
The Great Web Unblocker Benchmark: March 2024
Which commercial web unblocker is able to bypass the most famous anti-bot solutions?

Today I’m starting a new series of articles, the great web unblocker benchmark, where I’ll test different web unblockers against the most well-known anti-bot solutions and compare the results between them.

What are web unblockers?
Web unblockers are commercial “super APIs” that allow scrapers to bypass anti-bots and rotate proxies without worrying about any tech implementation.
In fact, you just need to integrate them in your scraper, typically as you usually do for a proxy: you just set the endpoint with the credentials to use and send requests to it.
Under the hood, these unblockers typically take care of the JS rendering, Captcha Solving, IP rotation, fingerprint forging, and everything needed to bypass the anti-bots solutions.
Some of them can be used also for parsing data automatically but it’s not the case we’re going to test in this series or articles.
Testing methodology and disclaimers
The idea behind web unblockers is simple: they make the hard work for you, so you just need to call them in your scrapers and your scrapers won’t get blocked.
This brings a great advantage for web scrapers: unless the website changes its HTML, the spider won’t break in the future, even if the target website updates or changes the anti-bot protection.
Of course, this has a price: unblockers are typically expensive solutions since they’re priced per GB or number of requests, so the bill goes high soon on a large scraping project. But you need also to consider the number of hours you won’t spend fixing your code and the lightweight running environment for your scrapers since you don’t need to use browser automation tools for bypassing anti-bots or rendering Javascript challenges.
For this reason, all the tests in these articles will be made by using a simple Scrapy Spider.
I’ve created one scraper for each anti-bot protection we’re gonna face in the test, and I’ll change the API endpoint and some parameters every time I need to change the provider.
The scrapers are set to use 10 different concurrent connections at max, so the total scraping speed will depend only on the speed of the API since this setting is the same for every provider.
Since some anti-bots are known for using also the number of events inside browsing sessions, like mouse movements or clicks, I already know this could not be enough to bypass them. When you read in this test that a solution is not working against an anti-bot, this means that it’s not working using this configuration, but it could work if integrated into a Playwright scraper.
Given these premises, let’s see the engagement rules:
All the unblockers are tested using the same Scrapy spider, with different options or setups that are peculiar for each solution
The test consists of loading the home page of the target e-commerce websites, moving to a product category, and loading the pages of the first 20 items in this category. The only exception is Datadome, where I ask directly for the 20 items’ pages, otherwise the scrapers will be blocked during the navigation.
The unblockers will be tested for three KPIs: success rate, execution time, and costs of the extraction.
Results are not shown in advance to vendors, to avoid any influence on the final result. This could also lead to errors on my side: I might have missed one option that could solve the anti-bot. If this is the case, I’ll update this article, so keep an eye on it even after its publishing.
The scraping time I’ve entered in the benchmark is calculated by Scrapy itself and it’s the elapsed time of the first successful run.
This is not a paid review of unblockers, but a quantitative test. In case your company sells a web unblocker not listed here and wants to participate in the next issues of the test, please write me at pier@thewebscraping.club
Who’s participating in this round?
I postponed several times this article because I wanted to start with more vendors but it’s always a mess to synch different players and get all the accounts sorted out in the same time span.
In this edition, we’ll see, in a rigorous alphabetical order:
While their ultimate goal (bypassing anti-bots) is the same, the technology under the hood is different between each provider and so are also their pricing models.
Smartproxy and Oxylabs have a pay-per-GB pricing model, which is convenient when you’re scraping API endpoints but gets expensive when you scrape pure HTML code, like in these tests.
Bright Data, Zenrows, and Zyte, instead, have a pay-per-request model, with some differences: Bright Data charges 3 USD per 1000 requests, but they become 6 when scraping a domain included in their premium list. In our case, no one of the websites we’re testing is contained in considered so.
Zenrows uses a credit system: you’re buying credits (250k per 49 EUR) and every basic request is one credit, while the price could go up to 25 credits per request if you need premium proxies and JS rendering. During our tests, when we successfully scraped a website, we did it by using basic requests.
Zyte API has dynamic pricing calculated internally, so I could get the exact scraping cost from their dashboard.
Let’s see how they behave against the most famous anti-bot solutions.
Test 1: Cloudflare
For testing Cloudflare we’re using Harrods.com as a target website, which we used several times in the past articles here on the blog.
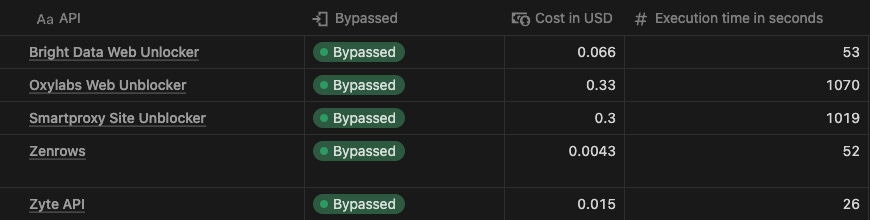
In total, we made 22 requests per run and all the APIs were able to bypass it.
Bright Data ✅
We are able to get the data we need in 53 seconds. The domain is not on Bright Data’s “premium list”, which means we could benefit from the lower tie of the cost, 0.003 USD per request.
Oxylabs ✅
We got the data in approx 18 minutes, so the scraper worked but was quite slow. The cost is also slightly higher because of the test methodology since we’re getting the data from HTML.
Smartproxy ✅
Same as Oxylabs, the scraper is successful but slow, while the costs are lower because of the difference of 1 USD between the two pricing plans.
Zenrows ✅
The scraper was successful with standard requests, resulting the most affordable of the five with also a good speed of 52 seconds.
Zyte ✅
Zyte API was also successful in this test, being the fastest one and also the second most affordable solution.
Final recap
All the scrapers were able to bypass Cloudflare, and it’s not a surprise: it’s the most widespread anti-bot and following the Pareto rule, it should be the first to be tackled when creating a scraping API.
Test 2: Datadome
Datadome is the hardest anti-bot in the cohort to bypass, and we chose Footlocker.it website to prove it.
Bright Data, Oxylabs, Smartproxy, Zyte ❌
I tried all the options available for these APIs but nothing worked, since I got all the requests returned 5XX errors.
Zenrows 👍🏻
Only Zenrows was able to bypass Datadome but with mixed results. It means you need to retry several times in order to get all the 20 URLs scraped. I’ve tried also using JS rendering and premium proxies but the results were even worse, so with basic requests and a good retry policy it could work.
Final recap
No solution got the green light, only Zenrows could at least get data from half of the URLs but in a production environment you will need to implement a structured retry policy.

Test 3: Kasada
Kasada is a niche anti-bot but recently I’ve seen it more often around even if it could be still considered inside the long tail of the anti-bot solutions, so I’m expecting that not every API would be able to solve it. For this test, I’ve chosen the Canada Goose website and the results were different from API to API.
Bright Data ✅
We slowly are able to get the data we needed, since it took 15 minutes. The domain is not on Bright Data’s “premium list”, which means we could benefit from the lower tie of the cost, 0.003 USD per request.
Oxylabs ✅
The spider was successful and also the fastest one, with only 81 seconds.
Smartproxy ✅
Even in this case, the scraping was efficient in terms of speed and success rate, and less in terms of costs because of the pricing model.
Zyte API and Zenrows ❌
These two APIs instead were not able to bypass Kasada.
Final recap
Bright Data was the most affordable solution for bypassing Kasada but was also the slowest one. In this case, Smartproxy and Oxylabs were more expensive but way faster.

Test 4: PerimeterX
PerimeterX is another anti-bot widely used on the net, probably the second one for adoption behind Cloudflare. So any API able to bypass it gains many points for the web scraping community. For this test, we used the Neiman Marcus website
Bright Data ✅
We are able to get the data we need in 1 minute. Even this domain is not on Bright Data’s “premium list”, which means we could benefit from the lower tie of the cost, 0.003 USD per request, so the overall cost for the 22 requests is 6 cents.
Oxylabs ✅
We got the data in approximately 70 seconds, so the scraper worked fast. The cost is also slightly higher, 21 cents, because of the test methodology, since we’re getting the data from HTML.
Smartproxy ✅
Same as Oxylabs, the scraper is successful but a bit slower, while the cost is around 20 cents.
Zenrows ✅
Scraper was successful with standard requests, resulting again the most affordable of the five but also the slowest one, with 7 minutes of runtime.
Zyte ✅
Zyte API was also successful in this test, being the fastest one and also the second most affordable solution.
Final recap
All the scrapers were able to bypass PerimeterX and this is good news for the web scraping community since it’s a widespread anti-bot and not always easy to bypass without a commercial solution.
Final remarks
I hope you liked this first edition of “The Great Web Unblocker Benchmark”, we’ll have a second one in June and I hope to bring on board more providers.
Speaking of which, on the 28th of March I’ll be hosted by NetNut on a webinar to present their new Website Unblocker.
Here’s the link for registering: click here to join us for free, we’ll talk about the evolution of web scraping and how web unblockers today are needed for an efficient tech stack.

In April we’ll have the same kind of benchmark but with anti-detect browsers, so stay tuned and if you want to suggest an anti-detect browser to test, please write to pier@thewebscraping.club
Thanks 🙏🙏 for the great insight
is there any service you tested in this articlt which can use my proxies to bypass cf? or all are use their own?