
Web Scraping news recap - February 2023
Legal updates and new tools available in February for the web scraping industry

This post is sponsored by Smartproxy, the premium proxy and web scraping infrastructure focused on the best price, ease of use, and performance.

In this case, for all The Web Scraping Club Readers, using the discount code WEBSCRAPINGCLUB10 you can save 10% OFF for every purchase.
Hi everyone and welcome back to The Web Scraping Club, this post is our monthly review of what happened in the web scraping industry in February.
Legal updates
There’s no monthly recap without news about legal actions involving web scraping and privacy violated.

Meta vs Voyager Labs
The first news of the month is Meta suing the Israeli firm Voyager Labs for creating fake accounts on Facebook used to collect a large amount of personal data. This was then aggregated with other data points and sold to law “agencies tasked with public safety.” Meta states that this behavior breaks the Terms of Services of Facebook and, in my opinion, there’s almost no doubt about it.
The full article can be found here on Arstechnica.
Meta vs Bright Data
In the case involving always Meta and Bright Data, which started several months ago, there are some updates that arrived in the latest weeks.
Meta is suing Bright Data for its scraping activity on Facebook, while Bright Data insists they were scraping public data from Facebook, so they were not breaking any term of service.
During the discussion of the case in the past weeks, a curiosity came out from the papers: Meta has been a customer of Bright Data for 6 years, requesting data to improve its ad system.
Video of the month
Always about the legal aspect of web scraping, one of the most interesting videos I’ve found this month was made by William Whitman, an attorney who just opened his Youtube Channel and talks also about web scraping.
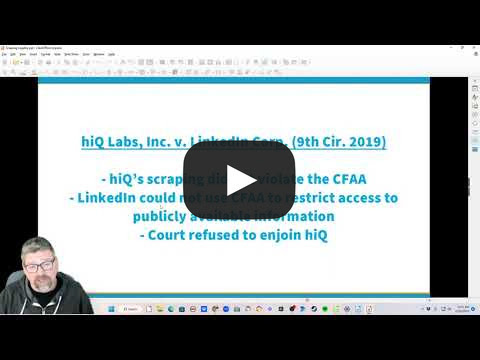
Tech updates
Oxylabs released its web unblocker
Oxylabs revealed its new web unblocker, an AI-powered tool to bypass anti-bot solutions. It selects, rotates, and evaluates the most suitable proxies for a specific site to provide the highest possible success rate along with the lowest response time. The system also selects the right combination of headers, cookies, browser attributes, JavaScript fingerprints, and proxies to appear as a real user, not triggering CAPTCHAs and bypassing target website blocks.
Here’s an image that recaps the functioning.

New Chrome headless released
Some days ago, Antoin Vastel of Datadome analyzed what will happen when the versions of Chrome will be rolled out and used more broadly.
Basically, Chrome used in Headless mode will have a fingerprint much more similar to the headful one and this will have impacts on anti-bot techniques.
As Vastel says: “The new headless Chrome browser fingerprint is way more realistic than the first/old version of headless Chrome. Depending on the sophistication of your detection engine, it’s going to make it easier for bot developers to bypass detection, particularly detection based on browser fingerprinting signals. As written in Chromium’s code, The new headless mode // is Chrome browser running without any visible UI. Thus, a lot of subtle differences that used to exist between the old headless Chrome and a genuine headful Chrome don’t exist anymore.”
This is an interesting topic to follow for anyone involved in web scraping, you can find the full article here.
The most read article of the month
The most successful article of the month is the Anti-detect Anti-bot matrix, a post where we compared several techniques against different anti-bot solutions to find out which configuration can be the best match for them.

This concluded my selection of posts and articles for February, if I’ve missed something important please let me know in the comments or in our Discord server.