
Scraping Historical Data From the Wayback Machine
How to programmatically retrieve historical internet data from the Wayback Machine

To properly train an unbiased AI model, you should use not only fresh, up-to-date data but also historically valid data. That’s why, in recent months, there’s been a growing trend toward targeting high-quality historical datasets.
And what better source for historical web data than the Wayback Machine—a massive archive of the Internet that lets you view past versions of web pages, complete with their original content and layout?
And what better approach to retrieve that data than web scraping? Here, I’ll show you how to scrape the Wayback Machine using Python to collect historical data for data analysis, AI training, or any other purpose.
Before proceeding, let me thank NetNut, the platinum partner of the month. They have prepared a juicy offer for you: up to 1 TB of web unblocker for free.
Introduction to Scraping the Wayback Machine
Before jumping into the code, it makes sense to take a step back and understand what the Wayback Machine is, how it works, what kind of data it contains, why and when it’s a great target for web scraping, and so on...
What Is the Wayback Machine?

As the Wayback Machine site clearly puts it:
“The Wayback Machine is an initiative of the Internet Archive, a 501(c)(3) non-profit, building a digital library of Internet sites and other cultural artifacts in digital form.”
In other words, the Wayback Machine is a digital archive of the World Wide Web, created and maintained by the Internet Archive (which you might better know as archive.org). The goal of the project is to preserve and provide access to the history of the Internet.
It allows you to "go back in time" and see how websites looked in the past. Basically, it contains snapshots of over 928 billion web pages saved over time (yes, you read that right, almost one trillion pages!)
Note that the Wayback Machine doesn’t just archive a specific web page once. Quite the opposite, it often provides access up to hundreds of thousands of snapshots, including multiple versions of the same page over the same day:

Thanks to the gold partners of the month: Smartproxy, IPRoyal, Oxylabs, Massive, Rayobyte, Scrapeless, SOAX, ScraperAPI, and Syphoon. They’re offering great deals to the community. Have a look yourself.
Why Is the Wayback Machine a Great Source of Historical Data?
Many internet users mistakenly believe that Google indexes every single page on the Web. That’s simply not the case…
As I’ve learned firsthand while working on a project involving dozens of millions of pages, you can’t expect Google—or any other search engine—to fully crawl and index such a massive website. Attempting to do so can even backfire, potentially resulting in SEO penalties. That’s why it’s best practice to guide search engines toward only the most valuable pages for your users.
Some websites achieve that by setting the appropriate SEO directives (like noindex or canonical) to prevent certain pages from being crawled. Others end up deleting or archiving thousands of pages over time. That poses a serious problem for the preservation of digital history, as the SEO teams (and marketing in general) tend to prioritize fresh, frequently updated content!
Thus, the way search engines are designed often leads to the devaluation or even permanent deletion of historical content. That’s where a project like the Wayback Machine becomes incredibly precious—serving as an independent archive to preserve snapshots of the Web that might otherwise be lost.

Unlike search engines, the Wayback Machine doesn’t follow SEO, marketing, or business rules. It operates as a kind of "time capsule," offering access to content that’s no longer live, has been deleted, or has changed over time.
When Is Scraping the Wayback Machine Useful?
Now, back to what you’ve probably been waiting for: web scraping. Why is scraping data from the Wayback Machine such a great opportunity? Let me break it down for you in four key points:
A unique source to study the evolution of web content: Track how the content of a specific web page (or site) has changed over time. For example, that's the approach followed by Pierluigi Vinciguerra—the founder of this project—to analyze how car prices evolved over the years.

Recover lost or deleted content: Retrieve blog posts, articles, product listings, or entire web pages that have been removed, hidden, or are no longer online.
Bypass modern anti-bot defenses: Skip the hassle of CAPTCHAs, IP bans, rate limiters, or simply JavaScript-dependant pages. These technologies may not have even existed or weren't widely used when the pages were originally archived. After all, the Wayback Machine crawler could access those pages in the first place…
Easier scraping process: Most archived pages are static HTML, making them far easier to parse and extract data from. Actually, the Wayback Machine is a great place to start learning web scraping or to sharpen your skills.
How to Scrape the Wayback Machine in Python
Now, suppose you're a sports analyst—or simply an NBA enthusiast—interested in studying how expert predictions stacked up against actual NBA draft selections. You want to compare the prospects highlighted by trusted journalists with the players who were ultimately picked.
If you try to go back several years to get draft prospect data and analysis, you'll quickly realize it's no easy task, as the original web pages no longer exist. That’s where the Wayback Machine can help!
Visit the Wayback Machine in your browser, search for “espn.com,” select a past year like 2004, and choose one of the available snapshots:

You’ll be redirected to a snapshot of ESPN’s site from that era:

(Yeah, viewing these old-school web pages really feels like stepping into a time machine!)
Now, try not to get too nostalgic about the early 2000s internet. Navigate to the NBA section by opening the main news or navigation links. From there, you’ll find the “2004 NBA Draft Top 10s” article:

This article lists the top 10 draft prospects as selected by NBA Insider and expert Chad Ford, broken down into the following categories:
TOP 10 POINT GUARDS
TOP 10 SHOOTING GUARDS
TOP 10 SMALL FORWARDS
TOP 10 POWER FORWARDS
TOP 10 CENTERS
That news page will serve as the target URL for your Wayback Machine scraper.
Follow me as I show you how to perform web scraping on the Wayback Machine in Python!
Implement the Scraping Logic
First, take a look at the URL of the target page in your browser’s navigation bar:
https://web.archive.org/web/20040603144435/http://insider.espn.go.com/insider/story?id=1774429That’s a standard format for Wayback Machine URLs, which always follow this pattern:
https://web.archive.org/web/><snapshot_date_and_time>/<original_page_url>As you can imagine, a web page from 2004 would be fully static—meaning you only need a basic HTTP client and an HTML parser to scrape it. No browser automation required.
In particular, you can use Requests and Beautiful Soup to get the HTML content of the page and parse it:
# pip install requests beautifulsoup4
import requests
from bs4 import BeautifulSoup
# Wayback Machine snapshot URL
url = "https://web.archive.org/web/20040603144435/http://insider.espn.go.com/insider/story?id=1774429"
# Send GET request
response = requests.get(url)
# Parse HTML content
soup = BeautifulSoup(response.text, "html.parser")Next, inspect one of the five tables containing the data of interest:

Each table can be selected using the “a[name] > table” CSS selector. They all follow the same structure, so the scraping logic can be applied iteratively:
for table_element in soup.select("a[name] > table"):
# Scraping logic...Specifically, from each table, you'll extract:
Category: The title of the table from the header row (e.g., "TOP 10 POINT GUARDS").
Players: The list of player entries in each row of the table.
To scrape the data from each row, skip the first two rows (which contain the title and headers), then target the columns positionally. Here's the typical layout:
Column 1: Player rank according to the journalist
Column 2: Full player name
Column 3: Height, weight, and age of the prospect
Column 4: School or country the prospect comes from
Tip: Web pages in the early days of teh Internet often displayed data in simple, unstyled HTML tables. In most cases, you’ll need to extract data based on the position of the columns, since you typically can’t rely on CSS selectors tied to specific cells.
Extract the text from the columns in each row as follows:
row_elements = table_element.select("tr")[2:] # Skip title and header rows
for row_element in row_elements:
col_elements = row_element.select("td")
if len(col_elements) == 4:
rank = col_elements[0].get_text(strip=True).rstrip(".")
name = col_elements[1].get_text(strip=True)
hwage = col_elements[2].get_text(strip=True)
school_country = col_elements[3].get_text(strip=True)To split the hwage string into height, weight, and age info, you can use a regular expression:
match = re.match(r"(?P<height>\d+-\d+)/(?P<weight>\d+)\s*lbs\s*-\s*(?P<age>\d+)\s*yrs", hwage)
if match:
height = match.group("height")
weight = match.group("weight")
age = match.group("age")
else:
# Fallback in case the format is unexpected
height = None
weight = None
age = NoneNote: Older websites like this one were often designed for very narrow screen widths, as you can notice from the layout of the 2004 version of the ESPN site. That led to condensed data formatting. This is why fields like height, weight, and age are crammed into one cell. In these scenarios, a regex can definitely help untangle aggregated data.
That’s it! The Wayback Machine scraping logic is now complete. All that’s left is to collect the data and get ready to export or analyze it. You can find the full logic of the Python script on the GitHub Repository for free subscribers, under the folder WaybackMachine.
Now, if you clone the repo, run the script, and print the scraped data, you’ll get something like:
[
{
"category": "TOP 10 POINT GUARDS",
"players": [
{
"rank": 1,
"name": "Shaun Livingston",
"height": "6-7",
"weight": "175",
"age": "18",
"school_country": "Peoria (IL)"
},
{
"rank": 2,
"name": "Devin Harris",
"height": "6-3",
"weight": "185",
"age": "21",
"school_country": "Wisconsin"
},
// Omitted for brevity...
]
},
{
"category": "TOP 10 SHOOTING GUARDS",
"players": [
// Omitted for brevity...
]
},
// Omitted for brevity...
]Amazing! For a complete analysis, you could compare the scraped data with the actual NBA players drafted in 2024 to see how accurate these early scouting predictions were:
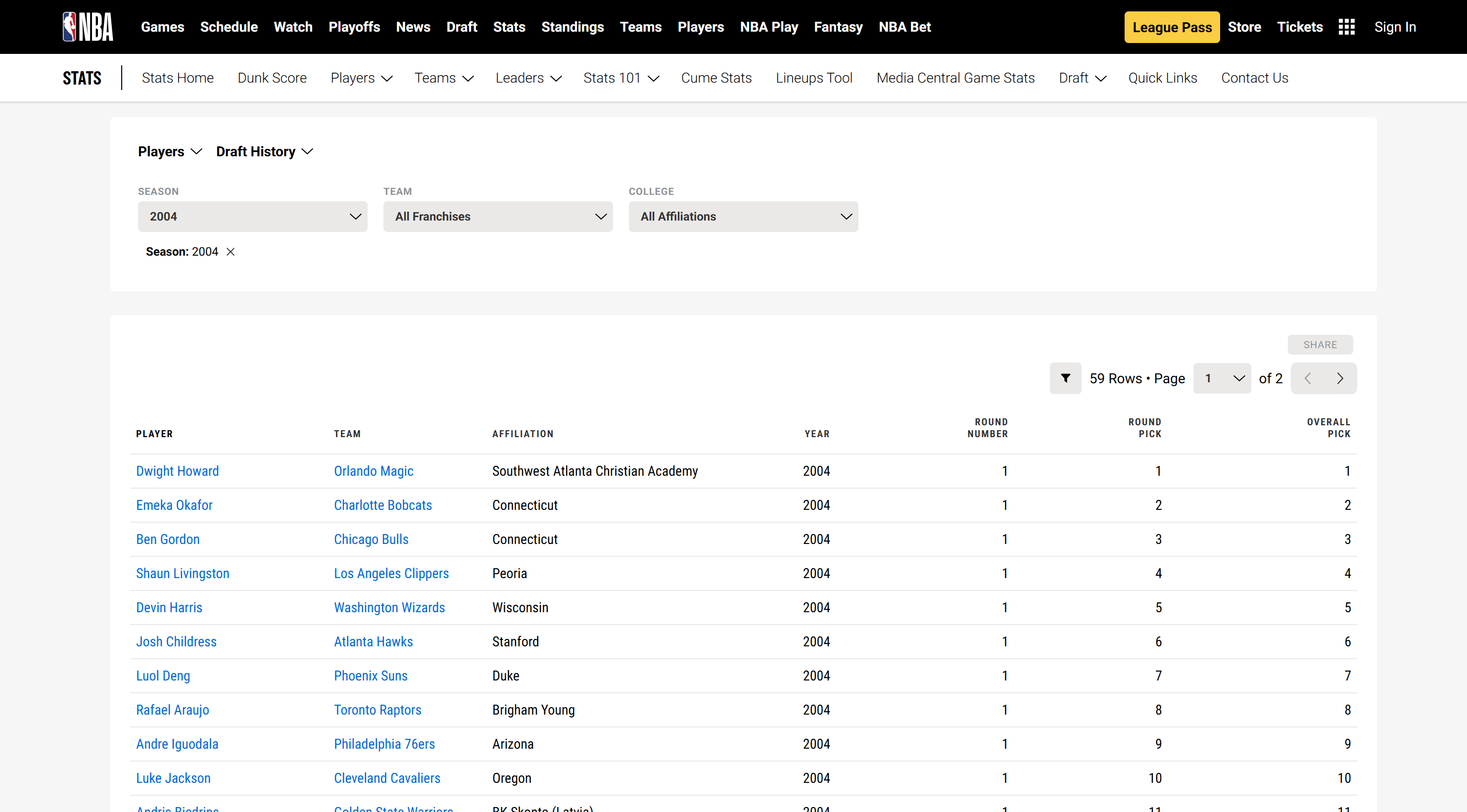
Now, as you must already know, the parsing logic to extract the desired data from a webpage must be tailored to the specific structure of that page. In regular web scraping, this structure varies from site to site. When targeting the Wayback Machine, it also depends on the temporal version of the page you're accessing.
That’s because websites often change their layout and HTML structure over time. So, a page from 2004 might look entirely different from the same page in 2005. As a result, your scraping logic may need to be adjusted for each snapshot.
If you're trying to scrape data from the same page across different points in time using the Wayback Machine (e.g., to study the temporal evolution of the data), I recommend building an AI-powered parser. This approach helps you avoid manually rewriting the parsing logic for each version of the page.
Conclusion
The goal of this article is to demonstrate how the Wayback Machine can be used as an Internet archive to let your web scraper go back in time. By accessing different snapshots of the same web pages over the years, you can extract data and analyze how it’s evolved over time. That means gaining access to original, historical data that may no longer be available or easy to retrieve. What an invaluable resource for data analysis or training ML/AI models!
All the code provided is for educational purposes only. Please use it responsibly and avoid overwhelming the Wayback Machine—a nonprofit project—with excessive requests.
I hope you enjoyed this journey into the past. Feel free to share your thoughts on the topic in the comments section—and until next time!
Fascinating read! The Wayback Machine is such a goldmine for training AI models—crazy to think it’s sitting on nearly a trillion snapshots. Python scraping sounds like the perfect tool to unlock that historical data. Appreciate the breakdown!
Cool article, my research also shows that LLMs do use historical data such as the Common Crawl (18 years of web data crawl including 250 billion pages). See video about it here: https://youtu.be/yJZ6fphntk0?si=ONjmjouLBiYshrMO (relevant part starts at 17:30).
Also, thanks to the Wayback Machine, it's possible to verify claims about who was first in the anti-detect browser market. While some competitors often state they were the first, snapshots show that Kameleo predates others. For example, Kameleo has a snapshot from May 16, 2018, while Multilogin's first snapshot is from June 30, 2018.
See the snapshots here:
Kameleo: https://web.archive.org/web/20180516040648/https://kameleo.io/
Multilogin: https://web.archive.org/web/20180730184538/https://multilogin.com/
But let’s leave the past behind and look at the present: both companies have achieved great success. What I'd like to highlight is that Kameleo was the first to pivot in the anti-detect browser space to make web scraping users its primary target audience. As a result, we focus on features that enable scaled-up, on-premise web scraping.