
The Lab #54: Scraping from Algolia APIs
Why internal APIs are always the best choice for scraping a website

Some days ago I read a great post from Alex Lokhov, from his substack MapeZero, where he’s describing a great use case for web-scraped data.

Alex is the former Head of Research at Hatched Analytics, an alternative data firm, where web scraping, probably, was one of the main sources. The substack just started but I’m already an avid reader.
In this post, He’s describing how web data extracted from a fashion marketplace could be used to understand how different brands are following sustainability principles, by extracting the materials from the product detail pages, for different clothing categories.
The website under the lens is endclothing.com and it’s one of the hundreds we also scrape at Re Analytics.com, the web data factory we started with Andrea Squatrito 10 years ago.
This is another proof of the importance of the Databoutique.com project: the data available on the website is the same for everyone. Today, everyone collects and refines data on their own, facing the costs for all the phases. Databoutique wants to decouple these phases, by productizing web data extraction available on an exchange for web data.
In this way, web data feeds are available from sellers at a fraction of the extraction costs, while buyers can get reliable data without the hassle of web scraping, and focus on their business.
The Endclothing website is a perfect example of this theory since we can extract much information from their internal APIs for many use cases. Let’s see how to do it.
How does the EndClothing website work?
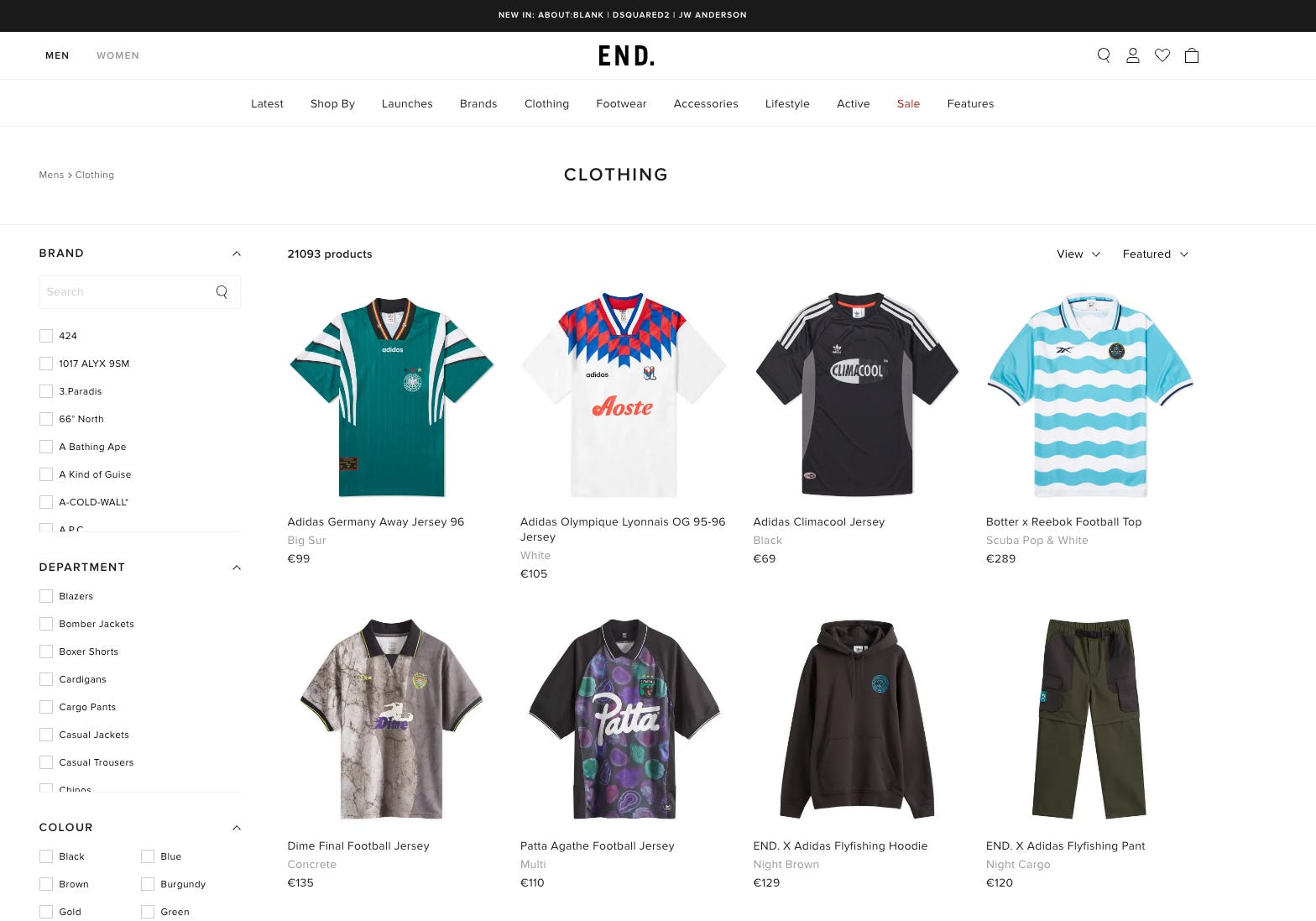
EndClothing is the typical e-commerce website, with a product list page per each designer or product category and a product detail page per each product on sale.

When scraping an e-commerce website, the first thing to have a look at is how the product list pages paginate, by opening the network tab in the “developer tools” section of the browser and clicking on page 2 of a category (or the load more button, like in this case).
By clicking this button on EndClothing, we’ll see that all the data displayed on the product list page is fetched by a request to an Algolia API endpoint.

Replicating this request for every page and product category is enough to scrape the whole product catalog of the website.
How do Algolia endpoints work?
Some months ago I wrote an extended article about Algolia, where I scraped data from the famous Micheline Restaurant guide.

Algolia is a robust search-as-a-service platform designed to enhance search functionality across websites and applications. It provides developers with a suite of APIs and tools that enable the creation of fast, relevant, and scalable search experiences. Algolia's core offering is its hosted search engine, which can be easily integrated into various applications to deliver real-time, typo-tolerant search results. This solution is particularly useful when websites need to load a ton of dynamic content from the backend, just like in this case.
Overview of the API Endpoint
The endpoint we find in the network tab is the following:
https://search1web.endclothing.com/1/indexes/*/queries?x-algolia-agent=Algolia%20for%20JavaScript%20(3.35.1)%3B%20Browser&x-algolia-application-id=KO4W2GBINK&x-algolia-api-key=dfa5df098f8d677dd2105ece472a44f8Let’s analyze its components:
Base URL: https://search1web.endclothing.com. This is the domain where the Algolia search service for the specific application is hosted.
API Version: /1/indexes/*/queries. This segment of the URL specifies that the API is utilizing version 1 (/1/) and is targeting multiple indexes (*). The /queries part indicates that this endpoint is designed for performing search queries.
Query Parameters:
x-algolia-agent=Algolia%20for%20JavaScript%20(3.35.1)%3B%20Browser
.This parameter specifies the client making the request. It includes the agent name Algolia for JavaScript and the version 3.35.1, indicating the use of the JavaScript client library for making API requests from a browser environment.x-algolia-application-id=KO4W2GBINK. This is the unique identifier for the Algolia application making the request. It is used to route the request to the correct application environment within Algolia’s infrastructure.
x-algolia-api-key=dfa5df098f8d677dd2105ece472a44f8. This API key is used for authentication and authorization purposes by the website to the Algolia servers. It grants the website access to perform search queries against the specified indexes.
Structure of the Request Payload
The JSON payload for the request follows a structured format designed to define multiple search queries and their respective parameters. An example payload is as follows:
{"requests":[{"indexName":"catalog_products_v2_gb_products","params":"userToken: anonymous-72bb7a36-a663-45a8-bd9b-a9d75b6a58ae
analyticsTags: ["browse","web","v3","it","IT","clothing"]
page: 1
facetFilters: [["categories:Clothing"],["websites_available_at:3"]]
filters:
facets: ["*"]
hitsPerPage: 120
ruleContexts: ["browse","web","v3","it","IT","clothing"]
clickAnalytics: true"},{"indexName":"catalog_products_v2_gb_products","params":"userToken=anonymous-72bb7a36-a663-45a8-bd9b-a9d75b6a58ae
analyticsTags: ["browse","web","v3","it","IT","clothing"]
page: 1
facetFilters: [["websites_available_at:3"],["categories:Clothing"]]
facets: ["*"]
hitsPerPage: 120
ruleContexts: ["browse","web","v3","it","IT","clothing"]
clickAnalytics: true"},{"indexName":"catalog_products_v2_gb_products","params":"userToken=anonymous-72bb7a36-a663-45a8-bd9b-a9d75b6a58ae
analyticsTags: ["browse","web","v3","it","IT","clothing"]
page: 1
facetFilters: [["websites_available_at:3"]]
filters:
facets: categories
hitsPerPage: 120
ruleContexts: ["browse","web","v3","it","IT","clothing"]
analytics: false"},{"indexName":"catalog_products_v2_gb_products","params":"userToken=anonymous-72bb7a36-a663-45a8-bd9b-a9d75b6a58ae
analyticsTags: ["browse","web","v3","it","IT","clothing"]
page: 1
facetFilters: [["categories:Clothing"]]
filters:
facets: websites_available_at
hitsPerPage: 120
ruleContexts: ["browse","web","v3","it","IT","clothing"]
analytics: false"}]}In our example, we have four different queries for the clothing category, each with different analytics parameters and facets. This payload is where we should intervene to scrape the website, by changing the filters and the page number.
Warning: The information provided in this article is for educational purposes only. Unauthorized use of API keys and endpoints may violate the terms of service of the target website and Algolia. It is imperative to respect the privacy and business operations of the website. Any misuse or actions causing harm or disruption to the target website's business operations are strictly prohibited and could result in legal consequences. Always ensure that you have the necessary permissions and adhere to the terms of service when using any APIs or web services.
An amazing outcome
The most fascinating part of this use case is the output of the request. A JSON filled with details on every single product available on the website.
{
"name": "Polo Ralph Lauren Corduroy Polo Shirt",
"description": "<p>Since 1967, the all-American fashion of Polo Ralph Lauren has been striking the perfect balance of Ivy League classics and time-honoured English heritage looks. Crafted from a durable cotton corduroy, this polo is designed for smart casual endeavours. On the chest the iconic pony is embroidered.</p>\r\n<ul>\r\n<li>100% Cotton</li>\r\n<li>Two Button Placket</li>\r\n<li>Ribbed Trims</li>\r\n<li><a href=\"https://www.endclothing.com/brands/polo-ralph-lauren/polo-shirts\">Shop All Men’s Polo Ralph Lauren Polo Shirts</a></li>\r\n</ul>",
"media_gallery": [
"/1/2/12-06-24-LS_710909633011_1_1.jpg",
"/1/2/12-06-24-LS_710909633011_7_1.jpg",
"/1/2/12-06-24-LS_710909633011_8_1.jpg",
"/1/2/12-06-24-LS_710909633011_m9_1.jpg",
"/1/2/12-06-24-LS_710909633011_10_1.jpg"
],
"sku": "710909633011",
"color": [
"Blue"
],
"created_at": "2024-03-06 22:47:45",
"sale_type": "Not on sale",
"brand": "Polo Ralph Lauren",
"department": "Polos",
"colour": [
"Blue"
],
"gender": "Mens",
"menswear": 1,
"womenswear": 0,
"url_key": "polo-ralph-lauren-corduroy-polo-shirt-710909633011",
"small_image": "/1/2/12-06-24-LS_710909633011_1_1.jpg",
"model_crop_image": "no_selection",
"model_full_image": "/1/2/12-06-24-LS_710909633011_m9_1.jpg",
"launches_media_gallery": {
"images": [],
"values": []
},
"for_sale_online": 1,
"restock": 0,
"season": "AW24 Q3",
"status": 1,
"news_from_date": "2024-06-12 00:00:00",
"departmentv1": "Tops",
"categoryv1": "Polo",
"news_from_date_unix": 1718150400,
"size_label": [
"Small",
"Medium",
"Large",
"X-Large"
],
"size": [
"Small",
"Medium",
"Large",
"X-Large"
],
"categories": [
"Latest",
"Latest / New This Week",
"Clothing",
"Clothing / Polo Shirts",
"Brands / Polo Ralph Lauren"
],
"sku_stock": {
"7109096330113": 3,
"7109096330114": 3,
"7109096330115": 3,
"7109096330116": 2
},
"stock": 11,
"full_price_1": 149,
"final_price_1": 149,
"full_price_2": 169,
"final_price_2": 169,
"full_price_3": 175,
"final_price_3": 175,
"full_price_4": 275,
"final_price_4": 275,
...,
"websites_available_at": [
...
],
"actual_colour": "Cassidy Blue",
"algoliaLastUpdateAtCET": "2024-06-13 11:53:57",
"objectID": "3969962",
"_highlightResult": {
"name": {
..
}
],
"categories": [
{
"value": "Latest",
"matchLevel": "none",
"matchedWords": []
},
{
"value": "Latest / New This Week",
"matchLevel": "none",
"matchedWords": []
},
{
"value": "Clothing",
"matchLevel": "none",
"matchedWords": []
},
{
"value": "Clothing / Polo Shirts",
"matchLevel": "none",
"matchedWords": []
},
{
"value": "Brands / Polo Ralph Lauren",
"matchLevel": "none",
"matchedWords": []
}
],
"actual_colour": {
"value": "Cassidy Blue",
"matchLevel": "none",
"matchedWords": []
}
}
},We’ve got, of course, the product price, without discounts (full price) and including them (final price), all in different countries (full_price_1, full_price_2, and so on).
Together with the product categories (gender, departmentv1, categoryv1), you’ve got all you need for a basic product prices monitoring tool. On Databoutique, this reflects on the Data Schema E0001.
Do you need more details, like the fabrics used, colors, or sizes for a more in-depth analysis like the one made by Alex on ESG? By adding the description and the color/size fields, you can have it (and on Databoutique this level of detail can be found on the Data Schema E0003).
Are you training an AI model for the fashion industry and need thousands of images, from different angles? In the media_gallery list inside the JSON you have all the images shot for that product. By combining the previous data schemas with the media asset one, you get all these images, labeled with the level of details you need.
Do you want the website’s sales performance or the top sellers per brand? You’ve got the field “stock” in the response! You just need a daily data feed from scraping or from Databoutique’s E-Inventory schema, and you’re ready to go.
This JSON in response is simply a gold mine of information, for so many different use cases! Let’s see how we can get it!
As always, if you want to have a look at the code, you can access the GitHub repository, available for paying readers. You can find this example inside the folder 54.ALGOLIA-END
If you’re one of them but don’t have access to it, please write me at pier@thewebscraping.club to get it.
Creating the scraper
