
The true costs of a web scraping project
Considering all the hidden costs behind, not as easy as it seems.

In this great (both qualitative and quantitative meaning) community, there are different professional figures involved in web scraping, that we can group into:
Executives or PMs working in companies directly involved in web scraping operations.
Scrapers’ developers working as an employee
Freelancers who make a living writing scrapers
Despite being in different positions, there’s one “fil rouge” for everyone: they all need to understand what’s the cost of a web scraping project. If you’re an executive or a PM, you have to be sure you’re charging your customers enough or that your operations stay within a given budget.
Instead, I’m sure that if you’re a developer inside a company, every time there’s a new web scraping project, the first question from your manager is "How much it will cost us?”, for the same reason as before.
As a freelance, there’s no need to say how important is to evaluate your expenses in your gigs, since you’re making a living out of them.
My friend Andrea Squatrito, in our Data Boutique substack wrote a great post about The Economics of selling web data, and today we’re digging deeper into the total costs of these operations.

In fact, knowing the real costs of your scraping operations is key to understanding the unit economics of your scraping activity and creating a profitable business. Keeping the costs as low as possible without affecting the quality of the output gives your business an advantage over your competitors.
If you’re interested in how to increase the efficiency of your data collection, I’ve been invited by Smartproxy to talk about this topic on the 6th of December at a free webinar.

Together with the Smartproxy team and Fabien Vauchelles we’ll share our ideas, tools, and experiences on how to keep your data pipeline lean and efficient. I’d be happy to see all of you there, here’s the registration link to the webinar.
The cost elements of web scraping
When we receive a “call for data”, being it made from a customer or our manager, we have several variables to consider:
The difficulty of creating the scraper, if the website is protected by antibot or not.
The data refresh frequency, whether it’s a daily, weekly, or monthly refresh
The length of the need for data, if it’s a one-off project or it will last for months/years.
These variables significantly influence the profile cost of our project and, subsequently, how much we should eventually charge for it and what’s the most convenient approach to follow.
In order to understand better all the costs we’ll incur, we can split them into two macro-categories: the costs of getting the data once and the costs of maintaining the data feed during a certain time window.
Cost of getting the data
Creating a scraper
When it comes to business, time IS money. So when we consider the costs of getting data, we should consider the time spent coding the scraper until we get the first correct outcome.
Let’s put down some numbers, just to create some plausible scenarios. Let’s assume your hourly rate is 20$, depending on the difficulty of the scraper we have different profile costs.
To simplify, we can say that the more difficult is the website to scrape, the more hours we’ll need to build the scraper, so here’s a starting point of the costs for creating our scraper in-house.

These costs indicate only the development phase and not how much it costs to run the scraper, which we’ll see later.
Buying a commercial solution
But what if we buy the solution instead of creating it? There are many services today, from various web unblockers on the market to the APIs studied for specific target websites, that in some cases could be interesting to use. In this case, the main factors of their costs are basically their pricing model and the size of the target website, on top of the difficulty of the website itself. On top of that, most of the providers need a monthly commitment and not a pay-to-go service, so making hypotheses on how much this way will cost really depends from case to case.
In fact, different commercial solutions have mainly two billing metrics: cost per GB of bandwidth used of cost per request made. This makes it extremely difficult to compare costs from different providers with different pricing models but it’s also an opportunity. If a website has an internal API that meets our requirements, a cost per GB could be a cheap solution, since we’re not downloading the full HTML of the website but only the responses in JSON format. On the other hand, if we don’t need to scrape many pages because data is aggregated in them, for example in pages full of listings, a price per request could be a good choice.
In this scenario, we can assume a small setup cost for developing the skeleton of the scraper, while most of the costs, of both the development of the anti-bot bypass and, depending on the tool, the parsing phase, are outsourced to the target solution. But these costs will be recurring, since every time we need a data refresh we’ll incur them, while if we create the scraper, recurring costs could be cheaper.
Let’s create three cost scenarios for the inception of these solutions, so we can get a comparison between the different paths. I’ve imagined three different cost profiles, one for a small, medium, and large website.

Buying data directly
A third option could be to buy the data you need instead of embarking on your scraping journey, at least as a starting point for your projects.
In fact, there are some data marketplaces like Datarade, AWS Data Exchange, and Databoutique.com (this one specialized in web-scraped data) where you can buy pre-web-scraped data that matches already your needs or that can be used as an integration in your projects. Maybe you need to scrape all the product images from a website, you can start buying the whole product catalog from there and then, for every product, scrape all the images.
Depending on the cost of the dataset and the integration on top you need to build, this could be a good fit in some cases, which doesn’t exclude the prior two. In fact, for building your scraping integration, you could still need tools and scraping hours.
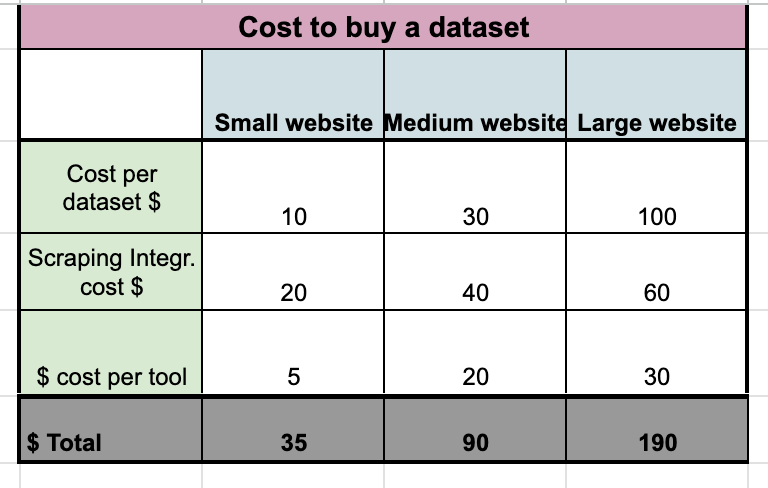
For this scenario, let’s create three options where, on top of datasets of different prices, we imagine also some integration with scraping and external tools.
Of course, in this case, there are so many variables that it’s impossible to create an accurate simulation since we can vary from a situation where the dataset is OK as is purchased from the opposite where it still needs several additional steps.
So I supposed three average cases where we still need to make some work on top of the dataset, which cost varies from the size of the website.
Cost of maintaining the data feed
Once we’ve set up our starting point, we need to keep the data feed alive for the final user. In case it was a one-off request, there’s no additional cost but in case we need to refresh data regularly, we need to add also this voice to the total expenses of our web scraping project.
Maintaining a scraper
In case we create our own scraper, we need to evaluate two expenses we’ll incur for the length of the project.
We have the mere running costs, which are made up of the cost of the hardware environment where the scraper runs (virtual machine, docker, servers), and of any other service on top of it, like proxies or CAPTCHA solvers.
Additionally, the spider could break every X time, so we need to put some effort into fixing it. In our scenarios, we’ll put two hours per month to fix the scraper and a variable environment cost depending on the size and the difficulty of the website. I’ve also set a weekly refresh of the data, so the monthly cost is summarized in this table.

Buying a commercial solution
Instead, in the case we’re buying a commercial solution, we’ll face almost no cost of maintenance for the scraper but we’ll have the live costs of the solution and a smaller portion of the running environment costs. In fact, even if we’re still in need of running the execution of the scraper, we’re not gonna need the resources to support headful browsers, which are quite resource-hungry, since these are managed by the service bought.

Buying data directly
If we have considered this option for our data pipeline, we’ll have all the recurring costs seen before, so depending on the cost of the dataset and of the eventual integrations needed, we’ll pay a fixed price every month.

So what’s the best approach?
TL;DR It depends from case to case.
Generally speaking, when we have a one-off requirement, the effort to create a scraper from scratch it’s too big, so it’s probably wiser from an economic perspective to look for already scraped data or tools that allow us to get the data quickly and cheaper.
The benefits of having an in-house scraping solution are starting to be seen in the long run, where the initial set-up cost is amortized, and running costs and maintenance are lower than buying an external solution or dataset.
On the other side, buying a dataset is convenient when the price per dataset is under a certain threshold and doesn’t require too much effort to integrate with additional scraping.
If you want to play with the numbers, I’ve created a spreadsheet at this link so you can use it as a tester for your scraping costs
Hey please provide an example of the end result.
which dataset are you aimming to get from which websites?
i.e lowering the hours you work per websites...
thanks.
please respond
ori.keshet@solaredge.com
This is a great post PL, It's interesting to see many of your numbers match what I've found. These are some of the core economic considerations we ponder when trying to build the next-gen of tools to try and disrupt or break the economic constraints of scraping projects.
You probably saw at Extract conference a couple of the ways Zyte is trying to break the economics of building new scrapers with our AI-powered spiders, and optimising the economics of anti-ban setup and maintenance with Zyte API.
What would you say is the biggest cost to scrapers, while being the least value-adding to the end product of the data?