If you’ve been scraping for a while, you know the sensation that comes from a scraper that breaks. Yesterday everything was running smoothly, today the scraper it’s broken. So, you check the code and the website's HTML structure, and here it is: a class has been renamed.
While you’re wondering why they renamed that class, you have nothing else to do than adapt your code and rerun the scraper.
Especially when scrapers are complex, chances are that you’ve asked yourself if there were any other paths you could pursue when scraping rather than being too tight to selectors. And I’m sure you’ve also asked yourself if LLMs can help you with that and replace traditional scrapers.
In this article, you’ll explore some of the possibilities that LLMs can offer when scraping websites to rely less on selectors.
Ready? Let’s dive into it!
Before proceeding, let me thank NetNut, the platinum partner of the month. They have prepared a juicy offer for you: up to 1 TB of web unblocker for free.
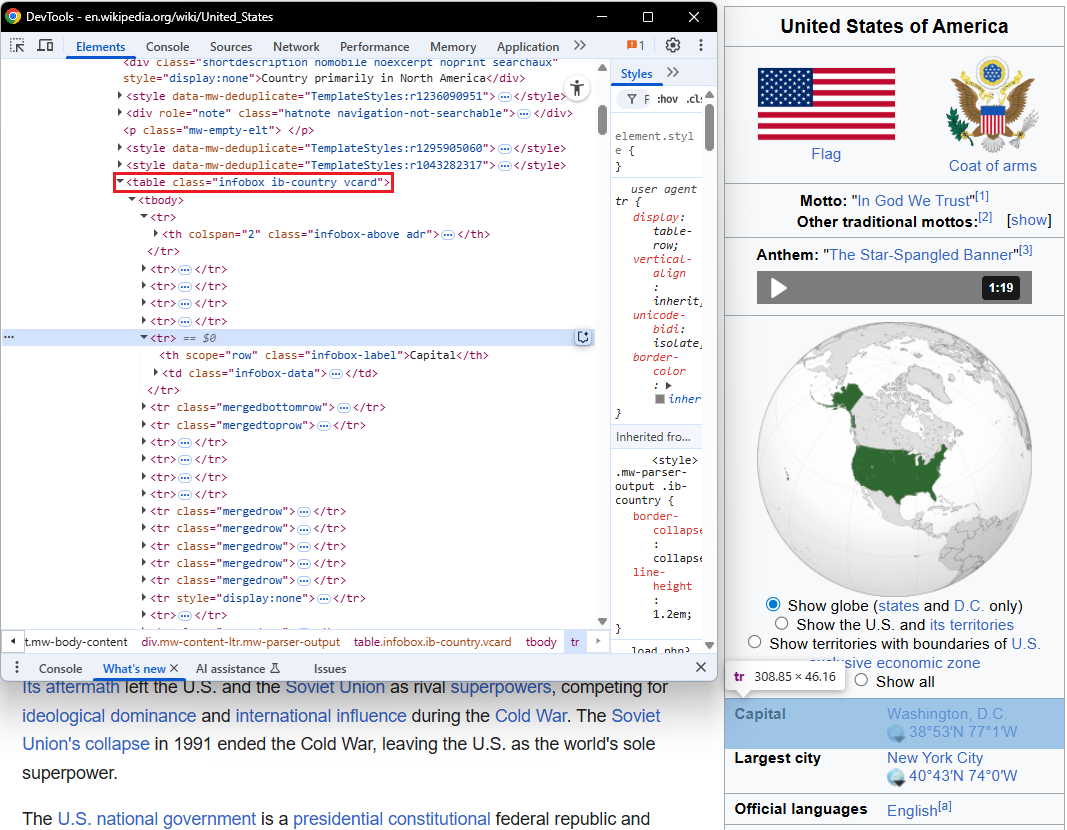
As the image shows, the table reporting some data about the US has a nested structure, which is hard to scrape. In such cases, it’s difficult to just point to the whole table—<table class=”infobox ib-country vcard”>—to extract all the selectors in a simple way. You’d need to point to all the selectors of the data you need to scrape, developing a complex logic.
Also, no one guarantees the names of the various classes will remain the same forever. In other words, there are generally the following orders of problems:
Pages with nested and “difficult” structure.
Names that can change.
HTML structures that can change.
The problem to solve is to rely as little as possible on the HTML structure. This way, you could develop robust and reliable scrapers. The main idea is to point only to those parts of the HTML that you suppose won’t change in the future, and use other solutions other than relying only on the classical scraping solutions.
Let’s see the possibilities you can use.
This episode is brought to you by our Gold Partners. Be sure to have a look at the Club Deals page to discover their generous offers available for the TWSC readers.
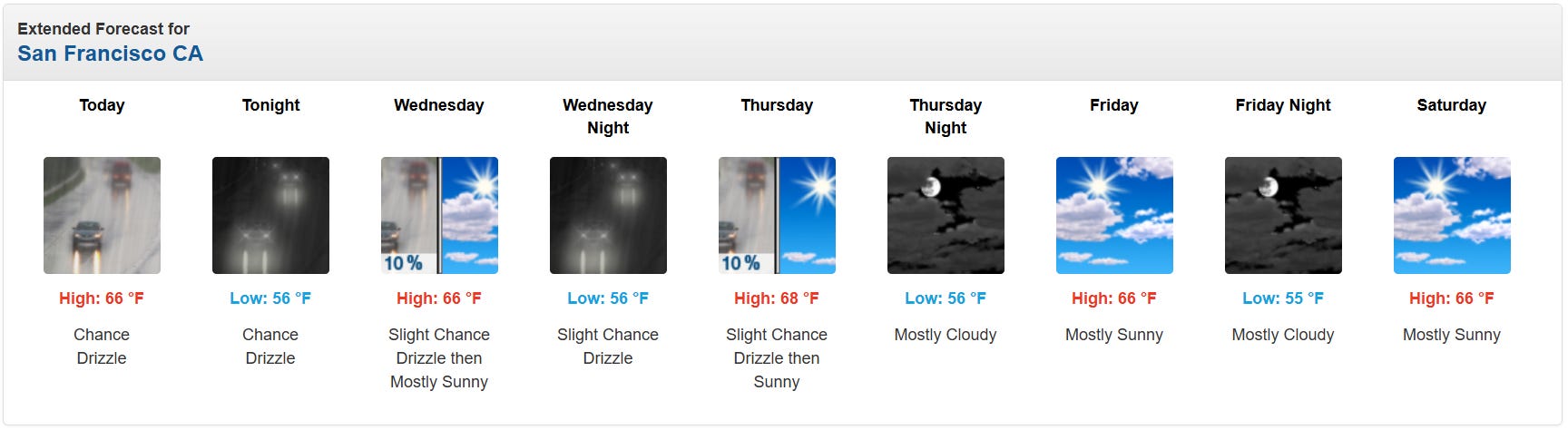
To frame the thesis, you’ll compare different methodologies on the same web page. For this example, I decided to use a target webpage that shows the weather forecast in San Francisco. The scrapers will extract the data from the part of the target page shown in the image below:
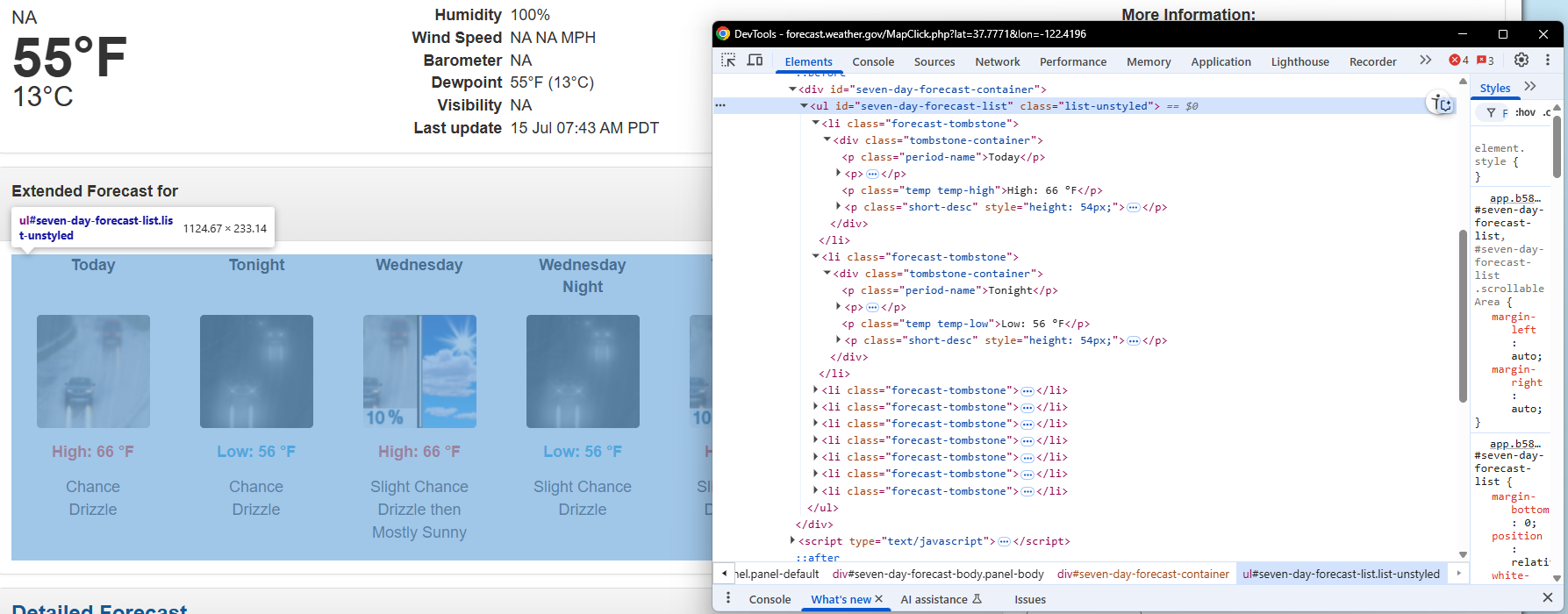
Using Chrome devtools, you can see that this part has a somewhat nested structure:
The goal is to stick only to the seven-day-forecast-list selector as much as possible, as you can suppose it will not change in the future. Then, extract all the other data:
Day of the week.
Temperature.
Overall forecast (a short description of the forecast for the day).
You’ll do so using Python with the traditional scraping method and using alternative methods based on LLMs.
Great! You are now fully set up, and you can start scraping.
Before continuing with the article, I wanted to let you know that I've started my community in Circle. It’s a place where we can share our experiences and knowledge, and it’s included in your subscription. Enter the TWSC community at this link.
To scrape the target webpage with the traditional method, you can use the following code:
import requests
from bs4 import BeautifulSoup
import csv
# Define data
URL = "https://forecast.weather.gov/MapClick.php?lat=37.7771&lon=-122.4196"
CSV_FILENAME = "extended_forecast.csv"
# Get response
response = requests.get(URL)
response.raise_for_status()
# Parse HTML
soup = BeautifulSoup(response.content, "html.parser")
# Isolate the container for the extended forecast list
forecast_list_container = soup.select_one("#seven-day-forecast-list")
# Find all individual forecast items within that container
forecast_items = forecast_list_container.select("li.forecast-tombstone")
extracted_data = []
# Loop through each forecast and extract the data
for forecast in forecast_items:
period_name = forecast.select_one("p.period-name")
temperature = forecast.select_one("p.temp")
short_desc = forecast.select_one("p.short-desc")
extracted_data.append({
"Upcoming forecast": period_name.get_text(strip=True) if period_name else "",
"Temperature": temperature.get_text(strip=True) if temperature else "",
"Overall": short_desc.get_text(strip=True) if short_desc else ""
})
# Write the data to a CSV file
headers = ["Upcoming forecast", "Temperature", "Overall"]
with open(CSV_FILENAME, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=headers)
writer.writeheader()
writer.writerows(extracted_data)
print(f"\n--- Success! ---")
print(f"Results have been saved to '{CSV_FILENAME}'")
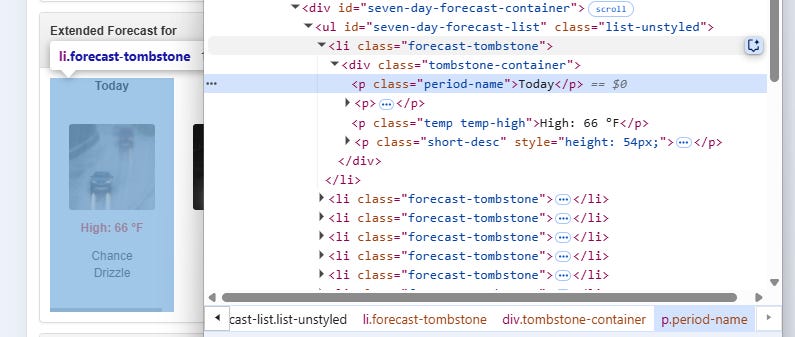
In this case, you have to identify all the selectors that point to the data for each day, and iterate over a for loop. The Chrome devtools can help you visualize the selectors:
This is exactly what you want to try to avoid with alternative methods, because you can suppose:
The names of the classes could change. For example, one day, developers can decide to use a more descriptive name than forecast-tombstone.
The structure under **the seven-day-forecast-list could change.
To run the script, type:
python traditional_scraper.py
The CLI will print a success message:
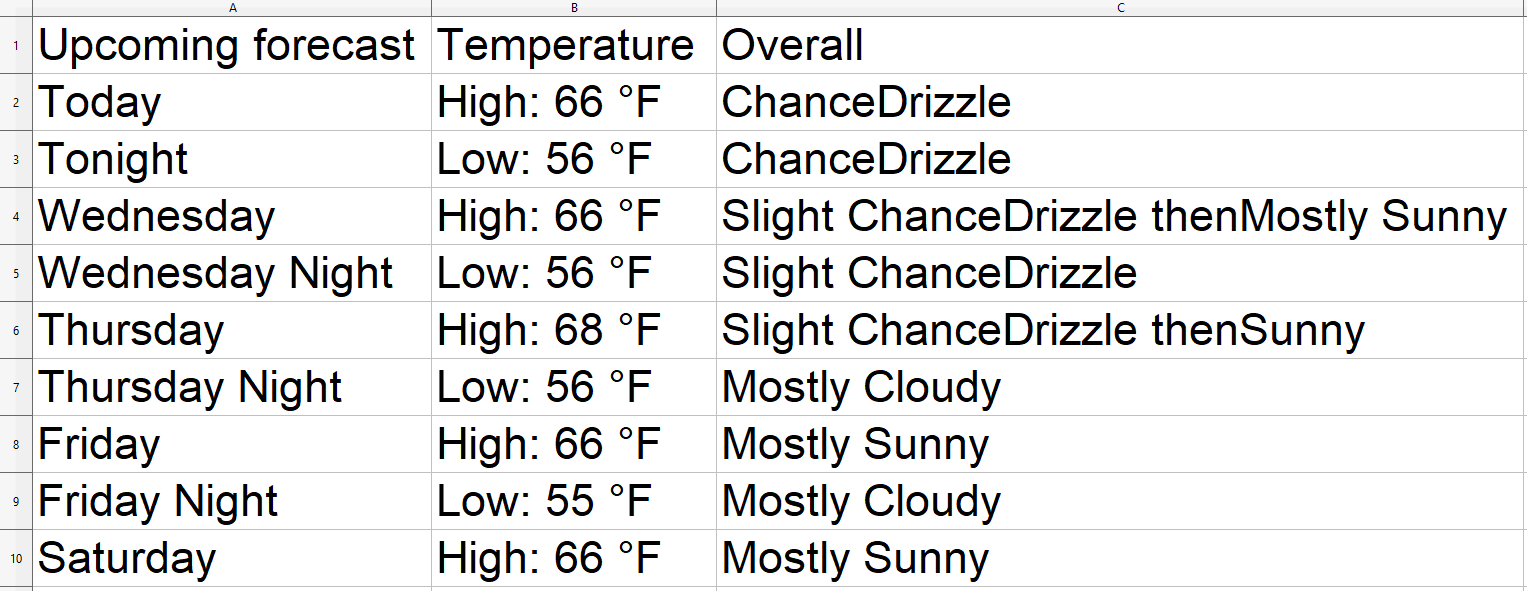
The data is saved in the CSV file. The image below shows the result:
As you can see from the above image, this approach has another downside: some words under the Overall column are stuck together in a unique word. Fixing this requires data cleaning.
Very well. You have scraped the target webpage with the classical method. Now, let’s proceed with the alternative methods using LLMs.
Method 2: Schema-Driven Extraction with Pydantic and GPT
As a first alternative method, let’s use an approach based on Pydantic and OpenAI’s GPT. Pydantic is a library for data validation and settings management using Python type annotations. It allows you to define data models (classes) that specify the expected structure, types, and constraints of your data. You can use it to parse or validate data, and it:
Checks that the data matches your model.
Automatically converts types or raises errors if the data is invalid.
Below is the code:
import requests
from bs4 import BeautifulSoup
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
class ForecastItem(BaseModel):
# Represents a single forecast period
upcoming_forecast: str = Field(..., alias="Upcoming forecast", description="The name of the forecast period, e.g., 'Tonight'.")
temperature: str = Field(..., alias="Temperature", description="The full temperature string, e.g., 'Low: 54 °F'.")
overall: str = Field(..., alias="Overall", description="The short, overall description of the weather, e.g., 'Partly Cloudy'.")
class ExtendedForecast(BaseModel):
# Container for all forecast items
forecasts: List[ForecastItem]
# Configuration
URL = "https://forecast.weather.gov/MapClick.php?lat=37.7771&lon=-122.4196"
CSV_FILENAME = "extended_forecast_gpt.csv"
print("--- Running LLM-Powered Scraper for Extended Forecast ---")
# Get response
response = requests.get(URL)
response.raise_for_status()
# Parse the HTML and Extract the Forecast Section
soup = BeautifulSoup(response.content, "html.parser")
forecast_container = soup.select_one("#seven-day-forecast-list")
# Convert the relevant HTML section to a string for the LLM
html_content = str(forecast_container)
# Initialize the OpenAI client
client = OpenAI(api_key="YOUR_API_KEY") # Insert your API key here
# Get the JSON schema from the Pydantic model to guide the LLM
schema = ExtendedForecast.model_json_schema()
# Compose the prompt for the LLM
prompt = f"""
You are an expert data extraction system. From the provided HTML content of a weather forecast,
extract all the forecast periods.
Format the extracted data into a JSON object that strictly conforms to the following JSON Schema.
Ensure you extract every single forecast period present in the HTML.
JSON Schema:
{schema}
HTML Content to parse:
{html_content}
"""
# Call the LLM to Extract Data
print("Sending request to GPT-4o for data extraction...")
api_response = client.chat.completions.create(
model="gpt-4o",
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": "You are an expert data extraction bot that returns JSON matching a provided schema."},
{"role": "user", "content": prompt}
]
)
json_response_str = api_response.choices[0].message.content
print("Received response from API.")
# Validate and Parse the LLM Output
print("Validating data with Pydantic...")
weather_data = ExtendedForecast.model_validate_json(json_response_str)
# Convert the list of Pydantic objects to a list of dictionaries for CSV
data_to_save = [item.model_dump(by_alias=True) for item in weather_data.forecasts]
# Write the data to a CSV File
headers = ["Upcoming forecast", "Temperature", "Overall"]
with open(CSV_FILENAME, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=headers)
writer.writeheader()
writer.writerows(data_to_save)
print(f"\n--- Success! ---")
print(f"Results have been saved to '{CSV_FILENAME}'")
This code:
Defines two Pydantic models: ForecastItem and ExtendedForecast:
ForecastItem describes a single forecast period, specifying the expected fields (upcoming_forecast, temperature, overall), their types, and human-readable descriptions.
ExtendedForecast is a container for a list of ForecastItem objects, representing the entire extended forecast.
Uses the model_json_schema() method to generate a JSON Schema from the Pydantic model. This schema is provided to the LLM (GPT-4o) to guide its output format.
Imposes a precise prompt that tells the LLM:
How it should act → “You are an expert data extraction system […]”.
What it should do → “Format the extracted data into a JSON object that […]”.
The schema to follow and the HTML to ingest.
After the LLM returns its response, it uses the method model_validate_json() to validate and parse the LLM’s output. This ensures it matches the expected structure before saving to CSV.
This approach is better than the traditional one. With Pydantic, you define exactly what your data should look like. The previous approach (using only BeautifulSoup) extracted data directly from HTML and assumed the structure was always correct. This can break the program if the HTML changes. Instead, with this alternative approach, if the website’s HTML changes, the LLM can still extract the correct data—as long as the content is still present.
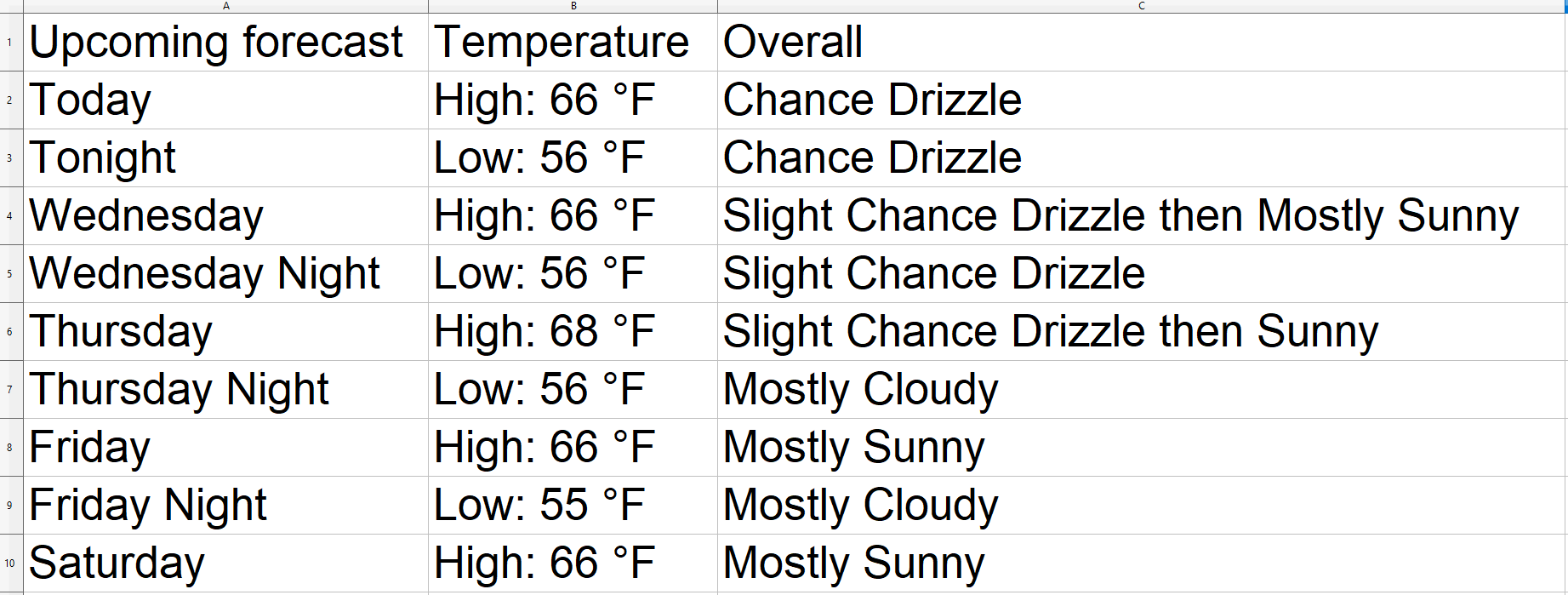
As you can see, the data is correctly extracted and saved. Also, in this case, the Overall column has no words stuck together in a unique word. So, you coded a more robust scraper and avoided a data cleaning process.
Now, let’s see another alternative method.
Method 3: Visual Extraction with Selenium and GPT-Vision
Another interesting alternative method is creating a screenshot of the target page and cropping it around the zone where the data is located—if you are not interested in extracting all the data from a webpage, as in this case.
To do so, you can use the following code:
import time
import base64
import json
import csv
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from PIL import Image
from openai import OpenAI
# Configuration
URL = "https://forecast.weather.gov/MapClick.php?lat=37.7771&lon=-122.4196"
SCREENSHOT_PATH = "forecast_section.png"
CSV_FILENAME = "forecast_extracted.csv"
API_KEY = "YOUR_API_KEY" # Replace with your OpenAI API key
# Capture the forecast section with Selenium
options = Options()
options.add_argument("--headless")
options.add_argument("--window-size=1920,1080")
driver = webdriver.Chrome(options=options)
driver.get(URL)
time.sleep(2)
# Locate the forecast section
forecast_element = driver.find_element(By.CSS_SELECTOR, "#seven-day-forecast-list")
location = forecast_element.location
size = forecast_element.size
# Take full page screenshot
driver.save_screenshot("full_page.png")
driver.quit()
# Crop the forecast section with PIL
image = Image.open("full_page.png")
left = location['x']
top = location['y']
right = left + size['width']
bottom = top + size['height']
forecast_image = image.crop((left, top, right, bottom))
forecast_image.save(SCREENSHOT_PATH)
# Encode the image for OpenAI Vision
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as img_file:
return base64.b64encode(img_file.read()).decode("utf-8")
image_b64 = encode_image(SCREENSHOT_PATH)
# Send to GPT-4o for data extraction
client = OpenAI(api_key=API_KEY)
prompt = (
"You are an expert data extraction system. "
"From the provided screenshot of a weather forecast, "
"extract all the forecast periods, their temperature, and a short weather description. "
"Return the data as a JSON array with the following fields for each period: "
"'period', 'temperature', and 'description'."
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{image_b64}",
"detail": "high"
},
},
],
}
],
max_tokens=600,
)
# Parse the JSON response and save to CSV
json_str = response.choices[0].message.content.strip()
start = json_str.find('[')
end = json_str.rfind(']')
if start != -1 and end != -1:
json_str = json_str[start:end+1]
data = json.loads(json_str)
headers = ["Upcoming forecast", "Temperature", "Overall"]
with open(CSV_FILENAME, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=headers)
writer.writeheader()
for row in data:
writer.writerow(row)
print(f"\n--- Success! ---")
print(f"Results have been saved to '{CSV_FILENAME}'")
In this case, to take the screenshot, you have to use a browser automation tool like Selenium. So, this code:
Launches Selenium in headless mode.
The options.add_argument("--window-size=1920,1080") method ensures that the browser renders the page at a consistent, large resolution. This is important because the layout and visibility of page elements can change depending on the window size. A larger window size ensures that the entire content you want to capture is visible and not collapsed, hidden, or rendered differently.
The method find_element(By.CSS_SELECTOR, "#seven-day-forecast-list") locates the specific HTML element containing the forecast section we want to crop from the whole image. To crop it, the code uses the (x, y) coordinates of the top-left corner of the element relative to the page—left = location['x'] and top = location['y'].
Encodes the image using the library base64. This makes the image readable to the LLM.
So, this code:
Opens a Selenium-based web instance.
Takes a screenshot of the whole page, and saves it locally.
Crops the image, locating the zone that reports the data you are interested in, and saves it locally.
Analyzes the image and extracts the data from it.
Saves the extracted data into a CSV file.
To run this code, write:
python image_scraper.py
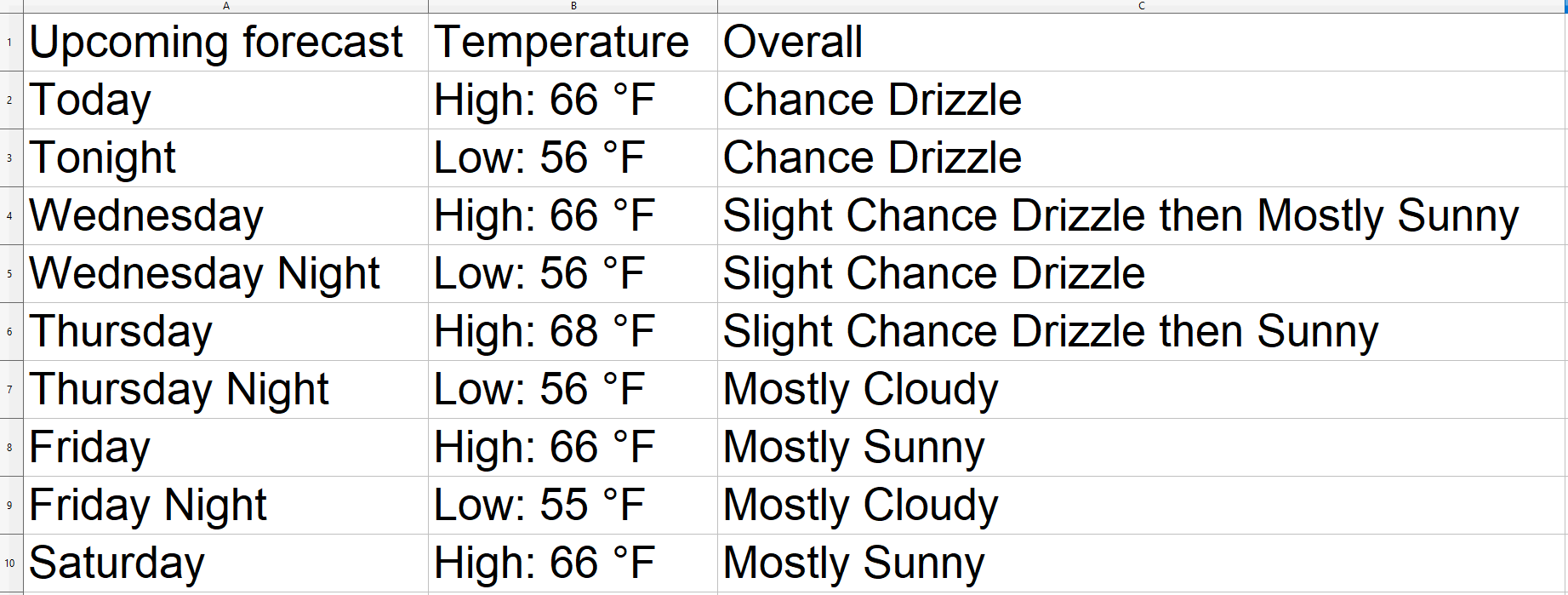
The result is:
There you go! You scraped the data using GPT Vision. Also, even in this case, the Overall column has no words stuck together in a unique word.
A Word of Caution: The Hidden Costs of AI
As with every technological solution, the AI-powered scraping approaches have some downsides, such as:
Cost and token optimization: The AI-powered approaches come with associated costs for each API request. So, before going directly into the code, compare the OpenAI API pricing model to estimate the price you will pay. Also, try to optimize your code so that you only extract the content you need. This can complicate your code, but surely help you save money on API calls.
Error handling and hallucinations: LLMs might occasionally miss fields or invent data. This is an actual problem when working with LLMs, regardless of the applications you are using them for. To solve this, Pydantic is a good line of defense as you can use its validators to enforce constraints. However, an LLM can still stick to Pydantic’s constraints, but hallucinate data. In this case, human validation in the first iterations is fundamental to be sure the LLM do not invent data. In case the LLM hallucinates data, you have to debug your code, try different prompts, and you may also need to try a different LLM to see if anything changes.
Scalability and associated costs: Scaling up scraping projects with AI-powered scraping approaches is totally feasible on the side of code structure and architecture. However, in those cases, associated costs skyrocket. So, if you need to scale, estimating the costs before starting to code becomes a must.
The Web Scraping Club is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Conclusion
In this article, you’ve learned two scraping approaches based on LLMs. The point of using those methodologies is to rely as little as possible on the HTML structure so that you can stick to the parts that you suppose will not change over time.
However, as with every technology and technique, they are not without downsides. So you have to evaluate your specific case and see if they can be of real benefit for you.
Finally, while this tutorial is coded from scratch, there are commercially-available solutions that help you integrate LLMs into your scraping workflow, which allow you to obtain structured data from unstructured. Two interesting ones to try are ScrapeGraphAI and Firecrawl.
So let us know: are you using different scraping approaches based on LLMs? Let’s discuss this in the comments!