
Algolia and web scraping: an introduction
How to use Algolia endpoint to gather data from websites.

This post is made in collaboration with Martina Pugliese from Doodling Data . Her newsletter focuses on Data Analytics and Visualization, with a human touch. In fact, her handmade charts are great and you can find the ones created with the data extracted from this article in this post.
What is Algolia?
Algolia is a cloud-based search-as-a-service provider that offers a scalable search engine solution internal to websites. It is designed to enhance the search experience on websites and mobile applications, making it more intuitive, relevant, and efficient for users.
The website owners define the data attributes to be retrieved by different queries and their results are automatically updated by the internal search engine.
In other words, if we have a website where we need to show a list of items constantly updated, once we set up the query to retrieve these items and their attributes, its result will be always fresh and updated without any human interaction.
One example of the internal search engine is on the Hacker News search page: given a word to search, it will be submitted to the Algolia API endpoint with a set of defined parameters, returning in the response the desired output.

Another use case is the Michelin Guide website, where in the restaurants’ section we can browse all the suggested places to eat by the famous guide.

There are different filters we can play with and, in order to offer a fast and dynamic website experience, on the backend the results are gathered using Algolia.
In this case, here’s the call for retrieving all the starred restaurants in the world.
How Algolia works?
We won’t dig into the technical documentation of Algolia since it would be an overkill for our main purpose, which is to use the API endpoint to gather web data in the most lightweight way, both for the website itself and for us.
Both the examples we’ve seen before, despite being slightly different, have in common the query string parameters: in fact, every Algolia installation has an Agent, an API Key, and an Application ID, which determine the scope and the authentication to the API.
These parameters are passed in the request’s URL, like in this example from the Hacker News website:
https://uj5wyc0l7x-dsn.algolia.net/1/indexes/Item_dev/query?x-algolia-agent=Algolia%20for%20JavaScript%20(4.13.1)%3B%20Browser%20(lite)&x-algolia-api-key=28f0e1ec37a5e792e6845e67da5f20dd&x-algolia-application-id=UJ5WYC0L7XAs you may have noticed, we’re not querying the Hacker News website but an Algolia Server. As far as I understand from the documentation, in fact, the data is indexed and sent from the website to Algolia, which stores it and returns the result of the queries.
Depending on the various products and implementations, we can have different parameters to pass in the payload.
In the case of Hacker News, since we’re using a search bar to query the website, the parameters to pass need to be coherent with an open text search:
{"query":"scraping",
"analyticsTags":["web"],
"page":0,
"hitsPerPage":30,
"minWordSizefor1Typo":4,
"minWordSizefor2Typos":8,
"advancedSyntax":true,
"ignorePlurals":false,
"clickAnalytics":true,
"minProximity":7,
"numericFilters":[],"tagFilters":[["story"],[]],
"typoTolerance":true,
"queryType":"prefixNone",
"restrictSearchableAttributes":["title","comment_text","url","story_text","author"],
"getRankingInfo":true}TypoTolerance, as the name suggests, is a feature that helps the end user find the content he was looking for, even if he made some typos in the search bar.
minProximity is a parameter that sets if the returned results should contain only the exact word searched (value 1) or also similar words.
In the case of the Michelin Guide website, we’re using a different Algolia service, called instantsearch, which works more like a traditional query system.
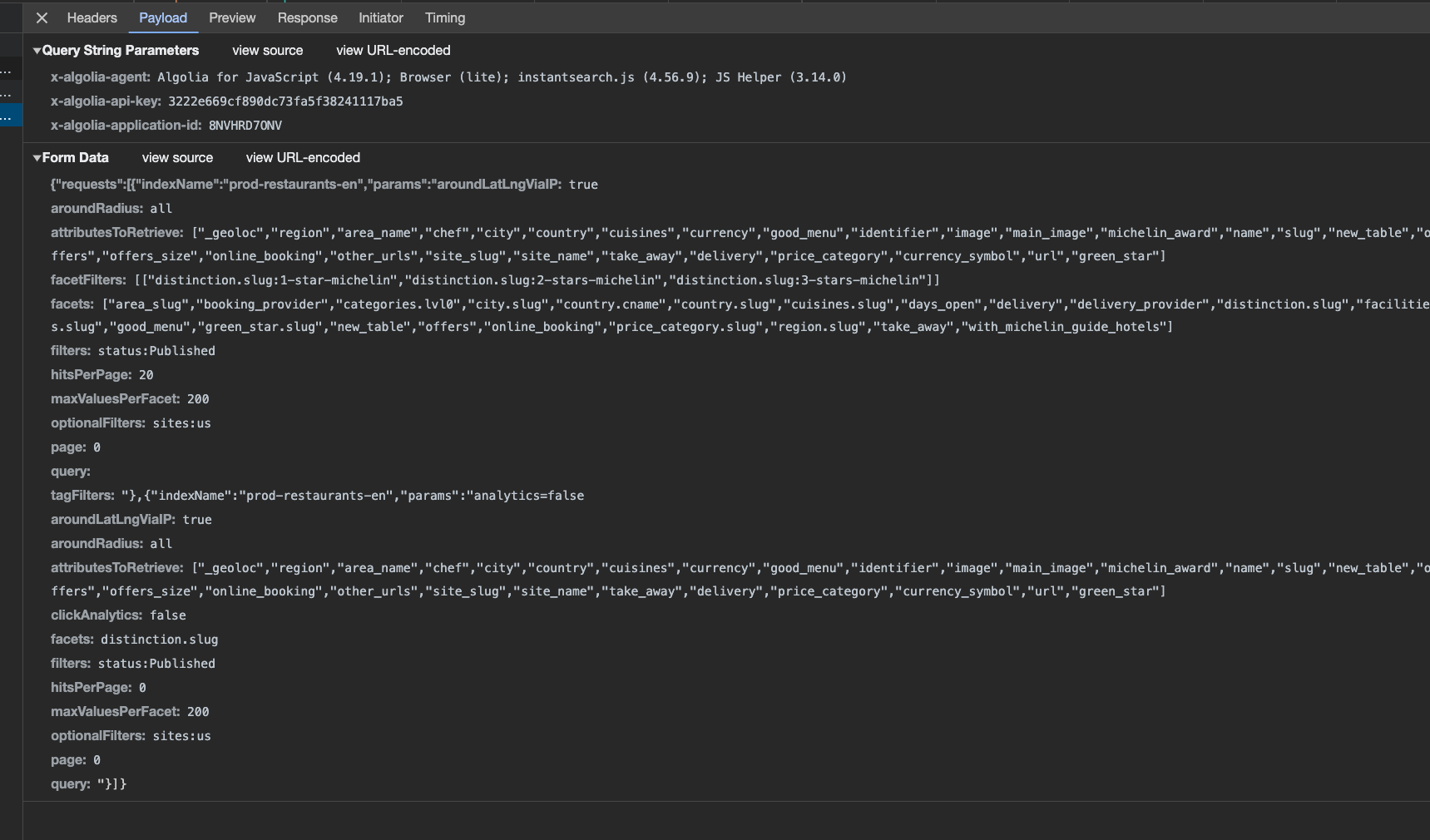
{"requests":
[{"indexName":"prod-restaurants-en",
"params":
"aroundLatLngViaIP: true
aroundRadius: all
attributesToRetrieve: ["_geoloc","region","area_name","chef","city","country","cuisines","currency","good_menu","identifier","image","main_image","michelin_award","name","slug","new_table","offers","offers_size","online_booking","other_urls","site_slug","site_name","take_away","delivery","price_category","currency_symbol","url","green_star"]
facetFilters: [
["distinction.slug:1-star-michelin","distinction.slug:2-stars-michelin","distinction.slug:3-stars-michelin"]
]
facets: ["area_slug","booking_provider","categories.lvl0","city.slug","country.cname","country.slug","cuisines.slug","days_open","delivery","delivery_provider","distinction.slug","facilities.slug","good_menu","green_star.slug","new_table","offers","online_booking","price_category.slug","region.slug","take_away","with_michelin_guide_hotels"]
filters: status:Published
hitsPerPage: 20
maxValuesPerFacet: 200
optionalFilters: sites:us
page: 0
query:
tagFilters: "},
{"indexName":"prod-restaurants-en","params":"analytics=false
aroundLatLngViaIP: true
aroundRadius: all
attributesToRetrieve: ["_geoloc","region","area_name","chef","city","country","cuisines","currency","good_menu","identifier","image","main_image","michelin_award","name","slug","new_table","offers","offers_size","online_booking","other_urls","site_slug","site_name","take_away","delivery","price_category","currency_symbol","url","green_star"]
clickAnalytics: false
facets: distinction.slug
filters: status:Published
hitsPerPage: 0
maxValuesPerFacet: 200
optionalFilters: sites:us
page: 0
query: "}]
}The parameters are the list of attributes to retrieve and other query parameters that correspond to the filters applied in the website UI.
Do you like what you’re reading? Don’t want to miss the next newsletter? Please consider subscribing for free.
How we can use Algolia for Web Scraping?
As we have seen, Algolia is designed to retrieve and expose data on websites fast and with no hassle, which makes it a perfect target for our web scraping projects. By targeting the API endpoint of a certain website, we can get the public data it exposes without overloading its hosting and transferring the resulting JSON instead of the raw HTML, which is much more demanding.
Also, the time spent creating the scraper is much less, since we only need to replicate the request that the website makes to the Algolia servers. The request parsing consists basically of parsing the output JSON, which is more reliable and stable than the raw HTML code.
A real-world example: the starred restaurants
Let’s say we want to scrape all the starred restaurants on the Michelin Guide website and get a bunch of their attributes like the cuisine type, their location, the Chef’s name, and so on.
First of all, I need to perform the query on the website and find the corresponding Algolia’s one. We can discover it by opening the Developer’s tools, under the network tab, and filtering by Fetch/XHR.

If you want to be sure you’re getting the right request, go to the desired page of the website, try to clear the tab, and reload the page, so you’ll see only what happens in this case.
After you’ve located the request, I find it easier to start implementing the scraper if I copy that in the cURL format.
To do so, right-click on the request and select copy as cURL (do not confuse with copy all as cURL, which will copy all the requests on the page).

You’ll find in your clipboard the corresponding cURL request of that specific one made with the browser.
curl 'https://8nvhrd7onv-dsn.algolia.net/1/indexes/*/queries?x-algolia-agent=Algolia%20for%20JavaScript%20(4.19.1)%3B%20Browser%20(lite)%3B%20instantsearch.js%20(4.56.9)%3B%20JS%20Helper%20(3.14.0)&x-algolia-api-key=3222e669cf890dc73fa5f38241117ba5&x-algolia-application-id=8NVHRD7ONV' \
-H 'Accept: */*' \
-H 'Accept-Language: en-US,en;q=0.7' \
-H 'Connection: keep-alive' \
-H 'Origin: https://guide.michelin.com' \
-H 'Referer: https://guide.michelin.com/' \
-H 'Sec-Fetch-Dest: empty' \
-H 'Sec-Fetch-Mode: cors' \
-H 'Sec-Fetch-Site: cross-site' \
-H 'Sec-GPC: 1' \
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36' \
-H 'content-type: application/x-www-form-urlencoded' \
-H 'sec-ch-ua: "Brave";v="119", "Chromium";v="119", "Not?A_Brand";v="24"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"' \
--data-raw '{"requests":[{"indexName":"prod-restaurants-en","params":"aroundLatLngViaIP=true&aroundRadius=all&attributesToRetrieve=%5B%22_geoloc%22%2C%22region%22%2C%22area_name%22%2C%22chef%22%2C%22city%22%2C%22country%22%2C%22cuisines%22%2C%22currency%22%2C%22good_menu%22%2C%22identifier%22%2C%22image%22%2C%22main_image%22%2C%22michelin_award%22%2C%22name%22%2C%22slug%22%2C%22new_table%22%2C%22offers%22%2C%22offers_size%22%2C%22online_booking%22%2C%22other_urls%22%2C%22site_slug%22%2C%22site_name%22%2C%22take_away%22%2C%22delivery%22%2C%22price_category%22%2C%22currency_symbol%22%2C%22url%22%2C%22green_star%22%5D&facetFilters=%5B%5B%22distinction.slug%3A1-star-michelin%22%2C%22distinction.slug%3A2-stars-michelin%22%2C%22distinction.slug%3A3-stars-michelin%22%5D%5D&facets=%5B%22area_slug%22%2C%22booking_provider%22%2C%22categories.lvl0%22%2C%22city.slug%22%2C%22country.cname%22%2C%22country.slug%22%2C%22cuisines.slug%22%2C%22days_open%22%2C%22delivery%22%2C%22delivery_provider%22%2C%22distinction.slug%22%2C%22facilities.slug%22%2C%22good_menu%22%2C%22green_star.slug%22%2C%22new_table%22%2C%22offers%22%2C%22online_booking%22%2C%22price_category.slug%22%2C%22region.slug%22%2C%22take_away%22%2C%22with_michelin_guide_hotels%22%5D&filters=status%3APublished&hitsPerPage=20&maxValuesPerFacet=200&optionalFilters=sites%3Aus&page=0&query=&tagFilters="},{"indexName":"prod-restaurants-en","params":"analytics=false&aroundLatLngViaIP=true&aroundRadius=all&attributesToRetrieve=%5B%22_geoloc%22%2C%22region%22%2C%22area_name%22%2C%22chef%22%2C%22city%22%2C%22country%22%2C%22cuisines%22%2C%22currency%22%2C%22good_menu%22%2C%22identifier%22%2C%22image%22%2C%22main_image%22%2C%22michelin_award%22%2C%22name%22%2C%22slug%22%2C%22new_table%22%2C%22offers%22%2C%22offers_size%22%2C%22online_booking%22%2C%22other_urls%22%2C%22site_slug%22%2C%22site_name%22%2C%22take_away%22%2C%22delivery%22%2C%22price_category%22%2C%22currency_symbol%22%2C%22url%22%2C%22green_star%22%5D&clickAnalytics=false&facets=distinction.slug&filters=status%3APublished&hitsPerPage=0&maxValuesPerFacet=200&optionalFilters=sites%3Aus&page=0&query="}]}' \
--compressedAs we can see, we have the API endpoint, the request headers embedded in the browser, and in the —data-raw field the payload of the POST request.
For a better-formatted view, we can always reference what we’re seeing in the browser, under the payload view.
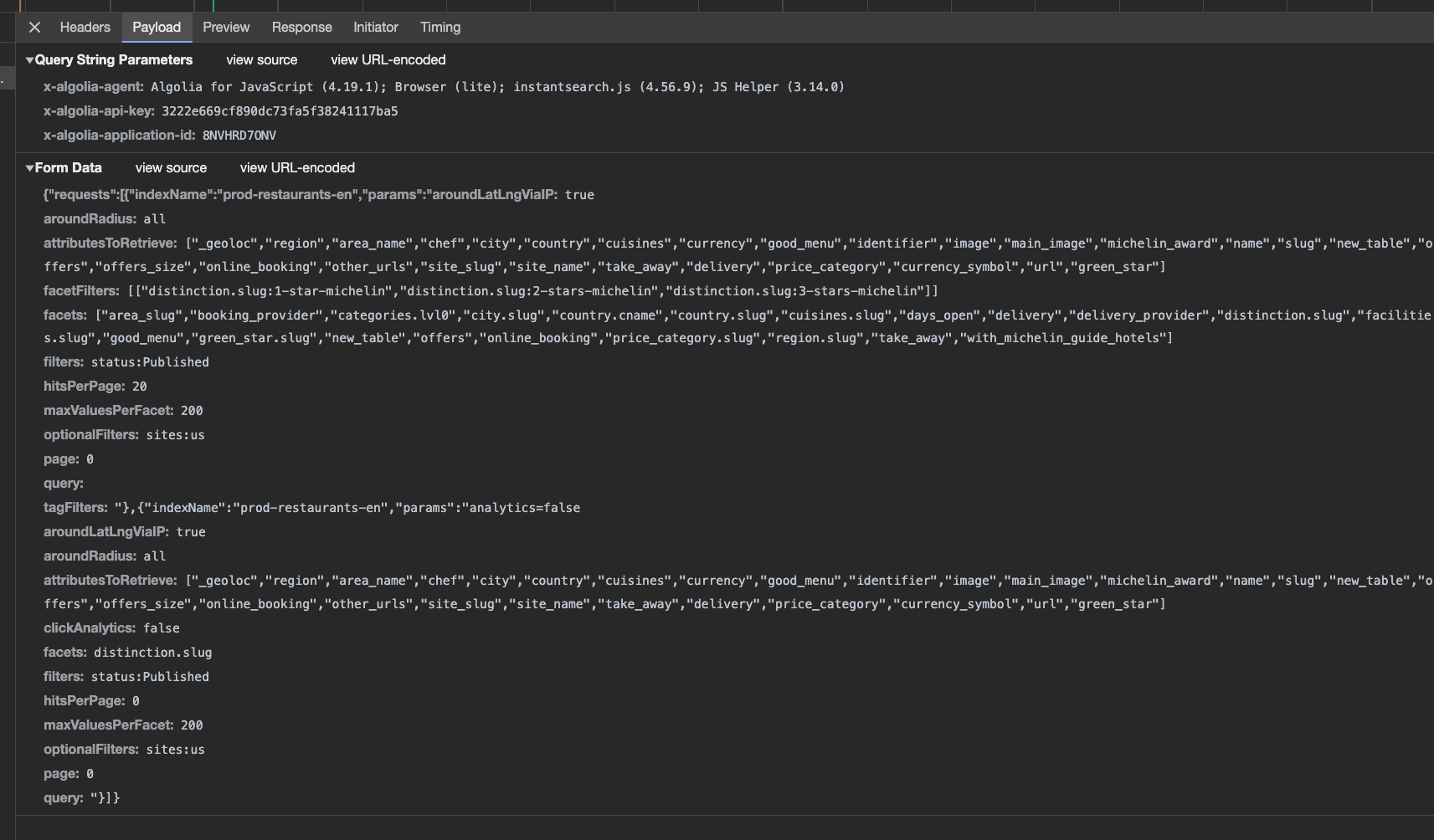
If we move back and forth with the pagination of the restaurant index, the only thing that will change is the page attribute. So, basically, the scraper will only need to replicate this query with different page parameters, until we get to the last one.
We can split the task into two different functions: an api_call one, where, given in input a page, we call the API endpoint to get the results for the given page.
def call_api(self, response):
base_url='https://8nvhrd7onv-dsn.algolia.net/1/indexes/*/queries?x-algolia-agent=Algolia%20for%20JavaScript%20(4.19.1)%3B%20Browser%20(lite)%3B%20instantsearch.js%20(4.56.9)%3B%20JS%20Helper%20(3.14.0)&x-algolia-api-key=3222e669cf890dc73fa5f38241117ba5&x-algolia-application-id=8NVHRD7ONV'
page=response.meta.get('page')
payload={
"requests":
[
{
"indexName":"prod-restaurants-en",
"params":"aroundLatLngViaIP=true&aroundRadius=all&attributesToRetrieve=%5B%22_geoloc%22%2C%22region%22%2C%22area_name%22%2C%22chef%22%2C%22city%22%2C%22country%22%2C%22cuisines%22%2C%22currency%22%2C%22good_menu%22%2C%22identifier%22%2C%22image%22%2C%22main_image%22%2C%22michelin_award%22%2C%22name%22%2C%22slug%22%2C%22new_table%22%2C%22offers%22%2C%22offers_size%22%2C%22online_booking%22%2C%22other_urls%22%2C%22site_slug%22%2C%22site_name%22%2C%22take_away%22%2C%22price_category%22%2C%22currency_symbol%22%2C%22url%22%2C%22green_star%22%5D&facetFilters=%5B%5B%22distinction.slug%3A1-star-michelin%22%2C%22distinction.slug%3A2-stars-michelin%22%2C%22distinction.slug%3A3-stars-michelin%22%5D%5D&facets=%5B%22area_slug%22%2C%22booking_provider%22%2C%22categories.lvl0%22%2C%22city.slug%22%2C%22country.cname%22%2C%22country.slug%22%2C%22cuisines.slug%22%2C%22days_open%22%2C%22delivery%22%2C%22delivery_provider%22%2C%22distinction.slug%22%2C%22facilities.slug%22%2C%22good_menu%22%2C%22green_star.slug%22%2C%22new_table%22%2C%22offers%22%2C%22online_booking%22%2C%22price_category.slug%22%2C%22region.slug%22%2C%22selected_restaurant%22%2C%22take_away%22%5D&filters=status%3APublished&hitsPerPage=20&maxValuesPerFacet=200&page="+str(page)+"&query=&tagFilters="
},
{
"indexName":"prod-restaurants-en",
"params":"analytics=false&aroundLatLngViaIP=true&aroundRadius=all&attributesToRetrieve=%5B%22_geoloc%22%2C%22region%22%2C%22area_name%22%2C%22chef%22%2C%22city%22%2C%22country%22%2C%22cuisines%22%2C%22currency%22%2C%22good_menu%22%2C%22identifier%22%2C%22image%22%2C%22main_image%22%2C%22michelin_award%22%2C%22name%22%2C%22slug%22%2C%22new_table%22%2C%22offers%22%2C%22offers_size%22%2C%22online_booking%22%2C%22other_urls%22%2C%22site_slug%22%2C%22site_name%22%2C%22take_away%22%2C%22price_category%22%2C%22currency_symbol%22%2C%22url%22%2C%22green_star%22%5D&clickAnalytics=false&facets=distinction.slug&filters=status%3APublished&hitsPerPage=0&maxValuesPerFacet=200&page=0&query="
}
]
}
#print(json.dumps(payload))
yield Request(base_url, callback=self.get_data,method="POST", body=json.dumps(payload), dont_filter=True, meta={'page':response.meta.get('page')})The parsing phase instead is assigned to the function get_data, where we basically parse the returning JSON and increment the page counter if we have retrieved some restaurants in our output.
def get_data(self, response):
page=response.meta.get('page')
data=json.loads(response.text)
for restaurant in data['results'][0]['hits']:
res_id=restaurant['objectID']
name = restaurant['name']
chef = restaurant['chef']
stars = restaurant['michelin_award']
cuisine_code =restaurant['cuisines']
try:
price_category = restaurant['price_category']['slug']
except:
price_category = 'n.a.'
country = restaurant['country']['code']
region = restaurant['region']['name']
city = restaurant['city']['name']
lat = restaurant['_highlightResult']['_geoloc']['lat']['value']
lon = restaurant['_highlightResult']['_geoloc']['lng']['value']
#print(data)
item = restaurantItem(
res_id=res_id,
name=name,
chef=chef,
stars=stars,
cuisine_code=cuisine_code,
price_category=price_category,
country=country,
region=region,
city=city,
lat=lat,
lon=lon,
json_data=restaurant
)
yield item
if len(data['results'][0]['hits']) >1:
page=int(page)+1
yield Request('https://guide.michelin.com/en/restaurants/all-starred', callback=self.call_api, dont_filter=True, meta={'page':page})You can find the full code of this scraper on our GitHub repository available for our readers here.
What we can learn from the output of the scraper?
I’ve sent Martina Pugliese two snapshots of the output of this scraper, since in the middle of November there has been the 2024 update of the Michelin Guide.
It’s very interesting to see what changed over the past year and, generally speaking, how this high-level cuisine is spread around the globe.
Have you ever imagined that the second country with the most starred restaurants is Japan, which has less than France but more than Italy?
For this and other curiosities, represented in a lovely way, you can have a look at Martina’s work in her post here