
The Lab #41: Scrapoxy, the super proxy aggregator
How to use Scrapoxy in your web scraping architecture

We all know that in today’s environment, every web scraping project with a minimum scale needs one or more proxy providers.
While integrating and managing only one proxy provider manually in your scraper it’s not that effort, managing even 2-3 or more, with their different proxy types, starts to create an overhead on your daily tasks that could damage the productivity of your scraping team.
Before going further, just a quick poll.
It’s not only a matter of switching between one provider or another in your scraper: you need to understand better the usage for every provider without jumping from one dashboard to another, compare the success rates, check the geographies covered, and much more.
Sure, (almost) everything could be done from the dashboards on the providers’ page, but it’s starting to become a waste of time when you want to look at how things are going on your projects.
Thanks to Fabien Vauchelles, whom most of you surely know since he’s one of the most prominent figures in the web scraping industry, we have a solution for this headache: Scrapoxy.
What is Scrapoxy?
Scrapoxy is an open-source tool, developed by Fabien, that works like a super proxy aggregator.

It’s like Paypal, but for proxies: while on Paypal we connect multiple payment methods under one account, with Scrapoxy, by using only one account you can connect multiple IP sources, from proxy providers to cloud computing services like AWS, GCP, and Azure, in order to create and manage your IP pool on a single point.
As you can see from the feature list, Scrapoxy is not only a proxy collector but much more:
auto-scales and down-sizes the datacenter proxy infrastructure, so you’re paying nothing more than what you need for your operations
rotates the IPs at given intervals
manages the bans and takes out of the pool the IPs that are not responding properly.
Creates sticky sessions if needed
Surely all these features help to reduce the complexity of the operations in web scraping projects.
A quick walk-through on Scrapoxy
After the installation, via docker or NPM, after the login, we’re asked to create a project to start.
Then we can add from the marketplace catalog the providers we want to connect to, using the specific credentials and instructions for any of them.

Once the credentials are set, you can use them in your connectors, where you configure the rules of their engagement: how many proxies, time-out rules, and auto-scaling and down-sizing rules.

For cloud providers like AWS or Azure, we can create different connectors for different geographical zones, and for each connector, we can specify the maximum number of IPs we want to allocate.
While for proxy providers you just need to set up the right credentials, for cloud providers Scrapoxy handles for you also all the backend configuration needed to be properly working.

It creates the virtual machine image that will be launched in the selected zone and handles all the grants needed to make it run. That’s fantastic! In any case, on the official documentation, for every connector you can find the proper instructions for setting it up.
Scrapoxy integration: an example with Scrapy
After setting up our connectors, we’re ready to use Scrapoxy for scraping, by adding its capabilities to a Scrapy spider.
Again, the documentation helps us and the integration is a piece of cake: we only need to add the following lines to the setting.py file.
DOWNLOADER_MIDDLEWARES = {
'scrapoxy.ProxyDownloaderMiddleware': 100,
}
SPIDER_MIDDLEWARES = {
"scrapoxy.ScaleSpiderMiddleware": 100,
}
SCRAPOXY_WAIT_FOR_SCALE = 120
SCRAPOXY_MASTER = "http://localhost:8888"
SCRAPOXY_API = "http://localhost:8890/api"
SCRAPOXY_USERNAME = "USER"
SCRAPOXY_PASSWORD = "PWD"In this case, I’ve got a docker installation on my laptop and I’ve told to Scrapy, before starting the crawling phase, to wait two minutes to give time for the instances of the proxies to be up and running.
If you wish to try Scrapoxy with a Scrapy spider already configured, you can access the GitHub repository reserved for paying readers.
If you’re one of them but don’t have access to the repo, please write me at pier@thewebscraping.club since I need to add you manually.
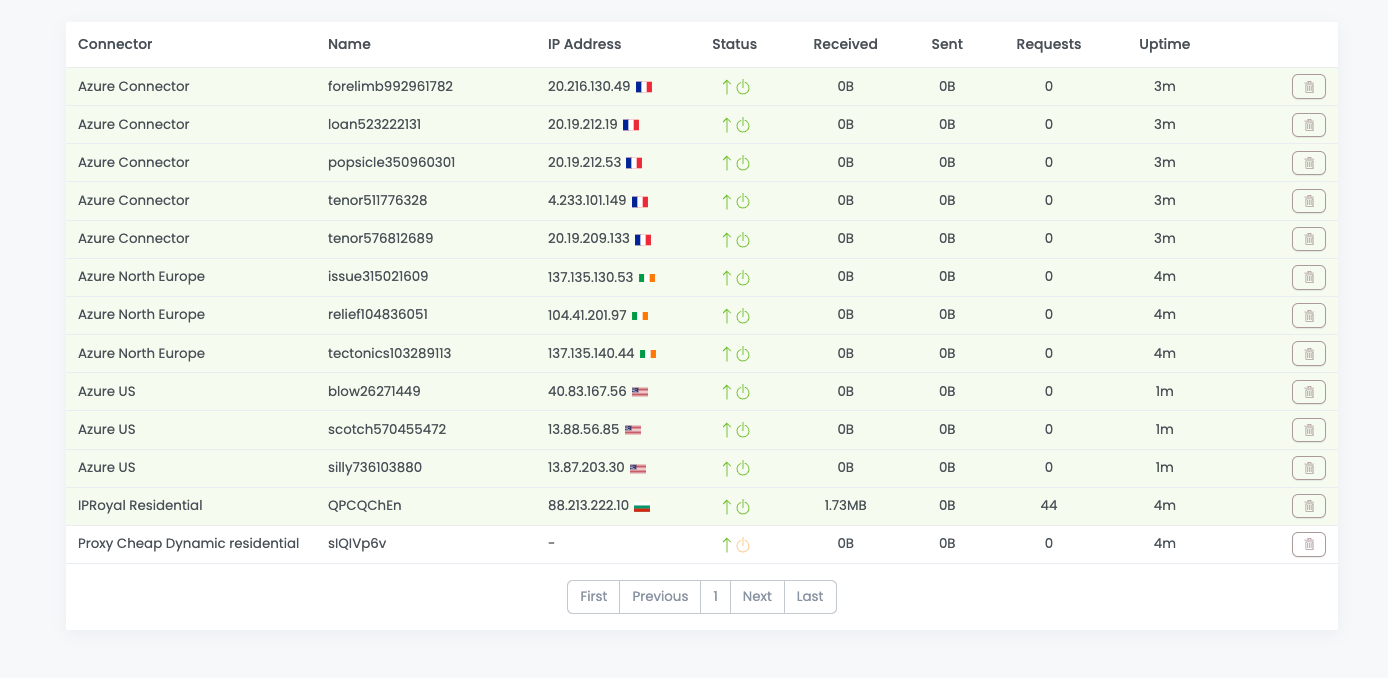
From the Proxies tab, we can see how many IPs are we using and their uptime and we can immediately notice two aspects:
For some reason not depending on Scrapoxy, the USA region of Azure took 4 minutes to be up and running, so it’s better to increase the SCRAPOXY_WAIT_FOR_SCALE delay.
We’re mainly using the IPRoyal residential proxy. The scraper does not return any error so there’s no need to change but I know that the scraper is able to run also on datacenter proxies, so in this case we’re overspending.
Since for the moment this aspect is not handled in Scrapoxy, we can overcome it by taking some wiser architectural choices.
A cost-effective web scraping architecture with Scrapoxy
I know that many of you use the following architecture for your web scraping projects:
Scrapers are deployed to a cluster of virtual machines on cloud providers, so they get a fresh new IP at every run. Then, when they end their executions, VMs are turned off and deleted.
With Scrapoxy, you can deliver and execute the scraper on a single (or a few) but more powerful bare metal machine, and trigger fewer and smaller VMs just to use as a datacenter proxy.
Even better, we can create three different projects inside the Scrapoxy installation, one per type of proxies:
In one, we’ll set up only cloud providers, to get the cheapest datacenter IP possible. All the scrapers, at first instance, will use this project for running.
The scrapers that require residential proxies will be redirected to the second project, where only the residential proxy provider will be configured.
The last project will be used by scrapers that work only with mobile proxies.
If needed, this setup could be duplicated by constraining the providers on a certain geographical zone, in case we need specific IPs from a specific country.
