
The Scriptwall: Why Google is hiding its SERP content behind Javascript
What are the implications of this move for the web scraping industry?

The new year opened with a Bang!
Since January 15, Google has required Javascript to display search results on its website, gating its SERP content behind a JS wall. You can test this by disabling Javascript in your browser and trying to perform a query inside the search engine.


Nothing changes for the average internet user, at least on the surface. Even before this change, portions of the web were unusable without Javascript, thanks to anti-bot protections, user tracking systems, and other stuff added to render dynamic content.
This happens despite bugs hiding in website Javascript implementations, which could allow malicious code to be executed in web applications.
While requiring Javascript for a website to function correctly is nothing new, it always makes some noise when a company like Google moves. Let’s see what the implications of this move could be for the different actors involved, especially for the web scraping industry.
“Scriptwall” winners and losers
So why force people to enable JS to view SERP data when only 0.1% of searches are made with JS disabled? Is this percentage already netted off the traffic generated by bots, or not?
I feel that the share of traffic generated by bots on Google is much higher than just 0.1%, and Google wanted to address this issue with this move.
Winners
Google is definitely one of the winners in this scenario. The company spends billions of dollars to maintain the most used search engine in the world, keeping it free for everyone (We all know you’re paying with your data, but that’s another story). It has become so important in our lives that, when looking for a service or a product on the search engine, we rarely scroll the results after page two. On the first page, we usually find the most authoritative voices for that keyword, and this is the real value that Google wants to protect. The Scriptwall move is not about protecting from web scraping; Google is protecting its ranking system from the new competitors (aka AI companies), making it harder for them to cite website pages relevant to the prompt.
Google is forcing its competitors to build their internal PageRank and rely solely on it instead of eventually comparing their results with SERP ones.
Of course, all professional web scrapers know that enabling JS is not a blocker for any scraping operation. It’s just about changing the tools used, from browserless frameworks (like Scrapy) to browser automation tools like Playwrigth.
This means more costs for analyzing SERP data, which leads us to the second-place winners of the game: AWS, GCP, Azure, and all the data centers where these scraping operations are performed.
As more computing power is needed to perform SERP scraping, cloud bills for companies that do this will inevitably rise.
Losers
Given the previous point, the first losers of this move will be all the companies that sell products on top of SERP data: SEO optimization tools, SERP data providers, and similar services will see their margins get thinner.
This move should also be a lesson for all companies that rely on a third-party data source or service for their businesses, including all the ChatGPT wrappers, LinkedIn scrapers, and so on. You could be left out of the loop, forced into irrelevancy from one day to another, or see your margins disappear thanks to a new pricing plan. Standing on the shoulders of the giants is excellent for starting since you don’t have to reinvent the wheel, but it can be dangerous if you don’t have a backup plan.
When margins are eroded, as I can imagine they will be for SEO toolsets and similar services, the first action companies can take is to raise their prices. Thus, we have the other losers of the game: their end users.
The price of SERP data, whether in the form of API or inside tools, will rise, and we can imagine some movements in the industry, especially for smaller players already struggling today.
Of course, this move mainly targets generative AI companies. Google is trying to keep them out of its courtyard by making it more difficult for them to suggest the right sources for their answers to users’ prompts. I don’t think this will change long-term if it does not raise costs for training LLM models using web data. But since it’s already so expensive today that few companies can afford it, the Scriptwall won’t change the landscape.
Implications of the Scriptwall
The Scriptwall will probably not change the AI landscape, but it is a symptom of the growing intolerance toward these generative AI companies.
In some cases, LLMs are a serious threat to the survival of online businesses. Consider Stackoverflow: It was my “coding companion” until the advent of ChatGPT and Cursor. I barely access its website today, and I think I’m not the only one in this situation, as you can see from the latest 3 months of traffic monitored by Similarweb.
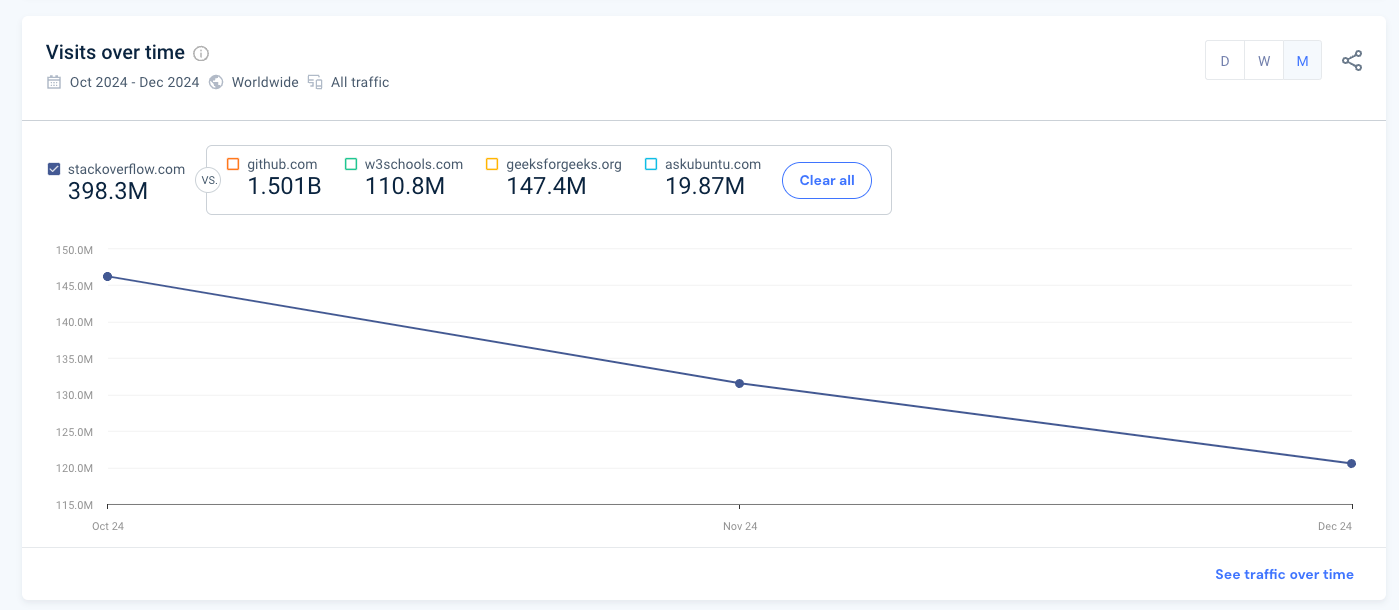
But I can bet that Stackoverflow was and is still one of the websites constantly scraped by AI companies to train their LLM: it’s the original source of the data, but this is ingested by LLMs, which are cannibalizing its business without giving back any attribution and revenue.
This is not an isolated case and will not be the last. Wikipedia, Quora, news websites, and others will have the same issues regarding maintaining traffic (and revenues). OpenAI and other companies naively suggested that websites use the robots.txt file if they don’t want to be scraped, but there are some documented cases where they openly ignored it.
So, what can these websites do to prevent being scraped? They could follow Google's example and contain their content inside a walled garden by making it harder to access or simply requiring an account, even a paid one. This would significantly damage the free internet as we know it today and, of course, also have implications for the web scraping industry.
Today, some companies are scraping StackOverflow or Quora for some reason, maybe some NLP algorithms, but this doesn’t directly hurt the website’s business. Before OpenAI, no company had such “scraping” power capable of extracting a massive quantity of data from the web, reusing it, and selling it to its customers as replies to prompts.
I’m probably a dreamer, but I hope that things will change soon and that OpenAI will share revenues or traffic with its data sources. Even because, if AI companies keep draining revenues from the websites until they shut down, its LLMs would not have any fresh data to be trained on.