
The Lab #34: Bypassing Datadome - End of 2023 Version
Is it possible to bypass Datadome today?

Before starting with the main topic of the article, where I’ll try some approaches to scrape data from a Datadome-protected website, let me remind you of a webinar by Smartproxy, coming out in the next few hours. I’ll be there with Fabien Vauchelles, Martin and Ivan talking about efficiency in web scraping operations.

Here’s the link to save your seat for free, hope to see you there in a few hours from now.
An Intro to Datadome Bot Protection
Datadome is one of the most advanced anti-bot solutions available on the market and, in my opinion, also the one that uses behavioral analysis in the most aggressive way. In fact, it’s not rare to be blocked by their CAPTCHA in the middle of a scraping session (but also in the middle of a human browsing session, which is not that good for the UX of websites).
It uses all the most well-known techniques to detect bots, for example, TLS fingerprinting and AI, as mentioned before.
For this reason, starting a web scraping project when a website is protected with Datadome is always a lottery ticket, you won’t know until the end if you’ll be successful in scraping the data you’ll need.
It will depend on the setup of the solution on that particular website and this is true also for this article: I wanted to demonstrate I could scrape data from Footlocker UK, but I’m not sure I’ll be able to do it. Ready to discover it?
Disclaimer: all the techniques we’ll see in this article must be used in a legal and ethical way, without causing any harm to the target website. If you have some doubts about the legality of your web scraping project, have a look at the compliance guide and ask your lawyers any questions specific to your task.
First try: Scrapy-impersonate
There’s no need to waste time by trying to use traditional requests with Scrapy since they’re blocked 100% for sure by Datadome, but I wanted to try Scrapy-Impersonate, even if I’m not so confident that it will work.
2023-12-03 17:17:48 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://www.footlocker.co.uk/en> (referer: None) ['impersonate']
2023-12-03 17:17:48 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 https://www.footlocker.co.uk/en>: HTTP status code is not handled or not allowed
2023-12-03 17:17:54 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://www.footlocker.co.uk/en> (referer: None) ['impersonate']
2023-12-03 17:17:55 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 https://www.footlocker.co.uk/en>: HTTP status code is not handled or not allowed
2023-12-03 17:18:01 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://www.footlocker.co.uk/en> (referer: None) ['impersonate']
2023-12-03 17:18:01 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 https://www.footlocker.co.uk/en>: HTTP status code is not handled or not allowed
2023-12-03 17:18:01 [scrapy.core.engine] INFO: Closing spider (finished)I’ve looped three different browsers to impersonate, but it’s not working. We need to move on to the next idea.
Second try: Browser automation with Playwright
Let’s use a real browser to load the website and see if we can bypass the anti-bot protection.
def run_play(playwright: Playwright):
browser = playwright.chromium.launch_persistent_context(user_data_dir=USER_DIR, channel='chrome', headless=False,slow_mo=2000,args=CHROMIUM_ARGS)
page = browser.new_page()
url1='https://www.footlocker.co.uk/'
page.goto(url1, timeout=0)
interval=randrange(3,5)
time.sleep(interval)
url1='https://www.footlocker.co.uk/en/category/men/shoes.html'
page.goto(url1, timeout=0)
interval=randrange(3,5)
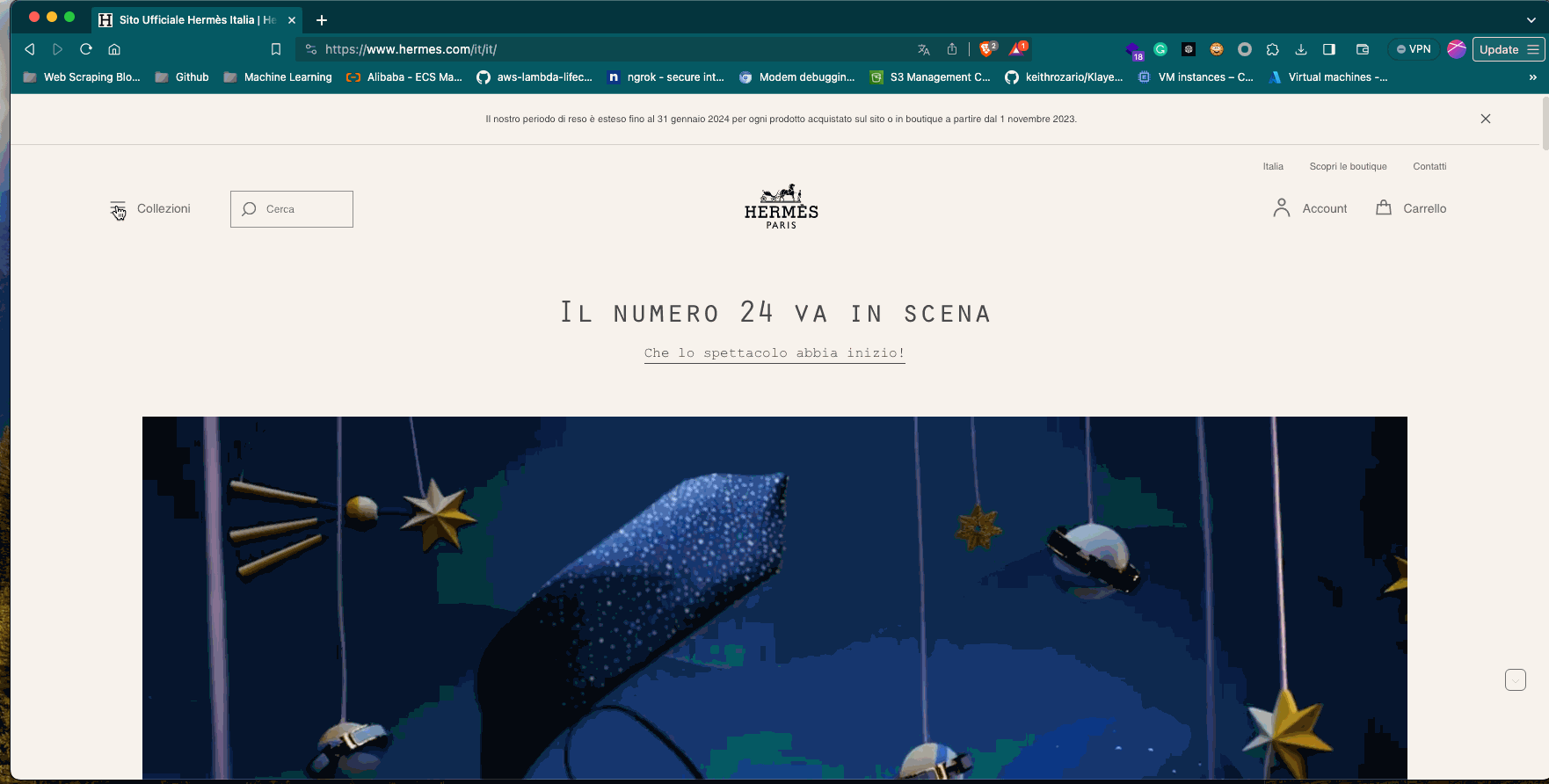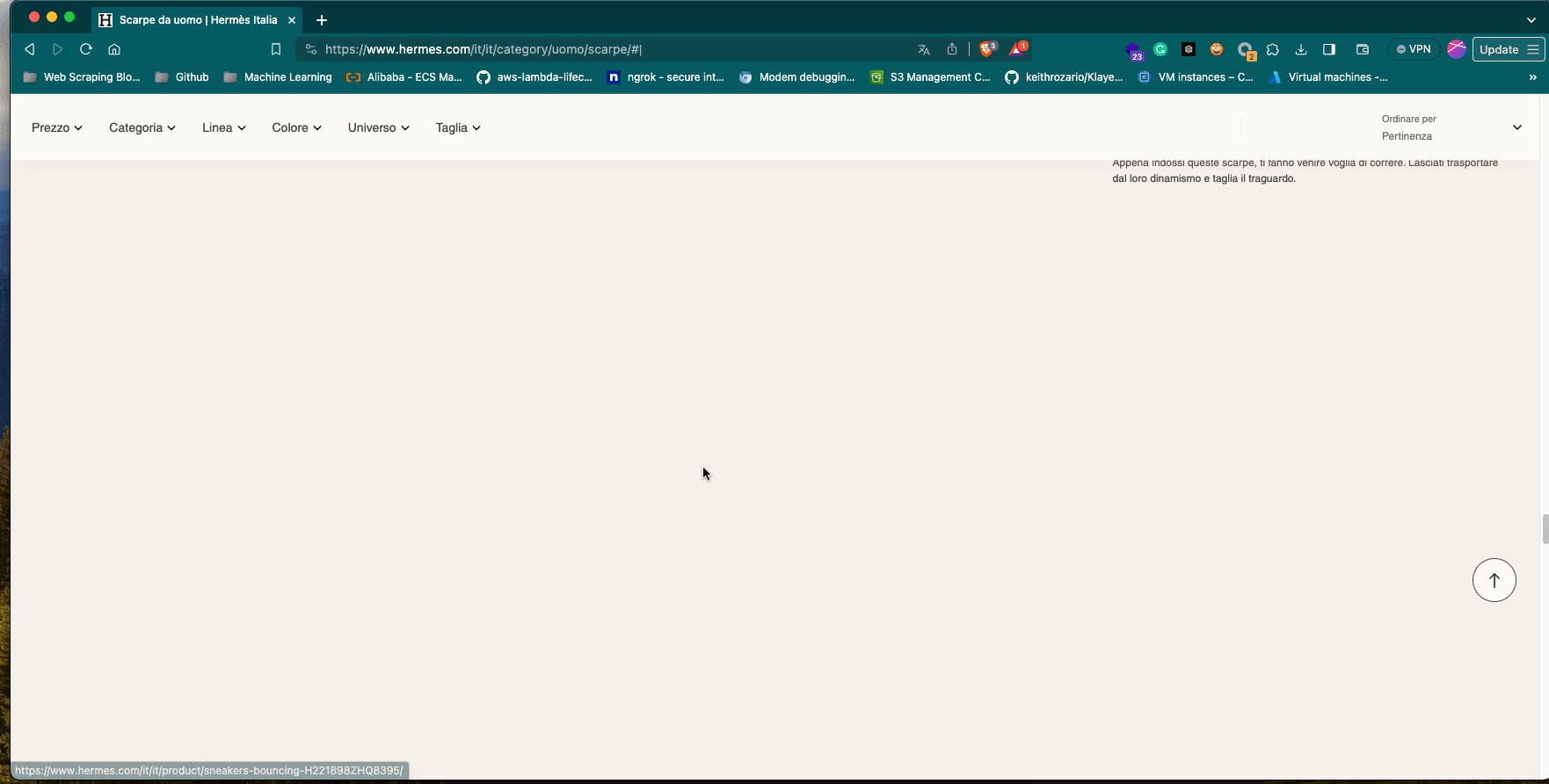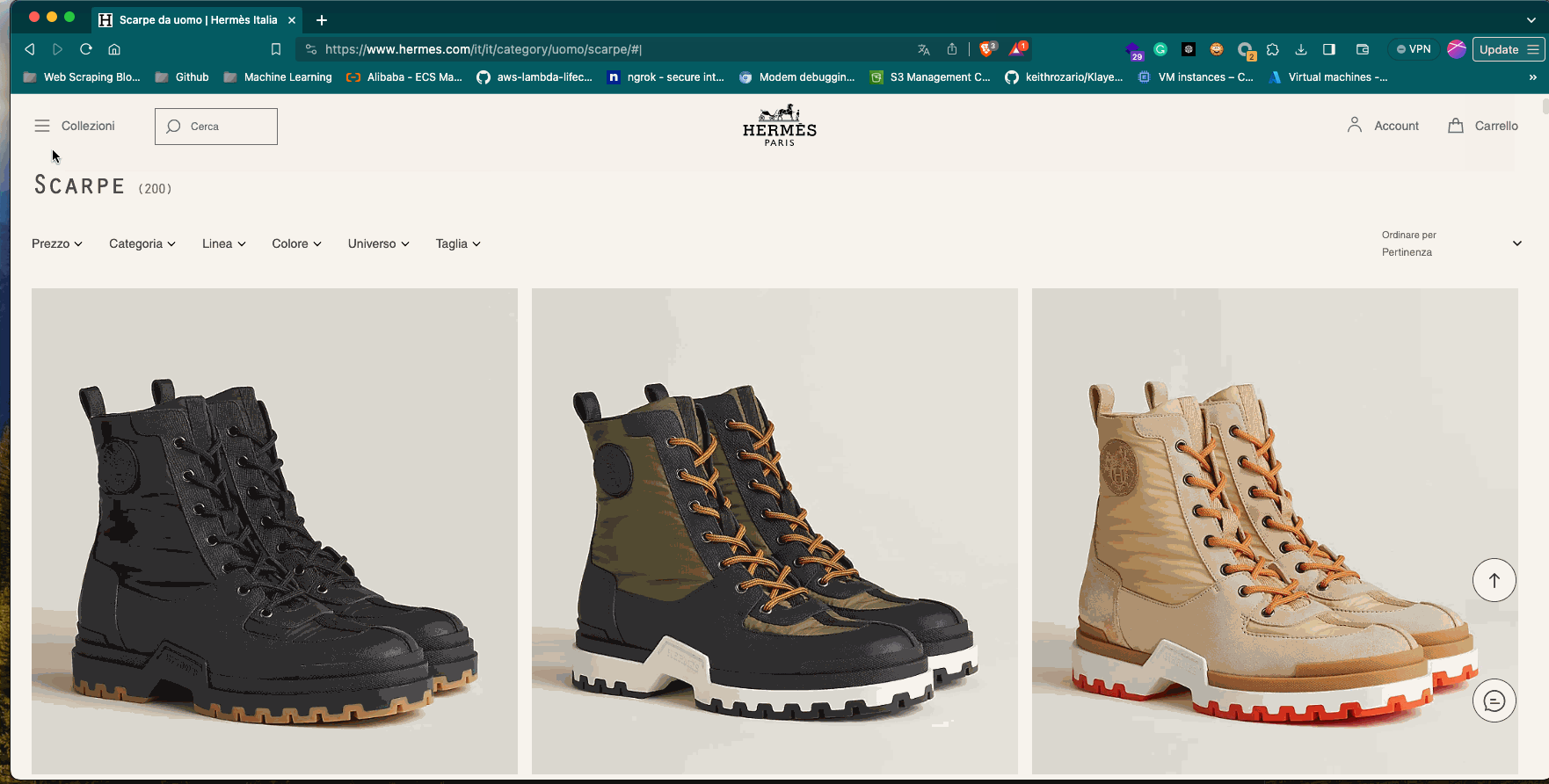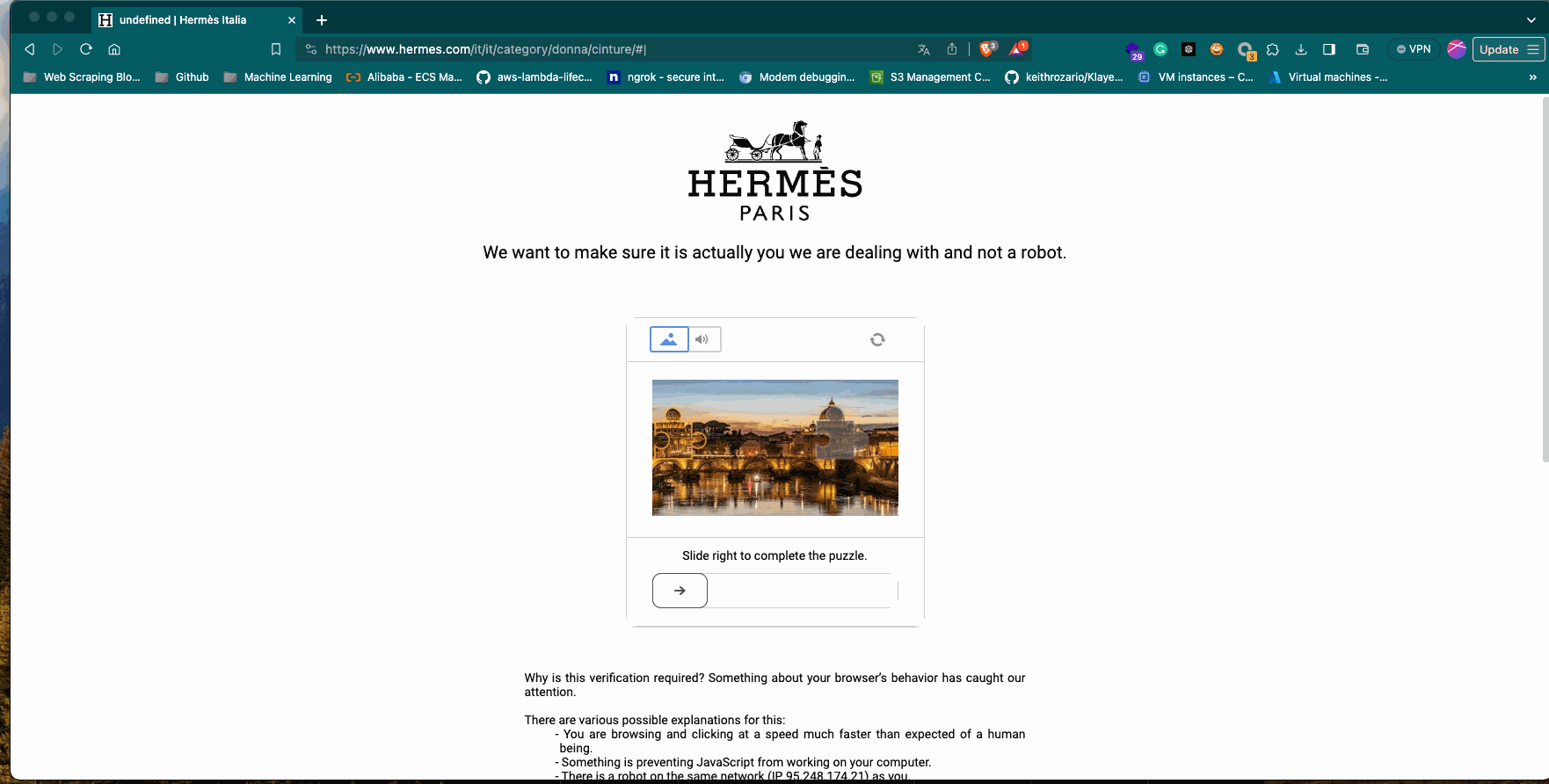
time.sleep(interval)We have mixed results since we can load the first page but then, when we try to load the second one, there’s the Datadome CAPTCHA blocking us. It seems that the scraper is not detected as suspicious but its behaviour is.
Instead of opening the second page directly, which is not a standard behaviour for a human. In fact, after opening the home page, we’re usually moving our mouse around to navigate the website and we’re not writing down a new URL in the address bar.
