
Web Scraping from 0 to hero: Why my scraper is getting blocked?
A playbook to handle bans during web scraping operations

Welcome back for a new episode of “Web Scraping from 0 to Hero”, our biweekly free web scraping course provided by The Web Scraping Club.
We have seen in the past articles how to create our scrapers both with a browserless solution like Scrapy and with browser automation tools like Selenium and Playwright.
During your career as a web scraping professional, you will need to be able to answer, sooner or later, this unavoidable question: “Why my scraper is getting blocked?”
Today I’ll share with you my playbook that I use daily to understand what’s happening when a block hits one of my scrapers.

Is there an anti-bot on the target website?
The first thing I check when a scraper breaks is if there’s an anti-bot on the target website. Probably you already did it when you wrote the scraper but things change over time and the analysis you made months ago may be no longer valid.
The tool I use for this is the Wappalyzer browser extension, which can detect all the most well-known anti-bot solutions and it’s free to use.
If you detect an anti-bot solution, you can look for some ideas on how to bypass it by reading past articles in this blog, otherwise, you need to dig deeper into the issue.
In case you’re using a browser automation tool on a website with no antibot, you could consider rewriting your scraper to go browserless. In fact, unless you’re in need to load Javascript or read dynamic content not available on the HTML, you can go browserless when there’s not an anti-bot, since it’s a more efficient and faster approach.
Check the proper solution for your anti-bot in our guides
If there’s an anti-bot on the target website, you have a variety of both commercial and open-source software to use to bypass it. Since the success of your web scraping solution, in this case, depends on many factors, from the settings of that particular anti-bot on the target website to the tools you prefer to use, I’m listing only the collections of articles connected to a single anti-bot, so you can experiment with different solutions.
Here is the list of articles written so far about bypassing:
How the course works
The course is and will be always free. As always, I’m here to share and not to make you buy something. If you want to say “thank you”, consider subscribing to this substack with a paid plan. It’s not mandatory but appreciated, and you’ll get access to the whole “The LAB” articles archive, with 40+ practical articles on more complex topics and its code repository.
We’ll see free-to-use packages and solutions and if there will be some commercial ones, it’s because they are solutions that I’ve already tested and solve issues I cannot do in other ways.
At first, I imagined this course being a monthly issue but as I was writing down the table of content, I realized it would take years to complete writing it. So probably it will have a bi-weekly frequency, filling the gaps in the publishing plan without taking too much space at the expense of more in-depth articles.
The collection of articles can be found using the tag WSF0TH and there will be a section on the main substack page.
Does the scraper run on your machine?
After checking if any anti-bot measure is installed on the target website, we can start the scraper on our local machine to see if it gets blocked or not, and if it runs partially before being stopped.
The scraper runs on your machine but not on a datacenter
Let’s suppose now that the scraper runs correctly until its end on your local machine but not on your production enviroment, which is probably a server on a datacenter.
This means that the scraper itself has no issue but the website recognizes something about our running environment that doesn’t like. The next question is: is the scraper browserless or uses an automation tool?
The scraper is browserless
If the scraper is browserless, there are few things that can trigger the counter-measures from the target website.
The most common cause is the datacenter IP you’re using: I would try to add residential proxies to your scraper or, if you can operate on multiple datacenters, move to another one before trying residential proxies.
In fact, some cloud providers like AWS, share the lists of the IPs of their subnets for every region and these can be used by websites for blocking requests coming from AWS datacenters.
The scraper uses a browser automation tool
If your scraper uses a browser automation tool, on top of the scraper’s IP discussed before, we could have a fingerprint issue.
In fact, the target website recognize you’re running a scraper from a datacenter by gathering informations from the browser’s API, like sound and video devices and WebGL renderer. This usually means there’s an anti-bot installed, so I’m suggesting you to read the related articles for the anti-bot installed on the target websites and how to spoof your browser fingerprint.
The scraper doesn’t run even on your machine
If the scraper doesn’t run from your local machine, the first thing to try is if we can browse the website from our browser, to check if our IP has been blacklisted or not.
Once checked that our IP is not banned and that there’s no anti-bot solution, depending if our scraper is browserless or uses a browser automation tool, we have several options.
The scraper is browserless
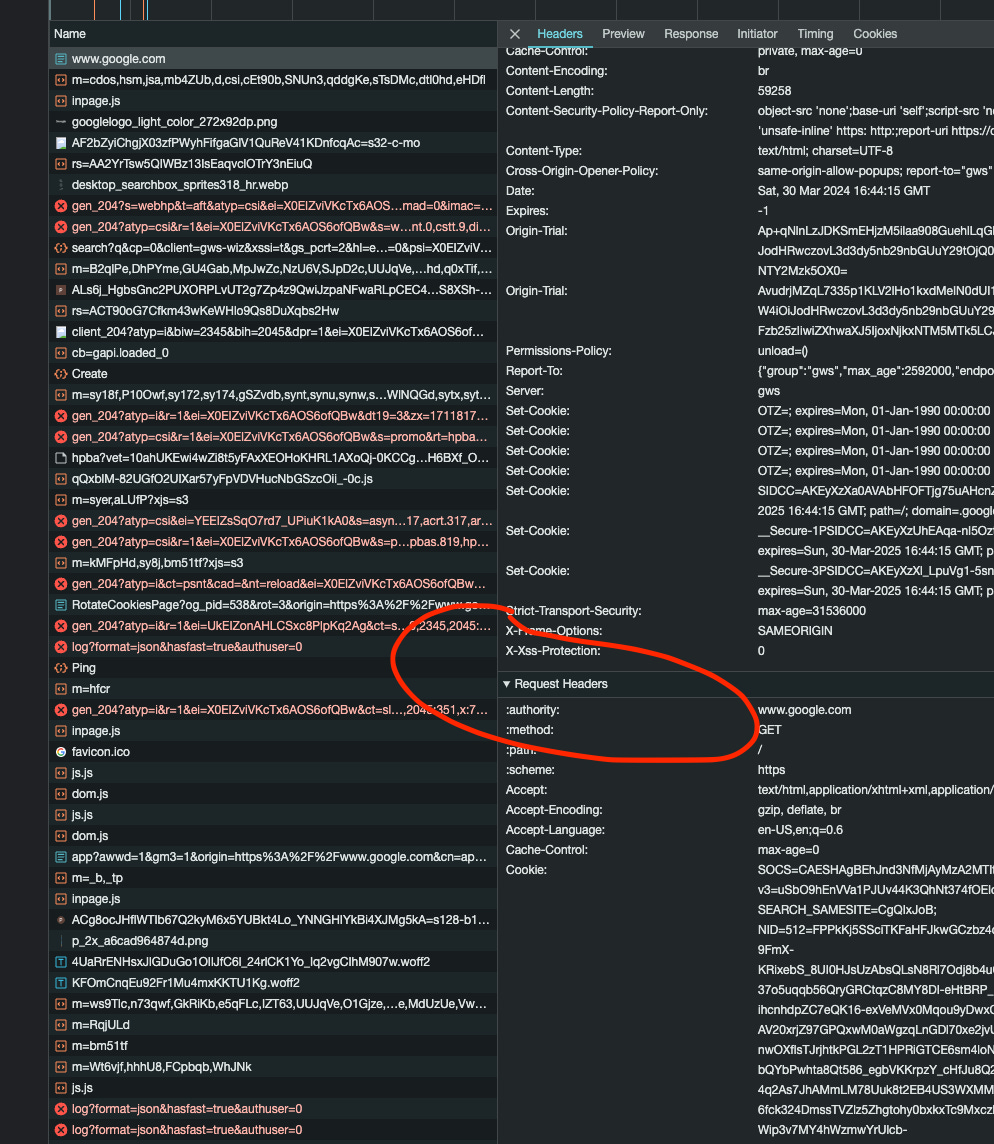
If the scraper is browserless, probably the website expects different headers than the ones we’re sending with our requests.
To test if this is true, it’s enough to copy the request headers from the browser’s network tab of the developer’s tools and use them in the scraper.
The scraper uses a browser automation tool
If the scraper uses a browser automation tool, there’s no reason why it should not load the target website, unless it’s a bug (or you didn’t check if there’s an anti-bot).
If you’re able to load the website using a browser, you should be able to do the same using the same browser with Playwright or another automation tool, unless there’s some misconfiguration on your setup or some bug in the scraper.
Does the scraper run for a while and then get blocked?
This is another common situation: the scraper runs for a while and then doesn’t return any record or the requests start return timeout errors. This happens especially in browserless scrapers, since they make more concurrent requests than the ones with browser automation tools.
We have some options here on the table to fix our scraper:
rate limiting: maybe the target websites rate limits the requests from a single session. Your scraper has collected a session cookie and, after a certain amount of requests in a period, you get blocked. Try to slow down the execution using fewer parallel threads and incrementing the delay of the requests.
same can be said for the IP addresses. Probably you need to rotate the IP you’re using for the requests. If you’re already using a rotating address, probably the IP pool is too small and/or the website blocks the subnets instead of a single IP (this is the case of Amazon and Google Shopping). In this case, use more providers and distribute more the requests in different geographical regions.
if the website is relatively small, consider the fact that you could have overloaded its server. Please scrape responsably and slow down with the requests.
Of course, this article could not be representative of all the hypotetical cases of why a scraper has been blocked, but it’s a small playbook you can use to focus on the tests that are more meaningful for your situation.
See you in two weeks for the next lesson of the course “Web Scraping from 0 to hero”