
Web Scraping news recap - April 2023
AI everywhere, new milestone reached and web scraping Facebook

This post is sponsored by Bright Data, award-winning proxy networks, powerful web scrapers, and ready-to-use datasets for download. Sponsorships help keep The Web Scraping Free and it’s a way to give back to the readers some value.

In this case, for all The Web Scraping Club Readers, using this link you will have an automatic free top-up. It means you get a free credit of $50 upon depositing $50 in your Bright Data account.
Hi everyone and welcome back to The Web Scraping Club, this post is our monthly review of what happened in the web scraping industry in April.
New milestone
Before starting, I want to thank you all for subscribing to this newsletter. When I started writing 9 months ago, I could not imagine reaching over 1000 subscribers so quickly.
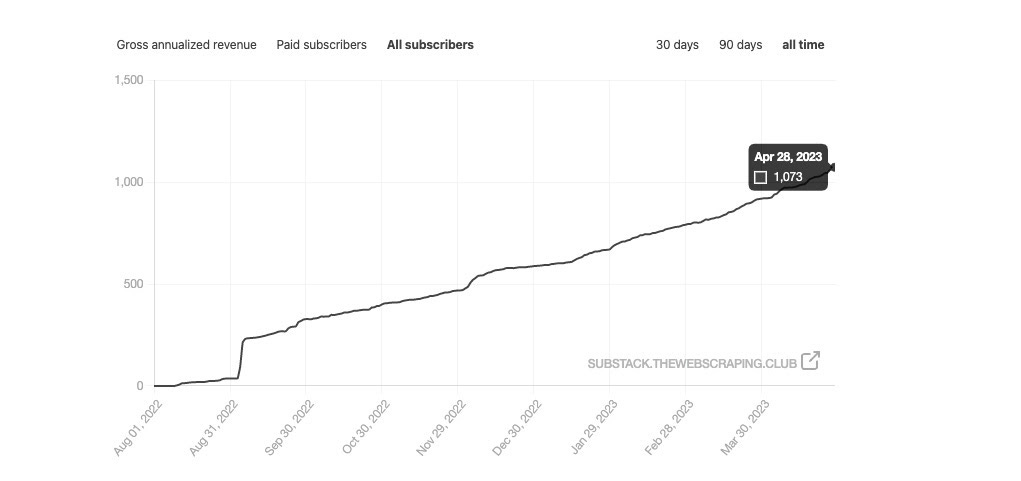
I’d like to celebrate with all of you this milestone but I have no idea on how we could do it.
Meanwhile, I hope to make something welcome for you, I’ve created a special offer with a 30% discount for the yearly plan and you can redeem it here.
Tech updates
The rise of AI

I’ve already written about GPT4 and its consequences for the web scraping industry, but of course, I was not the only one.
Several projects are starting in this landscape and maybe some of them will be soon tested on these pages.
Scrapeghost is a Python package where once defined a data schema and given a target URL, you should get the parsed data as a response.
Kadoa is conceptually similar to Scrapeghost, you can try it on its website and integrate it into your projects via API. Actually, it’s in pre-launch and you can join the waitlist for their free plan to give it a try.
It can be interesting to integrate into a large web scraping project this kind of solution, even if I’ve got several doubts about several points.
Is this approach cost-efficient? If we calculate only the costs of executions, the answer is not because, on top of actual costs, we need to add the cost of the AI service.
If we consider also the time spent by humans to fix spiders that broke because of website changes, the cost efficiency depends on how reliable is the AI solution. It all depends if the AI enables me to cut a significant amount of hours spent changing selectors, and from what I can see from the small tests I’ve run, the answer is actually no. But it’s all starting now, so I’m quite confident that in the near future, this will be the scenario.
Another critical point for these solutions is the bypass of anti-bot solutions. Actually, Kadoa clearly states on its website that cannot bypass any anti-bot, and for Scrapeghost I suppose it will be the same. This is because the anti-bot bypass it’s another task, for which GPT is unuseful. You need technicians and subject matter experts to do so and it’s a process that comes in another step of the web data acquisition pipeline. Before being able to read the HTML of the page and then pass it to GPT, you need to be able to access its code and these tools are not built for this purpose, while the new Zyte API or the Brigh Data Web Unlocker are made for it. A combination of the Zyte or Bright Data tools with GPT to make the final parse of the HTML could be a game changer in the web scraping industry.
Last but not least, when using AI to gather data you're basically asking a black box to give the results you want. But if the results are not correct, you cannot fix anything, since you cannot intervene in any way on these tools. So you have a binary option: if the results are ok, you can use the tools, otherwise, you cannot. There’s no middle way and for this reason, I’m still concerned about the efficiency of these solutions.
Are big tech companies using double standards with web scraping?
I’ve read an article on FastCompany where the author complains of supposed double standards used by big tech giants against the practice of web scraping. In substance, the journalist is saying that while big tech companies allow other companies, who are paying also for corporate API, to scrape their data, journalists and researchers are not allowed to scrape it for their use.
I’m not an expert in scraping social media but this article leaves me with mixed feelings since I don’t completely agree with this thesis.
As an example, I don’t see double standards. Companies that make sentiment analysis on Facebook and that are paying the access to the Enterprise API, probably don’t need web scraping, they have already everything they need.
And the fact that, in the same article, is noted that some companies that were sued by Facebook for doing some scraping instead of buying the access via API, confirms that accessing Facebook data via API is the only legal way to do it.
It’s expensive, but Cambridge Analytica should have thought us about the importance of the data contained in it.
On the other hand, the journalist complains that it’s difficult to make some research on political advertising on the platform without being able to scrape it. In this case, I totally agree with him. There should be a public API, available for free to everyone, where people could track who is paying which ad, to which cluster of people this ad is shown, and this type of info. It would help greatly the transparency not only of political campaigns but also it would be easier to detect scams and fake ads that are infesting Facebook.
Video of the month
With all the talks about AI and GPT this month, the video could not be about it. Here’s an interesting one by the channel Mikael Codes about Scrapeghost.

The most-read article of the month
And guess what’s the article read the most this month? And why you answer the ChatGPT one?
