
Web scraping from 0 to hero: a modern tech stack
How to compose a modern tech stack for your web scraping production projects

In the past chapters of the course, we’ve seen how to audit a web scraping project and a high-level introduction to tools and techniques to understand where to start. In this post, we’ll start understanding what it means to implement a web scraper, especially if we’re planning to have more of them running regularly.
While writing a scraper for a one-off run doesn’t require any tech infrastructure if not the spider itself and its running environment, when we’re thinking about a freelancing career or a company based on web scraping, we need to create a tech infrastructure that helps us in managing the daily operations and the expansion of our crawling base, while at the same time keep an eye on the costs.
Before going on, a reminder on the course structure.
How the course works
The course is and will be always free. As always, I’m here to share and not to make you buy something. If you want to say “thank you”, consider subscribing to this substack with a paid plan. It’s not mandatory but appreciated, and you’ll get access to the whole “The LAB” articles archive, with 30+ practical articles on more complex topics and its code repository.
We’ll see free-to-use packages and solutions and if there will be some commercial ones, it’s because they are solutions that I’ve already tested and solve issues I cannot do in other ways.
At first, I imagined this course being a monthly issue but as I was writing down the table of content, I realized it would take years to complete writing it. So probably it will have a bi-weekly frequency, filling the gaps in the publishing plan without taking too much space at the expense of more in-depth articles.
The collection of articles can be found using the tag WSF0TH and there will be a section on the main substack page.
Main challenges for web scraping professionals
The purpose of web scraping is to extract data from a website, so in web scraping projects, both when made inside companies or as a freelance for your customers, most of the time you need to deliver data. Sometimes it can happen you sell the code of the scraper, but this implies the end-user is another tech-savvy person who’s able to maintain it, otherwise, it has no sense as a task.
However, delivering data on a recurring basis is not enough. The correct sentence that summarizes the expectations is: you need to provide correct data in a timely schedule and with reasonable costs.
From this extended requirement, we can extract the three main challenges of a web scraping professional.
Ensuring data quality: from case to case this can be declined in different ways, but the easiest examples of data quality checks are related to e-commerce scraping. How am I sure, as a scraper, I’m extracting all the items from a certain website? Are all the expected output fields mapped correctly? Did I collect all the information I expected or there are multiple versions of the website that jeopardize the data collected?
Data freshness: different use cases need different data refresh calendars. Market intelligence applications could require a monthly update while dynamic pricing needs at least a daily schedule. The more frequent the update is, the more challenging the data collection becomes.
Costs: in the end, web data is a commodity. It doesn’t matter who scrapes it, but as long as the result is the same, it doesn’t matter who I’m buying it from. Distinguishing yourself from other data providers when the previous two points are satisfied at the same level can be done by pulling the most powerful lever in commerce: the price. So having an efficient web scraping pipeline gives you more opportunity to lower prices for your end customers and preserve your margins.
The bricks needed to build a modern web scraping infrastructure
We can see your web scraping data pipeline as an assembly line like the ones used by car manufacturers.
There’s this treadmill that moves data from the website to the final customer, and at each station, during this journey, a task is accomplished.

Creating the scraper
The first task, after the initial audit of the legitimacy of the project, is creating the web scraper. As seen in the previous post, this could be done using scraping frameworks or with browser automation tools. In the case of Python, you can use Scrapy for basic websites with no anti-bot solutions or Selenium/Playwright when an interaction with a browser is needed.
While writing a single scraper is not a painful task, when you need to optimize your time to delivery it could be a good idea to follow some best practices on code development. Do you need a scraper per every website or, in case you’re reading data from the JSON standard schemas delivered by Schema.org, like the product details, you can write only a generic one?
In case you need many different scrapers, having some common rules between them, like using always XPATH or CSS selectors, the same output data structure if possible, and the same logging stream, could be helpful for their maintenance.
Building the running environments
After creating the scrapers, we need to think about how and where they should run, keeping in mind that this will be the higher voice on your costs.
Ideally, your running infrastructure should breathe together with your resource needs: it must expand its capacity when more resources are needed and shrink where few spiders are still running.
For this reason, a cloud architecture based on virtual machines or containers is preferred to the old-fashioned bare metal approach, where you have a steady and fixed resource limit.
Keeping track of the running environment costs is crucial and we’ll soon write about it in a dedicated post, but consider that nowadays every major cloud provider has APIs for knowing in real time the usage and costs of their infrastructure.
Another required feature is the capability of choosing the best configuration to use for the type of scraper we’re launching: while traditional scrapers don’t need too many resources, browser automation tools are more demanding in terms of RAM and CPU. Optimizing the size of the environment without disrupting the service is key to containing costs.
Stacking additional tools: proxies, API, CAPTCHA solvers
There are some cases where our scrapers are not enough to get the data we need. Maybe some rate limiting on the requests by the same IP is blocking us, or some anti-bot or CAPTCHA solution is installed on the target website, so we could need some extra help.
Proxies are the most common way to bypass the rate limit: in fact, changing the IP at every request (rotating proxy) solves this issue, but it’s not the only use case for using them. Some websites could block IPs coming from data centers, so residential or mobile proxies are needed.
In the past years more and more scraping APIs have become available on the market, in order to bypass anti-bot solutions without the need for browser automation but simply integrating them in our scrapers like a traditional proxy.
Of course, they come with a cost since they handle under the hood all the browser automation, IP rotation, fingerprinting camouflage, and so on. But it’s also true that by doing some math, we could discover that our own browser automation solution, considering the more demanding infrastructure and the longer execution times is not so convenient. This depends from case to case and from vendor to vendor: some APIs are priced per GB and others by the number of requests, and for the same website we could have very different prices.
Another useful class of tools is CAPTCHA solvers, which can be used when a website has some CAPTCHAs in place, as an example when filling out some forms or as an anti-bot browsing protection.
Storing and checking the output data
Unless specific cases, it’s not a good idea to send the web scraped data directly to the final user.
When doing web scraping we don’t have any control over the data source, so we could incur data quality issues at any moment: a website changes, is no longer accessible, or raises its protection with anti-bot.
This means that, depending on the business we’re into, we could decide to store the whole HTML code of the websites we’re scraping or directly the final results of the parsing.
If we opt for storing the HTML, maybe only for a rolling window of certain days, we have the option to go back in time when we notice any issue in the data and fix the parsing part of the scraper, but of course, this comes with a great cost in storage.
On the other hand, for a leaner data pipeline, we can parse the HTML directly during the scraper and store only the output. This could drastically lower the prices for storage but we must be quick in detecting anomalies in data since in this way we cannot go back in time to recover past data.
In both cases, we need a data quality process that automatically checks our data, when possible, and raises red flags when issues are detected. In most cases, automatic checks are not enough and a sample human data quality process needs to be put in place.
Only after data has passed quality checks, it could be delivered to the final user.
The feature needed in a modern web data pipeline
We’ve seen the shopping list of the pieces needed for a web data pipeline, but how to glue them together and do it efficiently is something extremely important.
Especially if we have in mind to scrape many websites, from day one we must think about how to make the growth less painful as we can. Imagine handling hundreds of scrapers, each with different commands to be executed to start and all scheduled with crontab: only changing the scraping frequency could be daunting.
The same could be said about the scrapers’ execution monitoring: how do we know if the executions ended abruptly or not, if there was an infrastructure issue, or if the website stopped responding?
And again, if a website needs proxies or scraping APIs, do we know how many requests and how many GB per run we’re using, to have an estimate of the costs in both cases?
All these questions could be answered only if we standardize the processes and centralize the logging of all the scrapers.
In my experience, what really helps in achieving good control over the whole data pipeline, are the following features.
Centralized and elastic scheduling of scrapers: instead of using crontab, use a centralized table or file to change the schedule frequency of all the scrapers, giving a clearer view of what’s currently happening
Standard processes: scrapers should be launched in the same way, independently of the technology used and their content, so that there are one or few processes that launch them.
Thanks to the previous two points, we can centralize also the logging of the processes and of the scrapers. In this way, we know exactly what’s happening in the background.
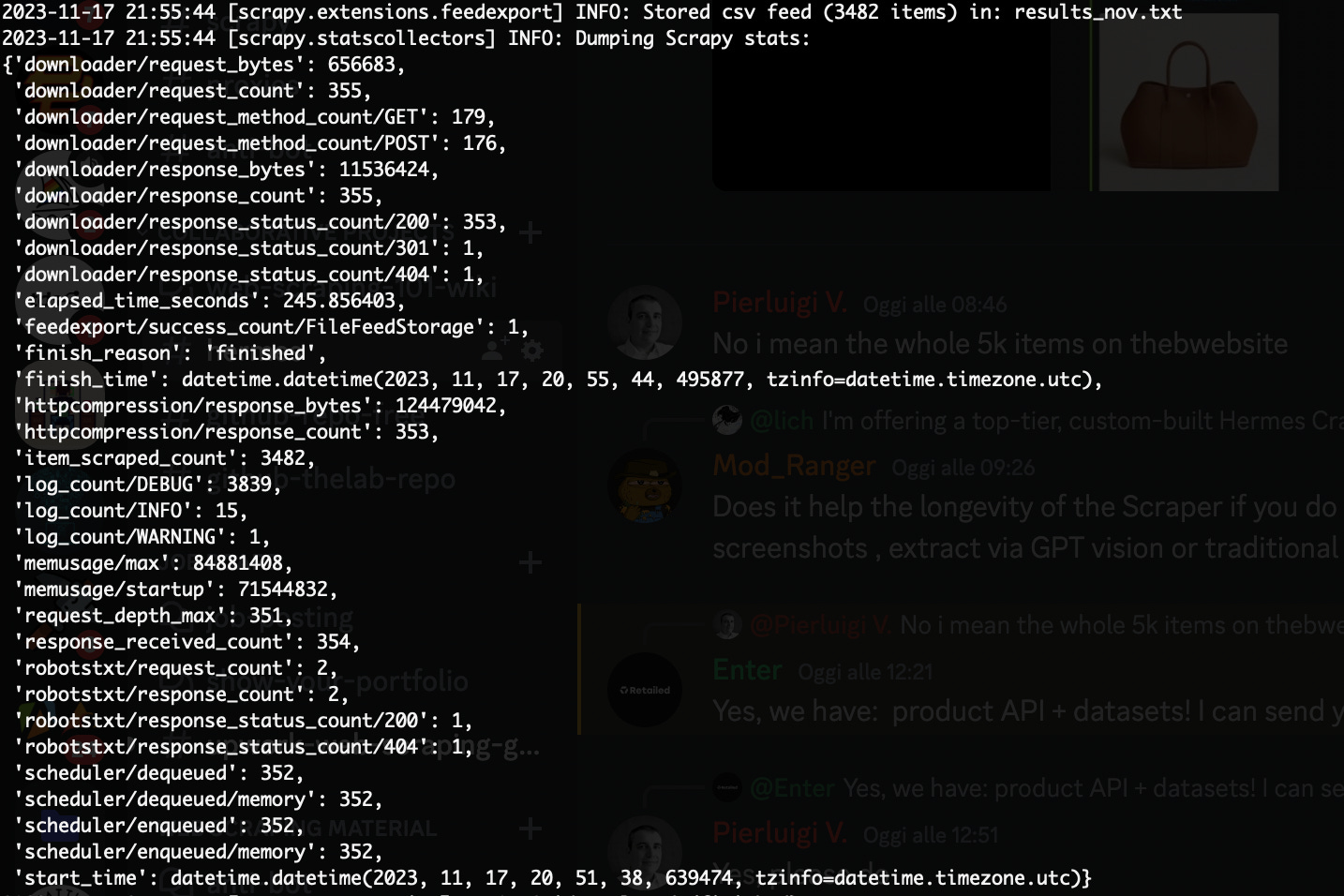
Logging also all the stats coming from our scrapers: for example, Scrapy exposes some interesting stats at the end of the execution of a scraper, such as the number of return codes encountered, the bandwidth used, execution time, the number of requests made and so on. This will help us greatly in understanding what will be the cost of adding a proxy on a website or potential issues that happened during the execution.

Having all the information needed centralized in one place makes it easier to detect issues in our executions and raise red flags in case of some troubles in data gathering.
Hope this overview has helped you in gathering some ideas for your web scraping data pipelines, but each of the stages requires a deep dive and it will come in the next episodes of this course. For any feedback or suggestions about the course, feel free to write me at pier@thewebscraping.club
You mentioned logging as essential tool to support scraping efforts, but it wasn't introduced so far for the whole git repository. Any chances you will incorporate logging in the future?