
Rethinking the web browser
How will web browsers evolve to meet the needs of AI?

Katie is part of the founding team at Lightpanda. Along with Francis and Pierre, they built BlueBoard, an e-commerce analytics company later acquired by ChannelAdvisor. Their experience developing its scraping infrastructure and navigating the limitations of Chrome headless inspired their vision to redesign a web browser for the AI era.
The internet is transforming before our eyes, and the tools we use to navigate it must evolve in order to keep up. Web browsers, our gateway to the internet, are struggling to meet the demands of an AI-driven era. While advances in web automation have brought us closer to scaling tasks at unprecedented levels, the browser remains a bottleneck in the tech stack – unoptimized, outdated, and not well-suited for web scraping and automation.
Built for humans, used by machines
When web browsers were first developed in the 1990s, they were designed for one primary user: humans. The browser’s job is to fetch content from a server, render it graphically, and execute JavaScript to create a dynamic and interactive user experience. This paradigm worked well when humans dominated web traffic.
But today, nearly 50% of internet traffic comes from machines – this number has risen by 10% in the past year. This growth comes from automated workflows, testing, indexing, and data scraping.
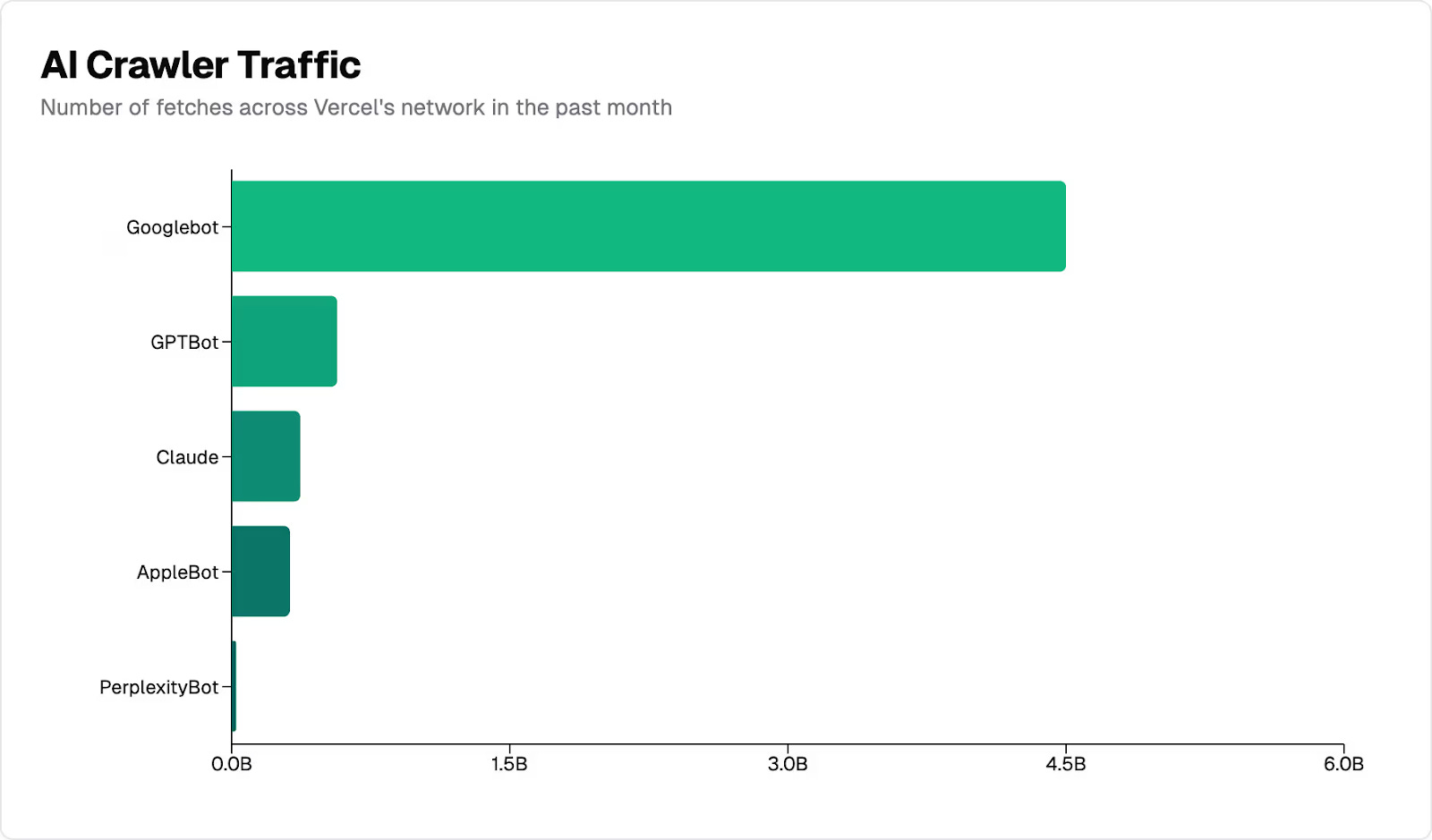
Vercel reported last month that AI-driven web crawlers were responsible for nearly 30% of the volume of Googlebot requests on their network.
The problem isn’t just a question of function but also one of legacy. Google Chrome, the dominant player in the browser market with a 67% share, is built on decades-old technology. Its Blink rendering engine (2013) is a fork of WebKit (2001), powering Safari, which itself is a fork of KHTML (1998), which powered the (now deprecated) Konqueror.
There’s nothing fundamentally wrong with this code. But relying on it for automation when it was built for humans surfing the web is like writing a novel with a paintbrush – impressive, but inefficient.
Enter: the headless browser
Web scraping has evolved significantly since the early 2000s. Back then, scraping was as simple as running a cURL command to retrieve raw HTML. Websites were mostly static, with no JSON, JavaScript, or dynamic loading to complicate the process. Modern websites, by contrast, are dynamic ecosystems that rely on JavaScript to load content and execute interactions.
To address these challenges, developers turned to Chrome or Firefox in headless mode: web browsers without the graphical user interface. Tools like Puppeteer and Playwright allow developers to execute code that programmatically controls them.
By loading web pages programmatically, headless browsers allow developers to interact with sites, bypass anti-bot measures, and extract data at scale.
However, even headless browsers come with significant limitations:
Resource intensity: loading a full browser for every request consumes vast amounts of memory and computing power
Slow to start (~600ms for Chrome): problematic for an on-demand resource
Stability issues: running multiple instances often leads to crashes and frequent restarts
Costly: scaling headless browser operations requires significant infrastructure investment
The rise of the browser-as-a-service
The inefficiencies of headless browsers have given rise to a new wave of browser-as-a-service platforms: companies offering APIs that abstract the complexities of deploying headless browsers in the cloud. By offering stealth modes, fingerprinting, and proxy management as part of their services, these platforms simplify developers’ lives.
Over the past few months, a number of open-source libraries have also emerged, offering alternatives to Puppeteer and Playwright with natural language processing built in. These tools aim to make web automation more intuitive by allowing developers to interact with headless browsers using plain language commands. For instance, instructions like "scroll to the reviews section" or "retrieve the latest headlines" can be converted into browser automation code and executed.
These frameworks reduce the complexity of building web automations and are designed to be connected with the main AI models and providers. By integrating natural language capabilities, they represent a growing trend in the scraping ecosystem.
Despite all the innovation happening at the infrastructure layer and above, these platforms are all still built on top of Chrome headless. As a result, they inherit the same inefficiencies, limitations, and high resource costs. While they may streamline workflows in the short term, they are not supported lower down in the tech stack to meet the scale of an AI-driven future.
Note from Pier about JS rendering: just few days ago Google required browsers to render Javascript in order to show SERP results. Here’s the full article about it.

AI crawlers are changing the game
The rise of AI crawlers is forcing the web scraping community to confront a critical question: what happens when the tools we’ve relied on for decades are no longer sufficient?
AI bots are driving unprecedented levels of scale. LLMs rely on vast amounts of web data for training and fine-tuning, usually in near real-time.
Vercel’s analysis highlights a significant divide in the capabilities of traditional search crawlers and emerging AI crawlers, which are responsible for nearly 1.3 billion fetches monthly, or about 28% of Googlebot's total volume. AI crawlers like OpenAI’s GPTBot and Anthropic’s Claude currently fetch JavaScript files but don’t execute them. It’s simply too expensive to do so at this scale with a traditional browser when they don’t require graphical rendering.

Jamin Ball had an interesting discussion with Brad Gertsner and Bill Gurley on the BG2Pod, thinking about transitional states versus end states:
“The transitional state today is we’re going to have agents that can scrape websites and view them as if I’m doing it. They’re going to recognize the button and click the button. What if we reinvented the browser and built it in a way where it’s not a button for a human eye, but everything is some composable API that an agent can recognize and interact with?”
A paradigm shift: a browser built for machines
Imagine a browser purpose-built for web automation, optimized for machines instead of humans. Such a browser would:
Eliminate graphical overhead: by skipping graphical rendering, it could operate with a fraction of the resources required by traditional browsers
Streamline JavaScript execution: retain the ability to execute JavaScript without the excess baggage of a consumer-facing browser
Prioritize efficiency: focus on start-up time, speed, scalability, and low memory usage to handle the demands of modern AI crawlers
Integrate natively into the agent: instead of relying on an external resource outside the program, the browser would become an integral part of the agent itself
As the web scraping ecosystem grows, the inefficiencies of current tools will only become more pronounced. Developers, businesses, and AI systems all stand to benefit from a browser that is lighter, faster, and better suited to the tasks at hand.
The road ahead
This is what we’re doing at Lightpanda. Over the past 2.5 years, we’ve been building a lightweight open-source headless browser specifically designed for web automation and AI. By skipping graphical rendering and leveraging Zig, a modern low-level programming language, we’ve created a browser optimized for efficiency and scalability.
In our demo environment, Lightpanda is 10x faster and 10x lighter than Chrome in headless mode. While still in development, we think this is an exciting moment for web scraping enthusiasts and AI developers.
The current limitations of traditional tools are fueling a wave of creativity and problem-solving across the industry. The future of web scraping and AI crawling depends on the infrastructure that supports it. As browsers continue to serve as the backbone of the web, their evolution will determine how efficiently machines can interact with online content. One thing is clear: the tools of the past won’t carry us into the future.
We’d love to hear your thoughts and connect with fellow innovators in this space. Check out the project on GitHub and feel free to reach out via email at katie@lightpanda.io or LinkedIn.
 | A guest post by
|