
Is Web Scraping Dead?
Debunking some myths about web scraping

I’ve been in the web scraping industry for 10+ years and, considering the age of the industry, I think I could be considered one of its veterans.
During these years, together with my friend and colleague Andrea Squatrito we talked with thousands of people about web scraping, web data, and everything related.
I can remember the initial amazement on the face of our interlocutors when we showed for the first time the full scrape of a large website, both in the e-commerce and in the real estate industry. Ten years ago web data was something unheard of, at least for the majority of business people here in Italy, and the topic raised many questions: is this legal? is this data reliable?

Ten years later, everything changed: more companies are relying on web data, even if we’re far from mass adoption, at least web scraping is in the public domain. In many offices, even in SMEs, there's one person who at least tried to do some scraping, with alternate fortunes.
Even today, when showcasing Databoutique.com to partners and investors (yes, we’re planning a funding round), we have to answer some questions and observations that seem like old tales passed on year over year than facts. The most common: “Is the web scraping dead because of LLMs and AI?”.
Some of them are due to new technologies like AI that seem to solve every potential issue on the planet, others come from word of mouth without being investigated more. For this reason, I wanted to dedicate this post to debunking them, so that next time you’ll be asked the same question, you know a potential answer.
In this post, I’m expressing my 2 cents, and if you think I’m wrong or you want to debate on some point, feel free to comment below or write in our Discord server.
Debunking Some Myths About Web Scraping
Let’s start debunking some myths about web scraping from the most recent one, which involves the rapid evolution of AI and LLM models during the latest years.
Is the web scraping dead because of LLMs and AI?
The conversation around the impact of Large Language Models (LLMs) and Artificial Intelligence (AI) on traditional data collection methods, particularly web scraping, has gained significant traction in recent years. With the rapid advancements in AI technologies, a narrative has emerged suggesting that the capabilities of AI could render web scraping obsolete. This perspective, in my opinion, underestimates the difficulties of creating a model for all the possible use cases in which web scraping is used today and the long tail and variety of websites online today.
Web scraping, a tool for many use cases
When I’m talking about the variety of use cases in web scraping, I’m not thinking about the number of websites online today (the long tail issue referenced later in the article), but even when thinking about a single website, web scraping can be used in many different ways.
Let’s make a practical example, with a well-known website called Farfetch.com: it’s an e-commerce of fashion products that works like a marketplace, where different boutiques and brands sell online their inventory.
On Databoutique.com, for this website, we have the following datasets:
Product-level pricing, based mostly on the information available on the product list page of the website.
Inventory data, since this website exposes the inventory level per product, we collected it
Additional code lookup, since the website for every product shows the original product code provided by the brand we created a dataset for the specific use of product matching applications, or the store ID of the seller of the product
Image and video URLs, a dataset containing all the image and video URLs for every product on the website, useful for training image labeling algorithms
Many others are yet not available, like product pricing per size, including product details, and product placement on the website.
What we can understand from these examples? Web scraping is a multipurpose tool, for every website you can extract different types of information for different purposes.
This complexity and number of variants are not so compatible with one generalist model like GPT, which is barely able to scrape all the prices from a Farfetch product list page.
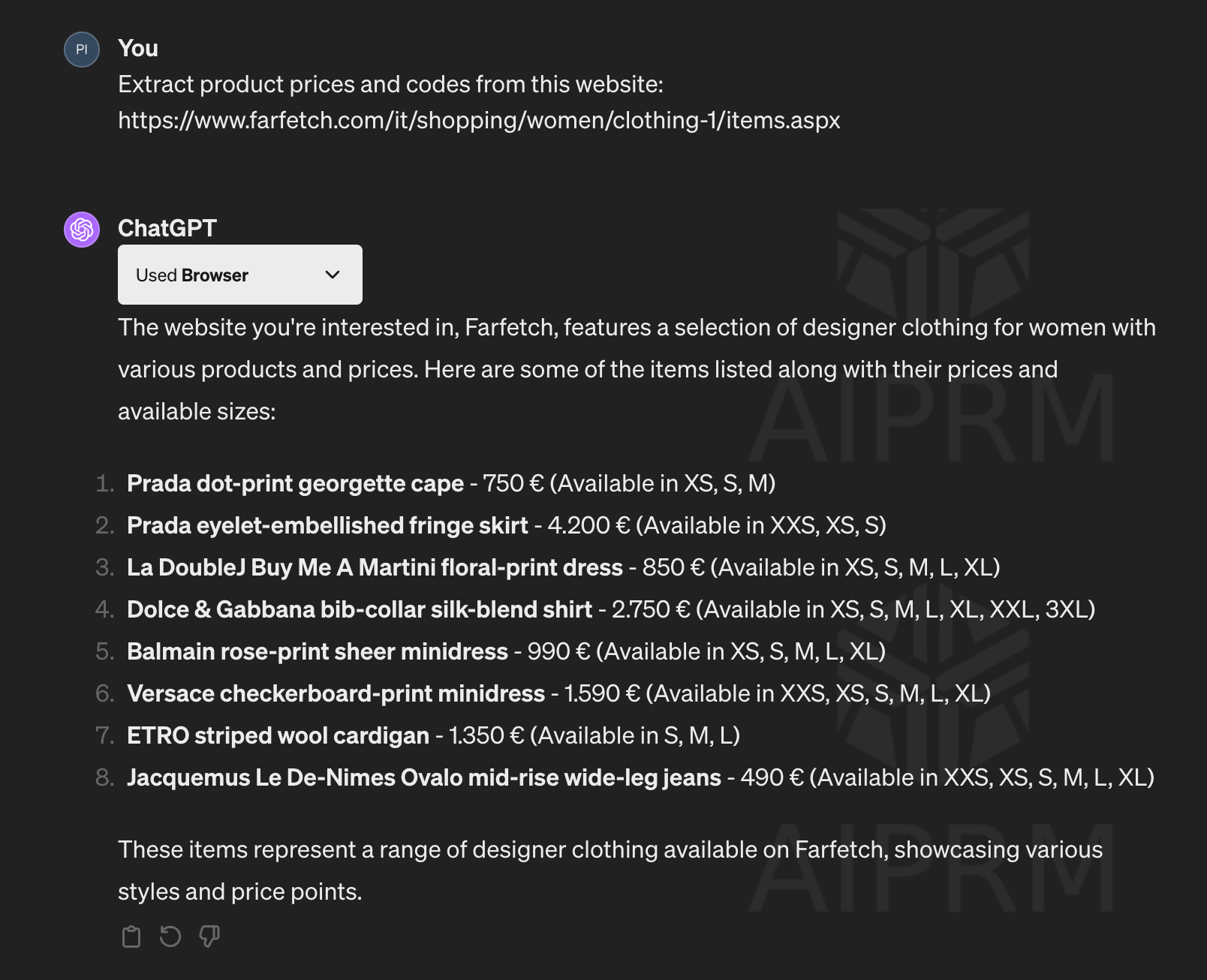
In fact, if I try to extract the Store ID from the same page, I get no results.

A long tail of websites
And if the variability in the extraction types probably it’s enough to cause distress in AI models, with the different types of websites this is even more evident.
It’s true that different e-commerces have more or less the same structure, but the HTML code and nodes could have different formats.
While detecting prices is a task that could be solved with a generic model, inventory levels are not expressed clearly in the code. Sometimes it’s called Quantity (and its abbreviations), but in most cases, the label is not so self-explanatory, like “measure2”.
AI could solve the HTML parsing, but not the crawling
But let’s suppose that in 5 years we’ll have a super specific LLM model designed for web scraping designed to extract every meaningful information from the code. That’s great, but we’re only halfway.
We need to understand how the website works, in which pages the data is, and bypass anti-bot protection (and in this case again other AI tools can be used), but I don’t see that writing a scraper will be something completely delegated to an AI model.
On the opposite, training LLMs and AI models in general require a huge amount of data, most of it is sourced by web scraping, so the trend I see is that web scraping is not dead but it’s healthier than ever, thanks to AI.
Web Scraping is Illegal
Another huge question mark people have about web scraping is about the legal context.
If you follow this newsletter, you probably have read our legal corner, especially the first post from Sanaea about the legal landscape of web scraping, which should be printed out and hung in every office involved in web data extraction.
The most debated topic is about the Terms of Services of a website, which usually forbid web scraping. The most common concept is that if the TOS forbids any automated access, then automatically any web scraping operation is illegal.
Of course, for publicly accessible data this is not true in most cases: feel free to listen to any lawyer for any legal advice for your specific case, but generally speaking, if you’re scraping non-personal and public information, you’re on the legal side of the operations.
Certainly, web scraping can also be used for illegal data gathering: in the end, it’s just a tool that can be used for good and for bad.
Web Scraping is Easy
At first glance, web scraping might appear as a straightforward task—write a script, target a website, and extract data, with no code tools or low effort in writing code. This is true when we need to extract once every while data from a website not protected by any anti-bot.
For this reason, every once in a while, talking with potential customers, you can hear the sentence: “Sure, we make web scraping in-house, we don’t need help” to discover later that the last successful run they had was 5 years ago.
Web scraping, on a regular interval and in a medium-sized scope, requires skills, budget, and manpower. And it’s getting even more difficult year after year, with more and more websites adopting anti-bot measures.
Luckily enough, there are also plenty of tools on the market, both free and commercial, that allow us to bypass these anti-bots, but this leads to the next myth about web scraping.
Web Scraping is Expensive
This objection has its foundations: ask a quote from any web data factory for a medium-sized project, with around 10-20 data feeds, with regular weekly updates and you probably won’t get anything below a thousand dollars per month. So, is web scraping expensive? For web data factories, there’s no doubt that costs for data extraction are rising.
So buying web data needs to be expensive? Actually, it is expensive to buy web data, but it does not need to be so. The problem is that up to now, the market of web scraped data has been highly inefficient.
In my direct experience and from what I hear from people in the industry, companies that are involved in doing web scraping to sell a service on top of it (like pricing comparison, competitive intelligence and so on), have the same issue: from a financial perspective, the cost of data extraction at scale are so high that all these companies have low margins. This is confirmed by the size of these companies and the investments received by them: how many of these companies are VC-backed? How many SaaS companies using mainly web scraping as a source for their services are listed?
The reason is quite simple: for web scraping, we’re inside a pre-industrial era. Let’s make an example, with tomatoes instead of web data. Today, it’s like having all the companies producing tomato sauce in bottles, have their own tomato fields, tractors, farmers, and all the costs for maintaining all these things. They all produce the same tomatoes but then add their secret ingredients to create their special sauce.
With web data, it’s the same: how many companies are scraping the prices from Zalando or Farfetch? Prices are the same, independent of who reads them. The data structure of the results could be different, but I’m sure that 80% of the data extractions can be standardized and considered as a commodity. There are for sure some peculiar use cases or hidden gems in websites you don’t want to share with others, but the plain vanilla scraping of prices, locations, and listings could be commoditized.
That’s the reason why we created Databoutique: to create a more efficient market by bringing industrialization to web scraping.
Instead of having, let’s say, 50 companies that cover 100 websites in total, with a huge overlap with each other, we can have each company cover only 5 websites that they sell to the others. The price for selling the dataset could be much lower since it can be sold 49 times, and every company, using the network effect, could get 250 websites and have more complete data to build their SaaS on top.
So yes, web scraping is expensive but could be much cheaper for buyers.
The Future of Web Scraping
Web scraping is far from dead: it’s more needed now than before. The digitalization of the economy enables more and more data to be gathered, and the need for data from AI models is fueling the web data request. To fulfill this need, AI-powered web scraping solutions could be an enabler but not a substitute for programmers.
With the wider adoption of web scraping and the growing maturity of the market, it’s becoming also clearer the legal landscape for the industry, with more regulations defining the guidelines for the operations.
But it’s still yet an industry not fully mature: the inefficiency of the web data market as it is today is limiting a broader adoption, with many companies willing to get web data but not having an adequate budget for the current project’s pricing. This means there’s still a wide array of opportunities available for players in the market.
So long live the Web Scraping, we have exciting times ahead!