
THE LAB #22 - Scraping Akamai protected websites
How Zalando and Rakuten use Akamai to protect its website and how to bypass this solution

July is the Smartproxy month on The Web Scraping Club. For the whole month, following this link, you can use the discount code SPECIALCLUB and get a massive 50% off on any proxy and scraper subscription.

Zalando: a bit of context
If you’re living in Europe, probably Zalando is a name you’ve already heard, even if you're not a fashionista.
In fact, it is one of the most well-known European Fashion e-commerces, born in Germany but now it serves all the major countries of the old continent, also listed on Frankfurt Stock Exchange.

Due to its importance in the industry and its dimension as a player, it’s one of the most interesting websites to be studied by different actors.
Firstly, if you want to understand where the fast fashion, sportswear, and apparel industries are going, it could be a good litmus paper, with its 1.3 Million items available on the website, coming from 6300+ brands.
It’s also a traded company and the changes in its offering and discount levels could be a good signal about how operations are running, without the need to wait for any official update.
For all these reasons, Zalando is a hot topic in any market research project in the apparel industry, and this means a lot of people are trying to scrape it. But this is not so easy, both for the dimension of the website and due to the fact that it is protected by Akamai anti-bot software.
In case you’re interested in getting the data without worrying about the scraping process, with no commitment and at any frequency, you can find it directly on the Databoutique.com website, otherwise, we’re seeing now how we can bypass the Akamai bot protection.
If you think someone you know could be interested in these topics, invite him to The Web Scraping Club
The more people you bring in, the greater benefit you’ll receive.
And if you want to be sure to don’t miss any further articles, subscribe for free to the newsletter.
Akamai Bot Manager: how it works
Akamai is a company born in 1998 and its main focus in the early days was to build a strong content delivery network (CDN). Basically, they replicate the websites of their customers in different geographical areas, so that the content is nearer to the customer, which can access it in a faster way and lift traffic directed to the main web server. Over time, the company added additional services over time, like the bot manager.
Its functioning is pretty standard, as described on their website
Bot Manager has visibility into more than 30 billion bots a day. It generates a score from 0 (human) to 100 (bot), looking at all anomalies, starting with the very first request. As the number of requests from the same bot increases, the score can also increase. This capability allows you to define a response strategy for different actions to be applied, based on the Bot Score. The strategy is defined in three response segments: Cautious Response (which should be watched), Strict Response (which should be challenged), and Aggressive Response (which should be mitigated). You can tune the score at which each of these response strategies apply, and you can also adjust the action that gets applied. Akamai evaluates every bot against every detection, giving you more insight into why it was classified as a bot, so you can strategically adapt your protections.
As we can understand, each website can react in a different way to a scraper, depending on the rules it sets against them.
In my experience, having worked mainly on scraping e-commerce websites, without the need of logging in, I’ve never had any browser automation tool like Playwright to bypass Akamai Bot Manager, so I suppose the protection works best in preventing bots from logging in and automatically ordering items rather than just scraping.
How to find out if a website is protected by Akamai?
Finding out if a website is protected by Akamai is pretty easy, especially using Wappalyzer browser extension.

But even having a look at the cookies created by a website, if you find out that _abck and ak_bmsc cookies are being set, this is a clear sign of the Akamai bot manager tool.
How to bypass Akamai bot protection on the Zalando website?
As mentioned before, if our task consists in scraping Zalando products’ prices, we won’t need any fancy solution.
The real technical challenge consists of its dimension since it has 1.3M products on sale.
So let’s start by scraping with a simple Scrapy spider, modifying the default headers to make our requests similar to ones made by a human.
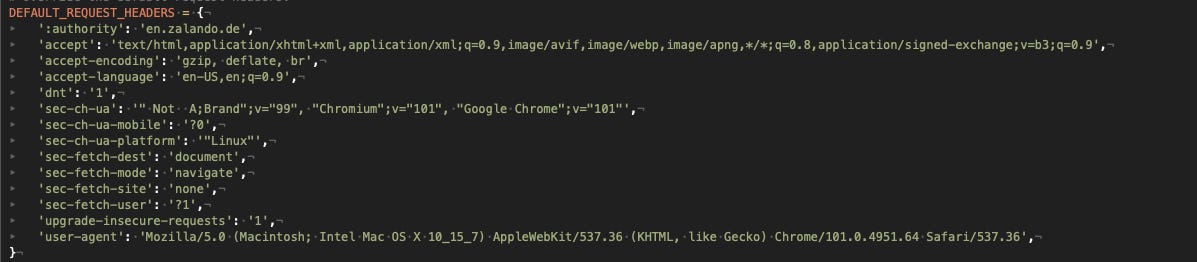
We’ll give in input a list of product categories pre-scraped from the website and filtered. In total, we have more than 260 URLs in input. We do so, in case we want to split executions in different machines, each one with a set of categories.
The scraper itself it’s pretty basic: every product listing page has a JSON data structure inside the HTML, and we can use it for our purpose.
<script type="application/json" class="re-data-el-hydrate">As always, you can see the full code on the GitHub repository available for paying subscribers.
If we run the scraper locally, it works but it takes too much time to scrape the whole website and it’s not feasible to run it in a production environment.
But if we move it to a server and run it from there, we soon get blocked with some 403 errors after a few requests. Why does it happen?
While the scraper is the same, the environment where it runs is different, so it could be an IP issue or a fingerprint marked as a bot in Akamai, or a combination of factors. But the thing is that we get blocked after some calls, not at the first one, so our scraper doesn’t get immediately get flagged as a bot.
I suppose then it’s a mixture of yellow flags coming from the requests’ fingerprints and their speed of scraping. Connecting from a data center to a website is much faster than doing it from home and doing so from the same IP raises a red flag for Akamai.
My actual solution
With these considerations in mind, I’ve started my experiments to find a solution, starting with the cheapest one. Let’s use some data center proxy in the execution so that the requests come from different IPs.
To do so, first I’ve added the advanced-scrapy-proxies package to integrate Smartproxy solutions in Scrapy.
We start by including the middleware in the settings.py file
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 90,
'advanced-scrapy-proxies.RandomProxy': 100,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110
}and creating a smartproxy.txt file containing the URL of the datacenter proxy endpoint, using USER and PWD variables instead of real ones. In this case, I’ve added several pools of addresses to maximize the number of IPs used.
http://$USER:$PWD@gate.dc.smartproxy.com:20000 http://$USER:$PWD@all.dc.smartproxy.com:10000 http://$USER:$PWD@eu.dc.smartproxy.com:20000 http://$USER:$PWD@de.dc.smartproxy.com:20000 http://$USER:$PWD@ro.dc.smartproxy.com:20000 http://$USER:$PWD@nl.dc.smartproxy.com:20000 http://$USER:$PWD@uk.dc.smartproxy.com:20000 Now, when we call the scraper, we need to explicitly say that we’re using the address contained in the smartproxy.txt file, substituting the variables with the real values.
scrapy crawl zalando -o output.txt -t csv -s PROXY_MODE=0 -s PROXY_LIST='smartproxy.txt' -s REMOTE_PROXY_USER='MYREALUSER' -s REMOTE_PROXY_PWD='MYREALPWD'For a detailed explanation of the options, you can have a look at the GitHub page of the package. In this way, you can store without any issue your code on GitHub without the worry of sharing your proxy username and password with anyone, since you use them only at runtime.
After adding the data center proxies to the scraper, the execution on the AWS cloud virtual machines run without any issues and we gathered all the records we were expecting.

But what about the costs?
