
THE LAB #20 - AI powered web scrapers with Nimble Browser
How artificial intelligence makes web scraping easier

This is the month of AI on The Web Scraping Club, in collaboration with Nimble.
During this period, we'll learn more about how AI can be used for web scraping and its state of the art, I'll try some cool products, and try to imagine how the future will look for the industry and, at the end of the month, a great surprise for all the readers.

And we could not have a better partner for this journey: AI applied to web scraping is the core expertise of the company and I’m sure we will learn something new by the end of the month.
Together with our partner Nimble, we’re thinking about a hackathon by the end of the month. Please answer the poll if you’re interested (or not) so it helps us set our expectations.
In the previous post, we talked with Uriel, founder of Nimble, about AI applied to the web scraping industry. Today we’re going to see what it really means and how it makes our life as web scraping professionals easier.
Scraping to find a deal: a personal story
Some months ago I needed to buy a new TV and suddenly entered the rabbit hole of bargains and offers from electronic retail chains. It doesn’t look like a great story, I know, but it makes me understand a little better the dynamics in this field. I will skip the fact that every large electronic retailer here in Italy, for this TV model, made different prices between online and the physical store, fueling an internal channel competition between the same company (not really a good omnichannel approach).

Google Shopping isn’t always right
The first thing I did regularly was to use Google Shopping to check prices, but it approach has some downsides.
First of all, you get only sponsored content. Retailers send to Google a feed of data they want to promote and then Google shows it to you. But not every retailer is doing so, as an example I didn’t see prices from Amazon and other smaller shops.
Strictly related to the first point, data is not always up-to-date. Since I’ve noticed prices on the retailers’ websites change even two or three times per day, Google has some delay in showing you the latest one.
I didn’t think that even TVs were subject to this intra-day dynamic pricing but I’ve seen it happening. Some retailers adopt web scraping to check their competitors and as soon as they find one of them with a lower price, they quickly adapt. One retailer always rose the price of this TV after 8 PM and then lowered it again the next day if a competitor had some discounts.
Price aggregators are not always right
Price aggregators work similarly to Google Shopping, and so have the same downsides. They are typically, at least in Italy, more complete than GS, probably because of a different revenue model. They generally get paid per click generated to the target website, so it’s free advertising for every website unless the price catches the eye and gets clicked by the potential customer.
Given the multitude of websites sending the data feed to aggregators, the research page often leads to incorrect results. Maybe you’re looking for a specific TV and then you see different similar products but with different specs listed together.
To make this story shorter: to address these data quality and timeliness issues, the solution was to write my own scrapers. That’s exactly what I did, but only in a partial way since there were too many challenges and little time to work on this personal project:
Writing one scraper per website is time-consuming
Cloudflare protects some websites, so they require additional work to bypass the challenges
If you scrape too fast Amazon, your IP gets quickly banned
You need to maintain the scrapers in case websites change. It took several weeks of monitoring for me to get the TV at the price I wanted (yes, don’t call me crazy please).
If you think about these issues, they’re not so different from the ones encountered in any web scraping project, at any scale, in every company. Your staff needs to be skilled to complete a web scraping project, have tools for bypassing anti-bot challenges like proxies, and have time to write and maintain over the following months the scrapers. The compound effect is that today, every web scraping project becomes expensive for a company.
AI comes to help
AI is entering everywhere nowadays, from generating content to increasing productivity for manufacturers. Of course, also web scraping is affected.
If you’re a long-time reader of this blog, you might have noticed that when talking about AI in web scraping, not being an expert, my articles always sounded like “Yes, that's great, but not that great”.
My main concerns can be resumed in these two points:
I’m sure a well-trained model can parse correctly the HTML code, but if I’m using a black box, how can I modify the outcome of the scraper according to my needs?
Parsing the HTML code is the easiest part, getting to it, and bypassing the anti-bots is the real challenge today.
If there was a tool that could combine the bypassing anti-bot part (like the ones we have seen in our “Hands-on series”), with the automatic parsing made by the AI and enough flexibility to change the output, what that would have been a game changer.
Well, I need to say we have something very close to this solution. I had the opportunity, thanks to Nimble, my tech partner for this AI month, to test their Nimble Browser, and I’ve been pleasantly impressed.
How does the Nimble Browser work?
The Nimble browser basically is a web driver designed from the ground up by Nimble, in order to make web scraping easier for the end users. It can be accessed via API or CDP interface, so can be integrated with any existing framework and spider.
With this description, it seems only another version of undetected-chromedriver with steroids, but the interesting features are under the hood:
runs on the Nimble infrastructure, with embedded proxy management. It means you can save money by cutting larger machines used for headful scraping with Playwright.
handles automatically the masking of the fingerprints, at any level (canvas, TLS, device, and so on)
it can return not only the raw HTML but, using AI, also a parsed version of the returned data, it can save you time when writing scrapers but also you’re able to fix what’s not working at first instance.
These premises seem a great fit for solving my TV scraping problem. With a single scraper I could get data from 5 different websites, Amazon included, using only 5 API calls and parsing the resulting JSON.
Let’s test it!
Once gotten the credentials to access Nimble’s website, the coding part is a piece of cake. As said, it takes only one request to get data, without worrying about anything.
The purpose of this test is to find the price of the TV Sony XR-65A80K on five different websites: Amazon, mediaworld.it, comet.it, unieuro.it and e-stayon.com. They have different layouts and different anti-bot protections, let’s see how the browser behaves.
The implementation is quite easy, you can find it on the GitHub private repository available only for paying readers, but this time it’s only a matter of python-requests like the following.
import json
import requests
proxies = { 'http' : 'http://$MYUSER:$MYPWD@browser.webit.live:8888', 'https' : 'http://$MYUSER:$MYPWD@browser.webit.live:8888' }
amazon_data = requests.get(
'https://www.amazon.it/s?k=sony+xr65a80k&crid=1NOVI6636HQIZ&sprefix=%2Caps%2C193&ref=nb_sb_ss_recent_2_0_recent',
proxies=proxies,
headers={
'x-nimble-render':'false',
'x-nimble-parse': 'true'
},
verify=False
)
The only peculiar options here are the headers:
x-nimble-render enables the full rendering of the page via the browser, needed to bypass Cloudflare or other anti-bots
x-nimble-parse enables the parsing of the output by AI
In fact, the JSON output contains both the parsing by AI and the HTML to fine-tune the results if needed, like in the following example.

After running the script I’ve created with the 5 requests, let’s see how the AI parsing behaves on the 5 websites.
Result 1: Amazon

You get almost everything on the page, all the product details, reviews count and rating, ASIN code, and price for each variation. The notable thing is that this JSON does not exist inside the HTML of the page but it’s composed by the Nimble AI model, which seems to be perfectly trained on Amazon.
Result 2: Mediaworld.it

In this case, the Nimble browser easily bypassed Cloudflare and returned the schemas.org available on the page. For our needs, this is enough, even if we don’t have the full price without the discount, but we can get it from the HTML. Probably the AI didn’t recognize a known pattern in the HTML but still returned a standard answer, so the result is pretty good, considering also the Cloudflare bypass.
Results 3 and 4: Comet.it and Unieuro.it
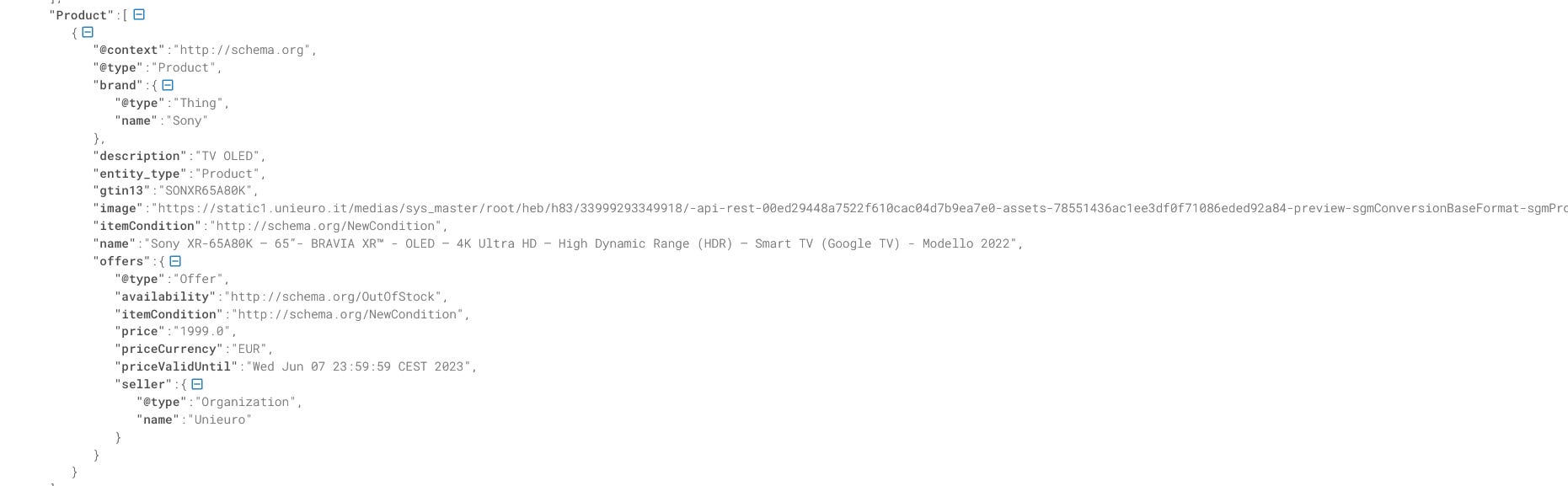
Just like for Mediaworld, the scraper returned the schema.org JSON for the product, returning what we need.
Result 5: e-stayon.com
I’ve chosen this website not because of its importance in Italy (honestly I’ve never heard of it before today) but because there is no schema.org JSON inside the HTML code, but it’s implemented using div HTML tags, something I’ve never seen before. And it’s a problem in common with the AI model inside the Nimble browser since it didn’t return anything in the parsed section of its output. In this case, we’ll need to use the HTML code to write a custom scraper.
Final thoughts
I’m quite impressed by the Nimble browser. Considering that it’s still a quite new solution with great margins to improve, it could be a game changer for the industry.
As with every AI model, the outcome depends on the training data used. Amazon, Walmart, and the other big retailer are the first choice for the training and we’ve seen in the examples I’ve chosen the difference in the quality of the output between Amazon and other smaller websites. But the answers we’ve got from the Nimble Browser API were still enough for our scope and could really save a ton of time, just in this small experiment.
Of course, all the power under the hood comes with a price. It’s a premium solution aimed at companies that need a medium/small amount of requests to be made, since at a larger scale it becomes inconvenient, even considering the savings in terms of time and work of people involved in web scraping operations.
Pros
easy to integrate with your existing architecture
fast to execute
if websites are using standards, it returns the correct data without a problem
Cons
price can be challenging for larger projects