
Legal Zyte-geist #1: Step-by-Step Guide to Compliant Web Scraping
A handy guide to assessing the compliance of your web scraping project

Welcome to the monthly column about web scraping and legal themes by Sanaea Daruwalla. She is the Chief Legal & People Officer at Zyte. Sanaea has over 15 years of experience representing a wide variety of clients and is one of the leading experts on web data extraction laws.
Disclaimer: This post is for informational purposes only. The content is not legal advice and does not create an attorney-client relationship.
Step-by-Step Guide to Compliant Web Scraping
At Zyte’s 2023 Extract Summit, I gave a talk breaking down how to analyze legal compliance for your web scraping projects and I’m going to walk you through that now. The starting point is
determine what you want to scrape, from where, and your use case for the data,
walk through the compliance checklist below, and
if you answer “yes” to any of the items in the compliance checklist, do a further legal review.
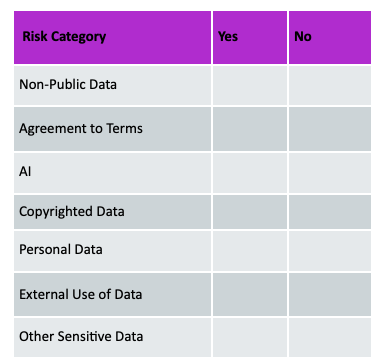
Now let’s take a few real-world examples and go through how to approach analyzing compliance.
Product Data Extraction for Competitive Intelligence
If you are scraping e-commerce product pages for competitive pricing intelligence, this would typically be considered a low risk project. If you walk through the checklist, you’ll be answering “no” to all the questions. Just make sure you’re scraping public data only, not logging in to the website, and you’re avoiding potential personal data, like reviewer name.
If, however, you decide you need a personal data field then you will need to conduct a full analysis. This analysis will depend heavily on the region in which the data subjects reside. If you’re scraping global e-commerce sites, the likelihood is that you’ll potentially obtain data about people within the EU and the US, thereby becoming subject to both US state laws and GDPR. Under US state laws, there is generally an exception for personal data that a person knowingly made available to the public. Things like the reviewer's name would fall under this exception because the person wrote the review and published it. Conversely, under GDPR there is no such exception for public data, so you will need to have a lawful basis to process the personal data. In this instance, the only available lawful basis would be legitimate interest, which would require a Legitimate Interest Analysis (LIA) to be carried out by a privacy professional. Also, you will need to adhere to GDPR’s notification, access, security, and minimization requirements. Given the burden here, it is always advisable to descope or anonymize the personal data if it is not imperative for your project.
You may also say “yes” to agreement to terms or non-public data if you want to get data behind a login. If you are explicitly agreeing to a website’s terms of service or logging in to the website, you must read and abide by its terms. If the terms state no scraping, then be sure not to log in and not to collect any non-public information from that site. However, in a standard e-commerce project, this is usually not a concern, as most relevant data can be obtained without logging in and by only scraping public data. We always advise to err on the side of caution and scrape only public data unless you believe you have a legitimate reason to do otherwise.
Do you want to suggest a topic for the next month's edition? Submit your question in The Web Scraping Club Discord Server, on the Legal Zyte-geist dedicated channel.
If you want to be sure to don’t miss the new episodes, please consider subscribing for free to the newsletter.
Data of Business Executives
In this use case, you are proposing to scrape data from business pages about executives to create a database. When you walk through your checklist here, you find that you would of course be scraping personal data. So you’ve answered “yes” to one of the questions on the checklist and need to conduct a legal analysis.
Similar to the use case above, you first need to determine where the data subjects reside. In this instance, you determine that you are only looking for US executive data and thus are bound by the various US state laws. Currently, the US does not have one federal law that covers all personal data, so many states have come out with their own laws to protect against misuse. Note that many of the state laws carry thresholds for when you will be bound by the law, so you will need to check this state by state to determine if you must comply. The most famous of these laws is the California Consumer Protection Act (CCPA) and many of the other state laws mirror this one. So for purposes of this post, we’ll focus on the CCPA.
The CCPA states:
“Personal information does not include publicly available information or lawfully obtained, truthful information that is a matter of public concern. For purposes of this paragraph, “publicly available” means . . . information that a business has a reasonable basis to believe is lawfully made available to the general public by the consumer or from widely distributed media; or information made available by a person to whom the consumer has disclosed the information if the consumer has not restricted the information to a specific audience.” Section 1798.140(v)(2)
In this case, the information is publicly available on the internet, it’s business information that you would reasonably believe the person made available, and it’s on various websites so it is on widely distributed media. As such, we can determine that it does not constitute personal information under CCPA and you can proceed with your project.
Data Extraction to Train LLM and Build Generative AI App
Here’s where things start to get a little more exciting . . . now you want to conduct a large-scale data extraction from a myriad of websites to train an LLM to create a GenAI app. Here we walk through our checklist and say “yes” to three of the items,
AI,
Copyrighted Data, and
Personal Data.
When training an LLM with large volumes of data from the web, you will want to ensure that you are only collecting public data, abiding by any terms you explicitly agree to, and respecting any data clearly tagged as not wanting to be used to train an AI model. Additionally, depending on the region you are in, you will need to ensure compliance with emerging data protection laws and guidelines. In the EU there is a draft AI Act that should instruct your work, in the US there is an AI Executive Order, and further guidelines will be produced by NIST next year. The draft AI Act is the most mature of these frameworks so far, and what we see emerging here is a risk-based approach, where higher-risk AI is more heavily regulated. Things like facial recognition and social scoring will be prohibited, and using AI in employment, education, and justice will be deemed high risk and come with various requirements in order to proceed lawfully. There are also limited and minimal risk categories, which require transparency and a code of conduct. Chatbots like ChatGPT currently appear to fall into the limited risk category, so transparency around usage is all that’s needed.
Now on to our copyright and data protection analysis . . .
Much of the data you scrape to train an LLM is likely copyrightable. Any tangible, original piece of work holds copyright protection – this includes articles, books, videos, pictures, and the list goes on and on. So the likelihood is that you will be scraping copyrighted data to train your LLM. Your LLM will then learn from that data and your GenAI application will create new works, either new text or images or videos. The two main questions here are
is it copyright infringement to train my LLM with copyrighted works, and
does the new work generated infringe on the copyright of the original works?
There is currently active litigation on both these points, with artists, authors, and other creators suing the makers of the biggest GenAI apps in the world (like OpenAI, Microsoft, Meta, and StabilityAI). So far what we’ve learned from the cases is that most judges seem to agree that the resulting work created by the GenAI does not infringe copyright, because it is unique and distinct enough from the original copyrighted work. Furthermore, LLMs are trained on vast amounts of data, so there is no likelihood that there is any direct copying of one particular original work to create the outputs.
With regard to using copyrighted works to train an LLM, no decisions have been made yet, but Google recently argued that using copyrighted work to learn and teach a model cannot be considered infringement. If the courts find this argument persuasive, it’ll help to settle the outstanding issues around copyright law and training LLMs.
Finally, we must look at data protection laws. We already know that there are various US laws to contend with, in addition to the EU’s GDPR. However, it’s important to note that other countries have strict and important data protection laws as well, so when you’re scraping personal data from across the globe be mindful of this point. GDPR tends to be the most stringent law, so if you apply GDPR to your analysis you’ll typically be on the safer side of things. Completely eliminating personal data from a project of this scale would be virtually impossible, so under GDPR we must have a lawful basis to process the personal data. As mentioned before, the most likely lawful basis in a web scraping project would be legitimate interest. Most companies training LLMs with large volumes of personal data are currently relying on this lawful basis. You will need to ensure that you conduct an LIA and a data protection impact assessment (DPIA) in this case. The reason is that the level and nature of personal data you are processing is so vast that you will want to have the additional protection of that assessment in place. You will also want to place clear notices regarding the personal data you are processing.
We will have more guidance from the various EU data protection authorities soon, as many are looking at this issue right now. But for now, make sure you have a data protection professional looking at this closely for you.
Now you have some clear steps to take to assess the compliance of your web scraping projects. For more helpful resources, check out my posts on the legality of web scraping and our more detailed Compliant Scraping Checklist.

Explore, connect, and collaborate with Zyte. Join us on LinkedIn and in our Extract Data Community on Discord.
 | A guest post by
|
Quick reality check... How many individuals have "data protection professional" on their side?