
THE LAB #24 - Bypassing Akamai using Proxidize
Scraping H&M website to collect e-commerce data, in a reliable way.

Some months ago I wrote about how to bypass Akamai using datacenter proxies and we have that, using the right pool of proxies, we could scrape the whole Zalando website.
Since we were using the Product List Page to scrape the website, we could minimize the number of requests to the website and, consequently, the GB used, keeping the proxy cost under five dollars per run.
But what happens if we need to scrape a website using the product detail pages, making many more requests, and using more GB?
Thanks to Proxidize, we can test on these pages a new approach for this type of situation.
What is Proxydize and how it works
Proxidize is a hardware and software solution to manage a fleet of mobile proxies. After ordering your solution, you’ll receive a mini PC that acts as a server, a rack of USB ports, and the number of modems you’ve chosen in the order.

Setting up the Proxidize environment
Before turning everything on, I needed to buy 5 SIMs here in Italy, since Proxidize doesn’t provide them. The recommendation is to buy them from different carriers, and my personal advice is don’t make any long-term data plan unless you’re sure that everything works after the activation. In fact, I’ve had four different carriers in my modems but for some reason one of them was not working on Proxidize while working perfectly on phones and other 4G routers.
After you’ve got everything you need, you need to schedule a call with the onboarding team, where they set up your configuration and activate your subscription.
Basically, they open your router’s ports to make the Proxidize modems and Dashboard accessible from the outside.

From there you can set up everything you need, from the IPs rotating interval for each proxy to the auto shutdown and read the activity log.
At first instance, I didn’t understand why I needed to connect also the server to the web, but reading the FAQ on the Proxidize website cleared my ideas.
This is the actual data stream of a typical Proxidize installation
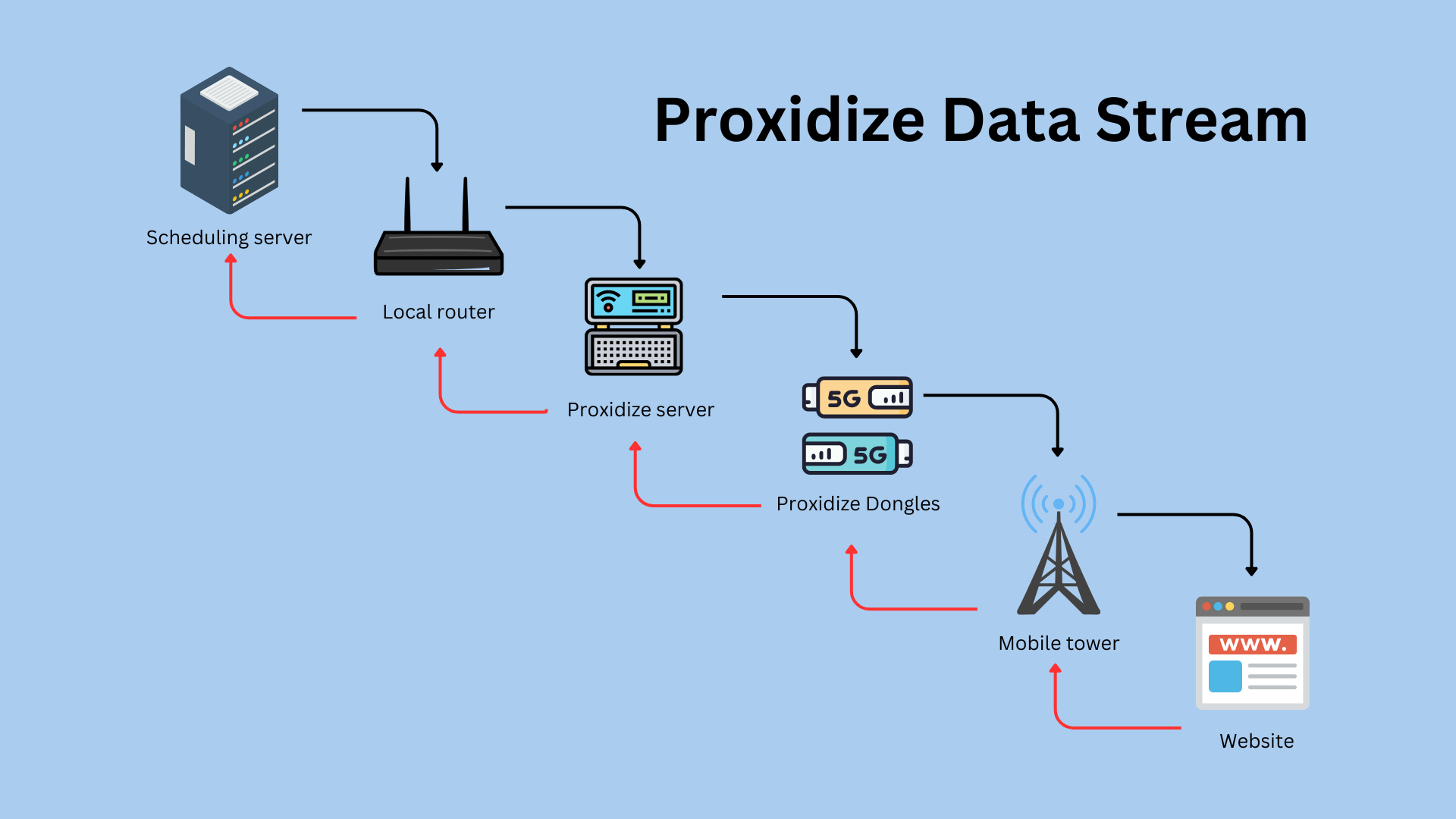
From the scheduling server, where your scraper is running, you connect to the Proxidize server via the local router, which redirects the requests randomly to the dongles. From there, the requests via the mobile network reach finally the target website. The responses make the inverse path.
If we substitute the local router and use the Proxidize dongles also to connect the Proxidize server to the web, it would mean doubling the traffic on them.
Setting up the scraper
Integrating the proxies in your scraper is a piece of cake. You can connect to the proxies using the public IP and the port assigned by your Proxidize server, with the user and password you’ve set.
There’s also the option of using the proxy pool address, a sort of load balancer that redirects the traffic to one of the available dongles and allows you to use only one address.
For scraping the H&M website we’ll use a Scrapy spider with the advanced-scrapy-proxies Python package.
Since we need to extract as many details as possible for each product, we’ll need to enter every product page, using approximately ten GB of traffic per run.
As usual, the code of the scraper can be found in our GitHub repository available to premium subscribers.
Our test
As we have seen in the previous post about bypassing Akamai, there’s no real challenge if not having a good proxy pool for rotating IPs enough to be not blocked, perfect for testing a proxy solution.
The real challenge comes from the correct setup of the proxies on Scrapy, adapting the options to the Proxidize setup pros and cons.
H&M website has more than 20k items, available in multiple sub-categories on the menu. Since we need to map every product category, we want to collect the same item multiple times with different category trees, so we say that the overall number of requests surpasses 100k.
We have seen that Akamai temporarily bans IPs after a few requests so we’ll need to rotate the IPs on our Proxidize dongles quite often, considering I’m working with only four dongles.
After several back and forth, I’ve opted for this configuration on the Proxidize side.

As you notice, I choose to rotate proxies after a few minutes, at different intervals for every proxy, using prime numbers to minimize the chances to have more than one proxy rotating in the same minute.
On the Scrapy side instead, we need to make the spider more resilient to the temporary unavailability of the proxies.
First of all, we cannot use the proxy pool as a load balancer. Given the few modems we have and the high frequency of the IP rotation, we could have minutes where there isn’t any proxy available. This causes the failure of the scraper: it retries to use the same proxy address a number of times until it reaches the value of the RETRY_TIMES parameters in the settings.py file. When it is reached, the address is deleted from the proxy list and no more used in the execution, but being the only proxy in the list, the scraper terminates. We set the value to RETRY_TIMES to 50 but it’s not recommended to use higher values, because the spider could hang for other reasons and you’re wasting GB to retry requests that won’t be successful.
We’ll use then the list of proxies, so we created a file called proxy.txt, with the list of the four proxy addresses.
http://$USER:$PWD@MYIP:2001
http://$USER:$PWD@MYIP:2002
http://$USER:$PWD@MYIP:2004
http://$USER:$PWD@MYIP:2005While USER and PWD will be substituted at runtime, MYIP is the specific IP of the proxies.
So using the command
scrapy crawl spidername -s PROXY_MODE=0 -s PROXY_LIST='proxy.txt' -s REMOTE_PROXY_USER='MYUSERNAME' -s REMOTE_PROXY_PWD='MYPASSWORD' we can securely use the list provided but, at the same time, we must pay attention to one detail in the scraper.
yield Request('https://www2.hm.com/'+subsubcat['href'], callback=self.parse_category, meta={'location': response.meta.get('location'), 'currency_code': response.meta.get('currency_code'), 'cookiejar': response.meta.get('cookiejar'), 'base_url': response.meta.get('base_url'), 'category1': category1, 'category2': category2 })Every time we make a request, we’re not passing the whole previous response.meta but we’re passing only a selection of fields. This is because in the response.meta there’s also the ‘proxy’ field and, in the case of unavailability of the proxy, the request will be repeated using the same proxy. If we don’t pass the proxy field in the meta, instead, the proxy for the retry is again chosen randomly.
Last but not least, since we have a very small proxy pool, even if we took all the previous precautions, it could happen that a proxy is detected as unusable after several unsuccessful retries for the requests.
For this reason, we’re using another trick contained in the advanced-scrapy-proxies Python package. Instead of using a local list of proxies, we’re using the same list but hosted on AWS S3.
When I modified the original package, I introduced this feature which allows people to use a list of proxies that’s generated dynamically and changes over time. Before every request, the list is downloaded and read entirely, so in our case, even if the list is always the same, is read at every request, and no proxy is set as unusable.
To do so, we need to modify the launch of the scraper in this way.
scrapy crawl spidername -s PROXY_MODE=3 -s PROXY_LIST='https://url/proxy.txt' -s REMOTE_PROXY_USER='user' -s REMOTE_PROXY_PWD='password'Using all these precautions, the scraping of H&M website runs smoothly, using the Proxidize infrastructure.
Final considerations on Proxidize
When testing any solution, we need to consider also its context and the test itself. In this case, I’ve put the Proxidize infrastructure under heavy stress, considering that I’ve used a pool of four proxies (since one of the SIMs didn’t work) for scraping a website that usually requires a larger pool.
Said that, with some fine-tuning on the scraper, this solution performed extremely well and completed its task. But is this a solution I would recommend? As always happens in this industry, there’s not a single and definitive answer. It depends on your needs, your budget, and your scope.
Your needs
There are two main aspects, regarding your needs, that should be considered when choosing between Proxidize or other traditional proxy solutions.
Basically, you’re building your own proxy infrastructure in your office, so first of all you need to consider your proxy usage.
With great proxy usage, creating your infrastructure should be something you could consider, also because of a cost perspective, which we’ll see later. We’re talking about physical hardware placed in your office, so it will take some maintenance and also to be placed where there’s no electric and network discontinuity.
Last but not least, all the proxies are placed in the same physical location, so if you need to bypass some geofence by using IPs from a specific country, probably it’s not a solution for you.
One strong point in favor of the Proxydize solution, instead, is that you can connect mobile phones to the rack and use them to host a proxy, creating a more reliable fingerprint for your scrapers.
The pricing model and some math
Proxidize clearly is a service aimed at professional scrapers or companies, since the pricing disadvantages sporadic freelancing jobs.
I’ve crunched some numbers, starting from the following hypothesis: as we can see from the pricing page, each Proxidize plan has a one-off payment for the hardware and then a monthly fee. On top, you need to add the costs of your data plans for the SIMs.
Trying to make a meaningful comparison, we compared the prices of the 20 modems kit (I’ll call it medium) and of the 80 modems kit (I’ll call it large) against average prices of datacenter, residential and mobile proxies from major vendors.
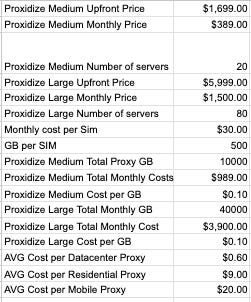
We’re also assuming that we can find data plans with 500GB per month at 30$, which is more or less what we can find here in Italy. We can see that by adding the monthly cost of Proxidize to the data plan cost, we’re going to pay around 0.1$ per GB, much less than any kind of proxy. Of course, what makes Proxidize convenient for our business is the scale of our operations, if we use enough GB to absorb the one-off initial payment.
I’ve put down some scenarios, considering a growing usage of GB and the total cost of ownership of one year for each case.
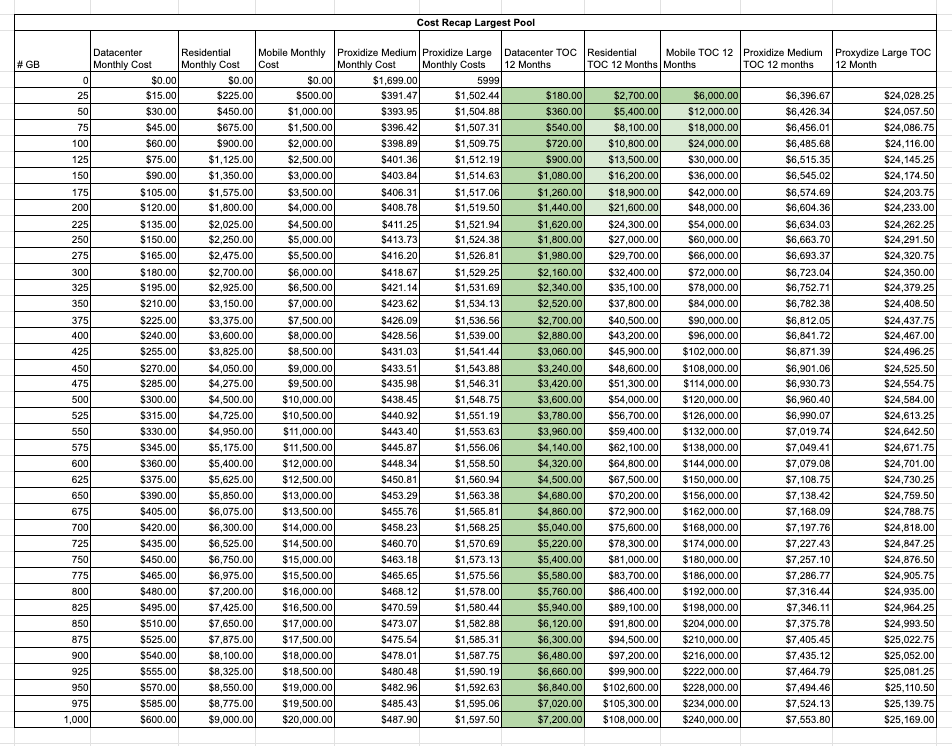
While datacenter proxies are always convenient (up to a TB of usage) compared to Proxidize, residential proxies are starting to become less appealing at around 100GB of usage. In this case, a 20 modems solution is less expensive and provides IP with better quality. After 200 GB of usage, also the 80 modems solution is always less expensive.
Comparing apples with apples, if we use more than 100GB of mobile proxies, we should consider the Proxidize solution as well, even the 80 modems one.
Final remarks
In this post, we’ve seen how to scrape an Akamai-protected website like H&M with a scraper that requires heavy usage of proxies. We used Proxidize as a proxy provider, installing their hardware here at my office and configuring all the network stuff needed. Due to the peculiarities of the configuration, I needed to adapt the scraper to handle the unavailability of proxies, but this is because I had only 4 of them up and running.
As we have seen from the prices, the solution aims to conquer companies and professional scrapers, while it’s inconvenient for sporadic freelancing.
I have only two concerns about the solution:
the fact that all proxies are in the same country can be inconvenient for many people working with social networks or bots who require different locations. What about a marketplace where Proxidize customers can exchange/rent their traffic in their country with other users in other countries? It’s just an idea, but this could overcome the geographical limit.
there’s a single point of failure, which is the Proxidize server. If it’s disconnected from the power grid or the internet for some reason, you’re not able to use proxies anymore. While for the power grid there’s nothing that can be done except to buy a power bank, for the network maybe it could be useful the presence of a sort of emergency mode. If the server is disconnected from the internet, it could use the router’s network at least to keep them working. You won’t be able to connect to the dashboard from the internet (but could always do from the intranet), but at least proxies keep working.
But if you’re using a great amount of GB of residential/mobile proxies for your operations and don’t have any need for some country-specific IP address, I would seriously consider the Proxidize solution.
All the comments and content of this article comes from my few days of experience with Proxidize so, if anyone finds it inaccurate, I’d be happy to correct it.
Excellent review!