
XPath vs CSS selectors: a comparison
What's the difference between XPATH and CSS selectors

This post is sponsored by Smartproxy, the premium proxy and web scraping infrastructure focused on the best price, ease of use, and performance.

In this case, for all The Web Scraping Club Readers, using the discount code WEBSCRAPINGCLUB10 you can save 10% OFF for every purchase.
When creating a web scraper, one of the first decisions is to choose which type of selector to use.
But what is a selector and which type of them can you choose? Let’s see it together in this article by The Web Scraping Club.

What are selectors?
To gather data in your web scrapers, one of the first tasks is to find out where the data we’re interested in and to do this, we need selectors.
Basically, a selector is an object that, given a query, returns a portion of a web page. And the language we write this query can be XPATH or CSS.
What type of selectors there are?
Independently from the syntax we'll use, according to the structure of the web page, we have different types of selectors.
ID-based selectors, where our target object is defined by a unique ID
<span id="searchToggle" tabindex="0">Search</span>Attribute-based selectors, where our target object is defined by its attribute (like a class of objects in this case).
<span class="search-toggle-icon">Search</span> While the first is the best for determining our target object, they are often not available for every case, so we need to use attribute-based selectors using a unique path to our desired object.
How to choose a good selector?
There are some best practices to use when choosing a selector in our web scraping project:
The selector should determine a unique and unambiguous path to the target element or group of elements.
It should be clear which element the locator refers to without examining it in the code.
In our projects, especially larger ones where more people are involved, only one type of selector should be used in every scraper (Xpath or CSS)
Your locator should be as universal or more generic as possible, remaining accurate, so that if there are changes to the website, it remains relevant.
How do XPATH selectors work?
XPath (XML path) is a query language for locating nodes in an XML document. Since many browsers support XHTML, we can use XPath to locate elements in web pages.
Each element has a path from the start to the element itself, so by navigating the DOM of the page we can point exactly to our target.
XPATH expressions are composed of three parts:
Axis
Node tests
Predicates
Axis
Axis refer to the navigation direction of the expression. The most common is ‘//’ to state that we’re descending in the tree, or ‘..’ to refer to the parent node.
Node tests
Node tests may consist of specific node names or more general expressions, like ad example .text() for when we need to extract the text of a node
Predicates
They can be seen as filters, so when we specify in the following expression that we need only the items belonging to the class “class1” we are using a predicate.
string= xpath('//a[@class="class1"]/).text()Here we used all the axis ‘//’, the predicate ‘@class=”class1”’, and the node test .text
For a deeper understanding, there’s a great Wikipedia page about it, where the general concepts of XPATH are explained regardless of the programming language where it is used.
How do CSS selectors work?
Most HTML pages are built to integrate graphic layouts based on CSS and these style elements can be used to locate DOM elements.
Just as for the XPATH selectors, they can be divided in:
Universal selectors, which select all the elements on a page
Type selectors, which select all elements that have the given node name.
Class selectors, which select all elements that have the given
classattribute.ID selectors, which select an element based on the value of its
idattribute. There should be only one element with a given ID in a document.Attribute selectors, which selects all elements that have the given attribute.
A practical comparison
Let’s compare the syntax of XPATH and CSS selectors on the same page, in this case, Hacker News home page. Let’s say we want to locate the title of the first news ranked.
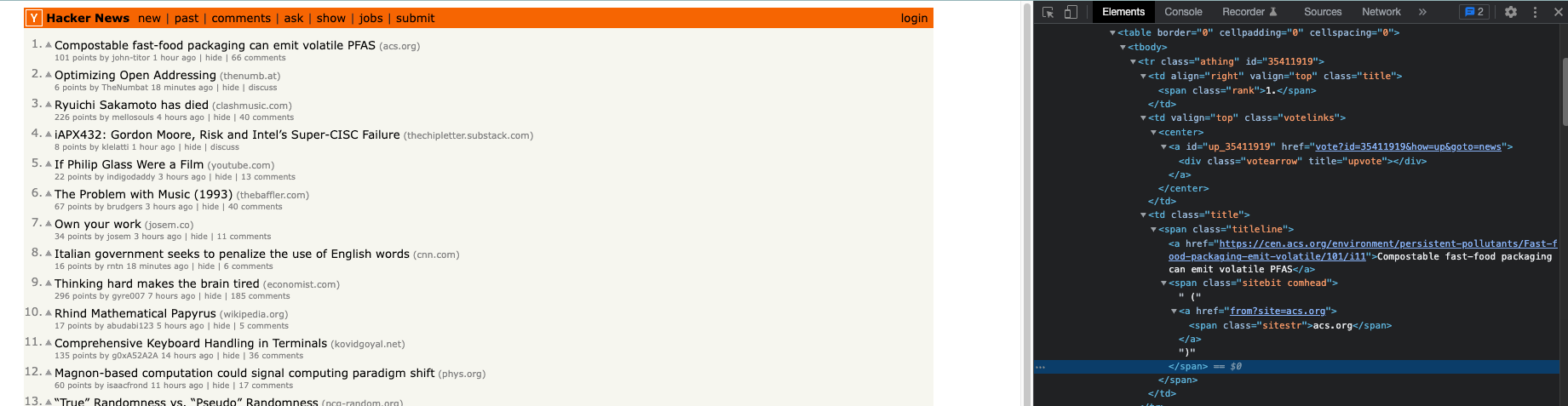
Let’s open the inspect windows and in the Elements tab, let’s right-click on the string of the first title and select “copy → copy selectors”.
Here’s the result for the CSS selectors
td:nth-child(3) > span > aWhile for XPATH we have
//td[3]/span/aIn this case, the syntax is pretty similar and clear for both of them.
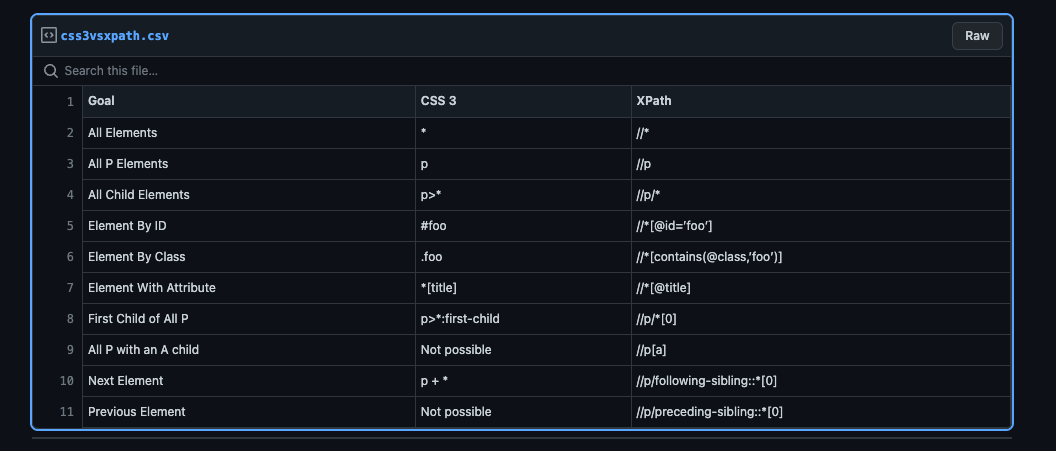
Here’s a syntax comparison table between the two.
Final remarks
Which one to use between XPATH and CSS selectors?
There’s no easy answer here and it depends on the habits and coding style of each person.
I’ve read on several websites that CSS selectors are faster but, unless you’re building an ultra-high frequency scraper, this should not matter.
The main difference between the two is that XPATH is a little more flexible since you can select items on both of the directions (descendant and parent items) while with CSS only descendants.
I’m personally a big fan of XPATH, I usually find its expression clearer than CSS but it’s mostly a personal taste, but I hope this article helped you in choosing which one to adopt in your scraping projects.