
Web Scraping from 0 to hero: data cleaning processes
And where to perform it: inside your scraper or in your database?

In the latest post of this course “Web Scraping from 0 to Hero” we extracted some data from the HTML code of websites using selectors, doing a quick benchmark between XPATH and CSS.

Once we extracted the text we needed from the HTML, the task of getting usable data was still not over.
Just think about in how many different formats a price can be written: with or without the thousands separator, which could also be a comma or a dot, with a currency symbol or not, and so on.
Also, descriptions could have some new line characters inside them and we want to reduce them to only one line.
We need to standardize country and currency codes from different websites, in order to compare different extractions.
In other words, we need a process of data cleaning and standardization, and there are two approaches for it: clean the data in the scraper or after loading data in a database.
Both processes have pros and cons, but before diving into them, let’s see an example of a web data quality process.
The data quality process for web data
Let’s consider the data already scraped, so we’re using a database to ingest the results of our scrapers.
Splitting the scraping phase from the data quality one makes the writing of the scrapers more straightforward and light since all the data cleaning will be done lately, usually on a database via SQL.
You don’t have to care about the formats of the prices you’re scraping, there is no need to add more packages like Panda to this task, less code to write, and less time spent on the debugging of the scrapers.
On the other side, this means you need to add a database to your tech stack, and this could be an overshoot if you’re planning to scrape only a few websites.
An example of a data quality process using a database
The first step of this process is, of course, loading the just extracted web data inside your database.
The tools to use and the cleaning process vary widely from the type of data you’re extracting: large unstructured strings will require a different database, while structured data can be loaded on an SQL one, and this is the case that requires most rules.
In a typical structured data feed, let’s say product prices from e-commerce, we usually have these steps:
clean numeric fields like prices and quantities
clean string fields like product descriptions
validate fields like URLs or products, to check if we’re scraping correctly
standardize fields like currency codes and country codes
only after all the previous steps, publish the data for the final user

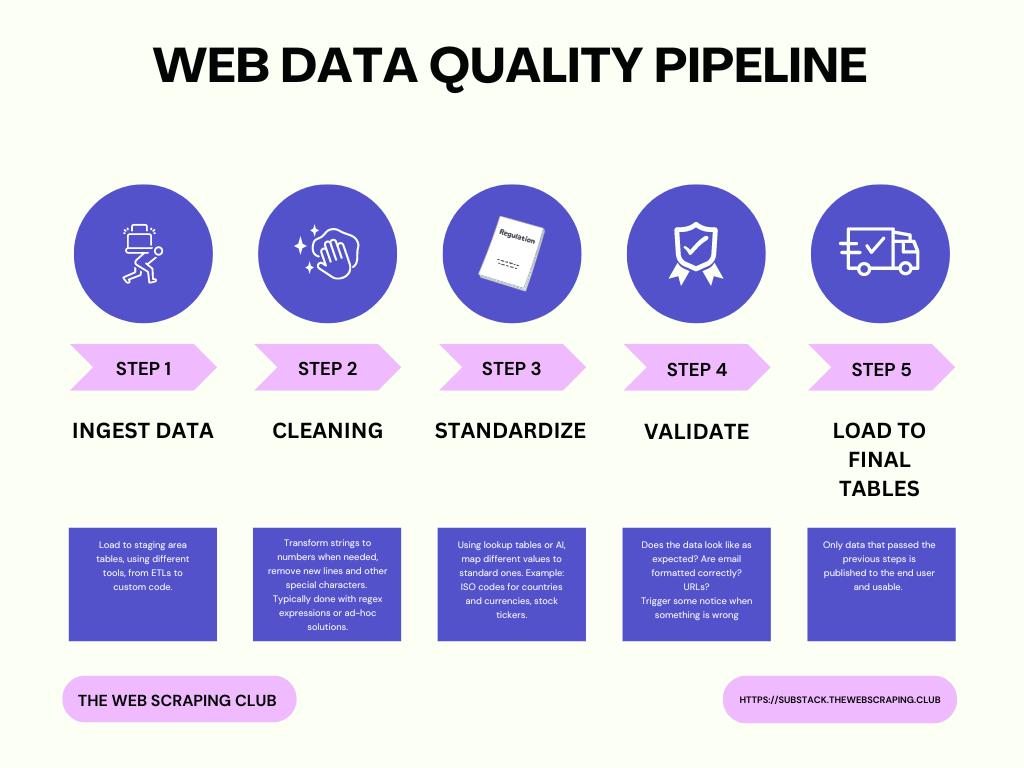
Let’s make an example of a pipeline of e-commerce pricing data that lands on a SQL database.
We start by loading the output of the scraper as raw text data mapped in an SQL table with the same data structure.
After that, we try to clean data, like numeric fields, using regular expressions: in the case of the prices, all the different ways we can write a price, also including the currency (1.000 EUR 1,000.00 1000€) become a decimal number (in this case 1000.00).
This is usually done via regular expressions in SQL, sometimes also in more than one step.
The second step is to standardize data coming from different websites and countries: let’s say that our country column requires the 3-digit ISO code, we’ll have to map all the different ways we encounter a country to the standard format.
Since a country can be called in different languages and formats, the values we’ll encounter could be several dozen but not an infinite number, and this task could be done via the so-called lookup tables.
Whenever we encounter a new value for a country, we write it on the first column of the two available in the lookup table.
In the second one, we’ll manually define what’s the correct ISO code for that string.
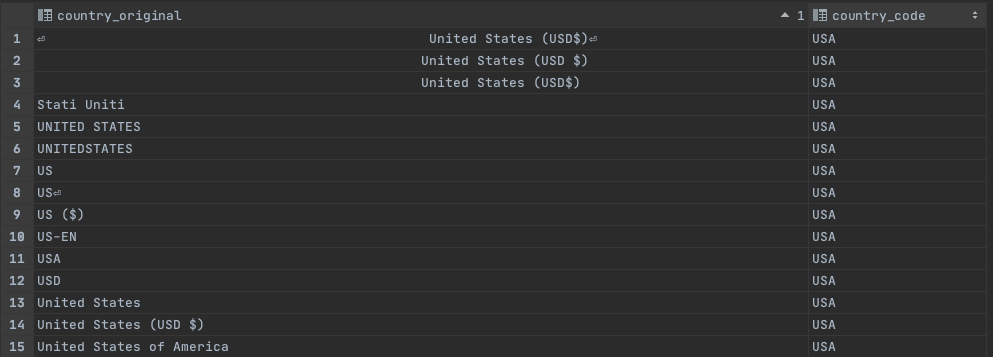
Of course, this process is maintainable because we have a finite and not-so-large array of values we can encounter per country.
After this phase, we can have a look at the data that went out from the standardization phase and check if there’s everything we expect:
Are e-mail addresses formatted correctly?
Are the products’ URLs valid?
Is there any empty field?
Inside the fields that required standardization, did every value get mapped to the standard one?
All these checks can be made using queries in SQL and could be linked to some alerting system, so you can have everything under control and find any issue before it’s too late.
Last but not least, after the scraped data passes all these quality checks, we can load it to a final table, containing only safe and usable data, which can be shared with the final user in whatever format you need.
As you can see, the process for making the web data just scraped usable is long and needs different steps to be taken, and it remains similar even if you want to keep it inside your scraper rather than on a database.
The Data Quality process embedded in a scraper
If we choose to perform the data quality process during our scraping phase, the steps we need to take remain more or less the same but their implementation change.
Let’s say we’re using Python to scrape a website, we have some libraries like Price-Parser that solve the formatting issue for prices contained in strings.
We should write our regular expressions for cleaning numeric fields and descriptions, but more or less this step is similar to the SQL one, we need to include additional packages to our scraper.
The data standardization process instead is more tricky: we need to import somehow the target values and map our scraped values to them. There could be several solutions, depending on case to case: we could import the lookup tables inside the scraper starting from an external source or map singularly every value in the scraper to the one expected.
Then the data validation step is similar to the one described in the database mode: we can set rules tailored for the scraper we’re writing, so we can understand if there’s something wrong in the data we’re getting and eventually raise some warnings.
After this final step, all the data coming out from the scraper is ready to be published and sent to the final user.
Pros and cons of the two approaches
After describing the two approaches to data quality, I think you’ve already got an idea of the pros and cons.
While if you build a data quality process inside your scraper, this can be tailored to the specific website you’re scraping, this means that you need to redo most of the work for every scraper you’re writing. This is ok if you’re managing a few scrapers but if you need to scale your operation, having a centralized point where to implement these rules can be a great advantage, especially now that databases are fully managed on the cloud and don’t require a great maintenance to be up and running.