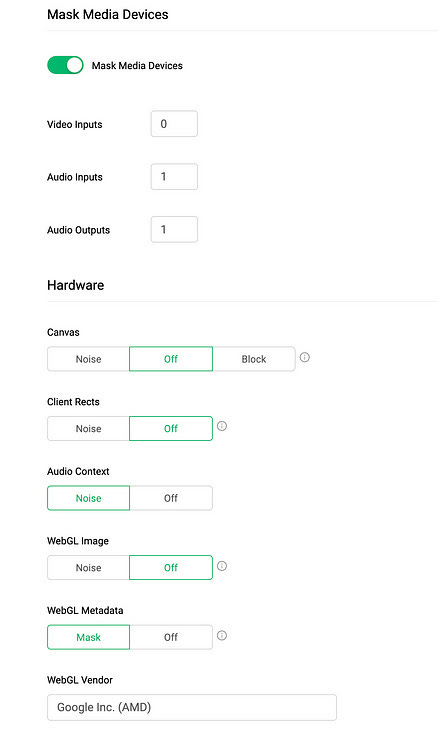
Another example, connections from a server machine won’t show any microphone and camera.
But if you use anti-detect browsers like GoLogin, that allow you to create custom profiles the mimic different hardware and OS setups, you can send more plausible information to the server, creating a more legit fingerprint.
Final remarks
We have seen how many information are transmitted together with a simple browser connection to a website and how they can be used to both track users’ behaviour and detect bots.
While all these fingerprinting techniques can raise some concerns about privacy, especially in countries where these information can be used to limit private freedom, we luckily have several tools in our toolbelt to use to mask our real online traces, and some of them can be used also for our web scraping projects.
In the next post of The Web Scraping Club we’ll make some examples with code, where we’ll mask our device fingerprint to bypass the most common anti-bot solutions.