
Testing the new undetected-chromedriver 3.5
Is the new version of undetected-chromedriver capable to bypass Cloudflare and other antibots?

July is the Smartproxy month on The Web Scraping Club. For the whole month, following this link, you can use the discount code SPECIALCLUB and get a massive 50% off on any proxy and scraper subscription.

On these pages, we often try new techniques and tools to bypass anti-bot software that prevents scraping. Of course, no need to say we’re talking about the legitimate use of web scraping techniques on publicly available information.
Sometimes it happens that solutions provided here don’t work in different context and times, which lead to a reflection I want to share with you.
The Web Scraping Triad

When building a web data pipeline, especially if we need a recurring stream of data and not only a one-off extraction, just thinking about the tool for scraping is not enough.
Of course, the first aspect we need to understand is which instrument is right to scrape the target website.
If there’s a modern anti-bot, probably we’ll need a browser automation tool like Playwright or Puppeteer, while on simpler websites a Scrapy project could be enough.
But once we found a solution that works on our laptop, the job is not over. We must be sure that the solution works also on the target scraping environment, typically a server on a datacenter. This is not to take for granted, since anti-bots, via the browser’s API, are able to detect the hardware where the scraper runs and block it if they find it’s running from a datacenter.
In some cases you need to iterate to choosing the right scraping tool once you’re testing your solution on the target hardware, but some other times adding the right type of proxy could be enough. It could happen that running your scrapers from a datacenter but adding residential or mobile proxies could be enough to not trigger any red flags from the anti-bots, but it really depends from website to website, since anti-bots can be configured to be more or less sensitive.
Undetected-Chromedriver 3.5 stress test
The idea for this introduction came to my mind some days ago, while reading the readme file on the GitHub repository of undetected-chromedriver. The main contributor was complaining about the fact that many issues were opened by people who kept in mind only the first element of the triad (tool) but didn’t care about the hardware or the need for proxies.
For this reason, I wanted to create a complete test against the usual five anti-bots we use as a benchmark (Cloudflare, Datadome, Kasada, PerimeterX, F5), in different setups.
The first run will be a test from a local environment, the second one on a datacenter without any proxy, and the third one will be from a datacenter using Smartproxy Residential proxies.
The scraper will load the main page of the websites (e-commerces) and browse around for some pages, to see if it gets detected after some time.
Cloudflare
We make the scraper load the harrods.com main page, then the women’s shoe page, and then scroll until the last page (page 61 today).
Datadome
We make the scraper load the footlocker.it home page, then go to the newborn category and again scrape until the last page (11 today)
Kasada
We make the scraper load the canadagoose.com home page, select an item category and then make the page scroll down to the end until all the items are loaded.
PerimeterX
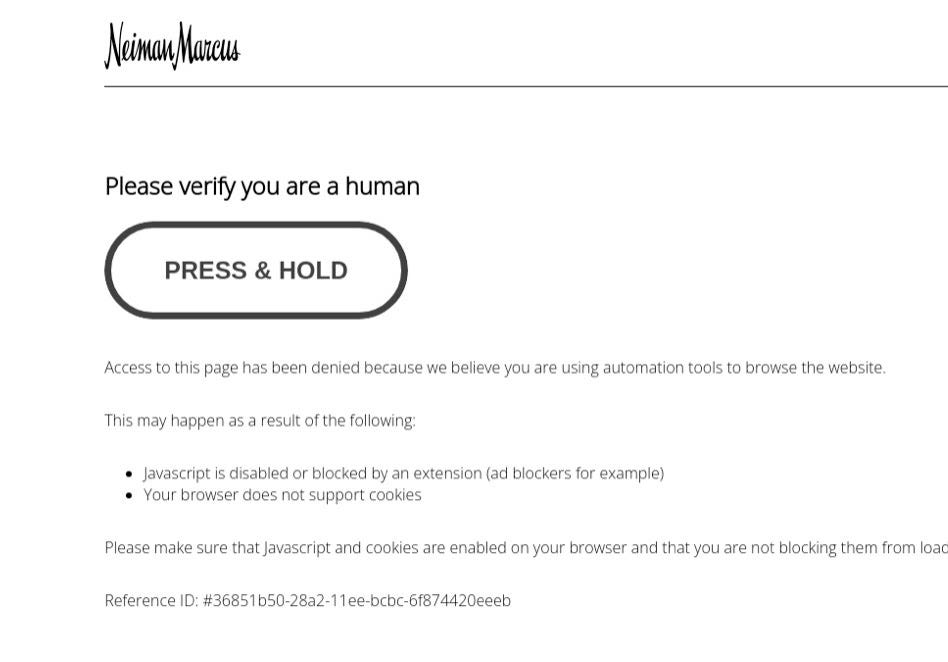
We make the scraper load the neimanmarcus.com home page, select the women's jeans category and then load all the pages.
F5
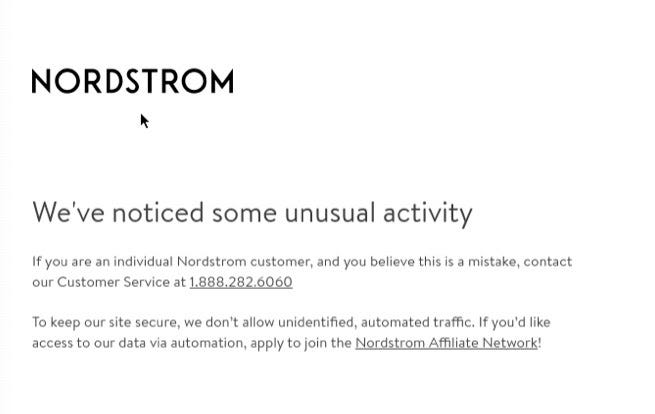
We make the scraper load the nordstrom.com home page, select the women's espadrillas category and then load all the pages.
First run - on a local environment
I’ve put together all these tests in a Python script called tests_local.py, which can be found in our GitHub repository and available to everyone.
Cloudflare bypassed with a plain vanilla script
Datadome was the hardest one to bypass, and I’ve been able to do it only partially. I used Brave software hoping it would leak less sensible information and using it I could load the home page, a thing I could not do with Chrome. But I could not go further in loading another page, probably the anti-bot wants a more “human-like” behavior but it’s not the scope of this post to find a way to bypass it. This is the behavior of websites heavily stressed by bots, typically selling sneakers (thanks sneakersbot community).
Kasada again bypassed without any issue with a simple script, where the only fancy thing needed was to scroll down to the end of the page for loading all the items.
Perimeterx and Neiman Marcus websites are tricky. Using Chrome the spider get stuck loading some script, so I used Brave. Probably it’s an issue of the website and not related to the anti-bot. After some try, my IP got blocked for several minutes and this is a sign that in a production environment, we would probably need some proxies
F5 is again a piece of cake to bypass with a plain script.
Second run - on a datacenter, without proxies
Let’s repeat the tests made before but from a VM inside a server on AWS, tests in the file tests_remote.py.
Cloudflare blocked on the home page with their verification challenge

Datadome blocked us with a captcha when loading the home page
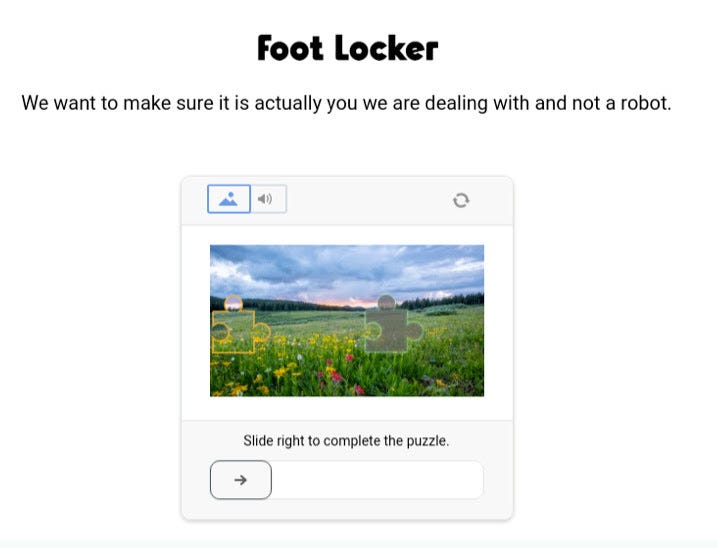
Kasada stopped working, showing a blank page both with Chrome and Brave when loading the home page.
Perimeterx worked when we loaded the first page but then got banned when trying to load the product category.
F5 stopped working, we got banned when loading the first page.
The reason for all these failures is simple: AWS publishes the ranges of the IPs of their datacenter so for anti-bots it’s very easy to understand if the traffic is coming from the AWS Cloud. Assuming that this traffic is coming from bots, they raise some red flags then they see an IP belonging to those ranges.
Third run - on a datacenter, with residential proxies
Adding an authenticated proxy on undetected-chromedriver is quite a pain in the back, so I cheated a bit. I’ve whitelisted my IP in the Smartproxy console so I could use only the endpoint as a proxy, without the need to pass username and password.
The modified script is called tests_remote_withproxy.py and runs as before from a VM machine in a AWS datacenter.
With this configuration, we have mixed results, depending on how much the anti-bot relies on device fingerprinting rather than IP-related data.
In fact, Cloudflare, Datadome and Kasada blocked us even with residential proxies while PerimeterX and F5 are bypassed.
Final remarks
Here’s a recap of the results of these tests.

Undoubtedly undetected Chromedriver is a great tool, and we can see it when running locally. Every anti-bot test is bypassed and, being a free and open-source tool, this helps greatly freelancers and occasional scraping.
But when we need to scrape on a production environment, we need to deploy our scrapers in datacenters mainly, and more and more advanced fingerprinting techniques are tackling hard these configurations. Even if we use residential proxies, which help us bypass PerimeterX and F5, the hardware fingerprinting is still too strong to be handled by Undetected Chromedriver.
In these cases, tools made to measure like Smartproxy Site Unblocker (here’s the full review), are probably the best tools to scrape without worries also the hardest sites.
Alternatively, we can check from website to website what’s the best tool, as an example in our The Lab series we have seen how Cloudflare could be bypassed with Playwright.
It’s challenging but less than changing the traditional data pipeline by deploying the scrapers not in a datacenter but in workstations hosted somewhere.