
Web Scraping news recap - March 2023
New tech and ethic consortium in the web scraping industry

This post is sponsored by Proxyempire, your trusted proxy partner. Sponsorships help keep The Web Scraping Club Free and it’s a way to give back to the readers some value.

In this case, for all The Web Scraping Club Readers, using the discount code TWSC10 you can save 10% OFF for every purchase.
Hi everyone and welcome back to The Web Scraping Club, this post is our monthly review of what happened in the web scraping industry in March.
The Ethical Web Data Collection Initiative
Source: Official website
This month opened up with all the major players in the web scraping industry teaming up to form the Ethical Web Data Collection Initiative.

Its founding members (Zyte, Smartproxy, Rayobyte, and Oxylabs to name a few of them), are setting standard best practices and ethical rules for the web data extraction industry in several areas:
Legality: Web Data Collectors will only scrape and use tools to scrape data within the confines of legislation and regulation from relevant jurisdictions, and will strive to keep up to date with judicial cases that may affect the legal boundaries of the work.
Ethics: Companies engaged in collecting web data will follow a strict ethical framework, including ethical principles related to four main pillars: websites, customers, proxies and data.
Ecosystem management: Web Data Collectors are in a symbiotic relationship with the free and open internet ecosystem and strive to engage it collaboratively in an open and communicative manner
Social responsibility: Web data should never be used to the detriment of society, and members pledge to support and collaborate with civil society and governmental organizations for societal benefit.
If you want to know more about these principles and what they practically mean, you can download their doc “Ethical Web Data Collection Initiative (EWDCI) Principles 1.0”
Tech updates
Apify new python SDK
Apify released its brand new Python SDK, allowing users to write scrapers and actors in Python.
This is great news for all the pythonistas like me and I will soon write a post about it. It’s an SDK compatible with all the major packages for web scraping like Requests or HTTPX, Beautiful Soup, Playwright, Selenium, or Scrapy.
If you’re new to Apify, it is a cloud platform that helps you build reliable web scrapers, fast, and automate anything you can do manually in a web browser.
Actors instead are serverless cloud programs running on the Apify platform that can easily crawl websites with millions of pages but also perform arbitrary computing jobs such as sending emails or data transformations
To complete the circle, Actors can be monetized on the Apify marketplace, where you can publish them and make people actually pay for their usage.

Bright Data Scraping Browser
Some weeks ago also Bright Data released a new product called Scraping Browser: basically it is a managed browser session designed to bypass anti-bot challenges.
As you can read from the documentation, you can use it in your Puppeteer or Playwright projects and call the Scraping Browser just like a normal proxy, after you logged in to Bright Data’s website and create the proper zone.
As we all know, setting up the infrastructure for some scraping with Playwright can be painful, since we need to try which browser works against that particular website we’re working on and also which configuration for the chosen browser.
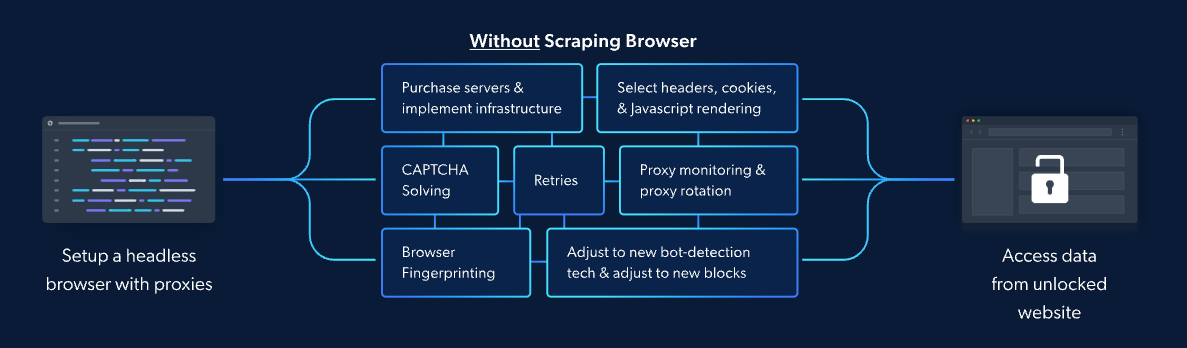
With Bright Data’s scraping browser, we should be able to do not worry about the infrastructure and its setup but we could only call an API to solve our issues.

Of course, it has a cost, as with everything in our life when we pay someone to fix some issue we don’t want to do by ourselves, and depending on your budget and time constraints it could be more convenient to make or buy.
Anyway, soon in this newsletter we’ll see how this tool will perform against the most famous anti-bot solutions, just like we did on the previous Hands-On article on the Web Unlocker.

Video of the month
As we have talked about monetizing your scrapers on the Apify Marketplace, here’s a great video that briefly covers all the aspects, from scraper creation to publishing, using no-code tools.

The most-read article of the month
The most successful article of the month is the first Hands-On article where I use Bright Data Web Unlocker to tackle the most famous anti-bot solutions.
This concluded my selection of posts and articles for March, if I’ve missed something important please let me know in the comments or in our Discord server.