
The state of public web data in 2024
My two cents on the latest report by Bright Data

Some weeks ago a rich report called The State of Public Web Data was published by Bright Data and I just wanted to take some time to read its 90+ pages and digest them.
While its final considerations might seem obvious, reading the full report gives enough insights that could be interesting for many actors in the web scraping landscape.
But let’s first start by understanding how the report has been built.
Methodology
Directly from slide 3, we find out the methodology used to extract the data for the following pages:
Bright Data commissioned independent market research specialist Vanson Bourne to undertake the survey of 500 decision-makers between December 2023 and January 2024, with representation in the USA (300) and the UK (200). Respondents hold leadership roles and are from organizations with 250 or more employees. They represent organizations from diverse industries, including retail & eCommerce, banking & finance, insurance, manufacturing, media, telecommunications, business & professional services, and IT & tech. These organizations report annual revenues ranging from at least $10 million to over $50 billion.
The company Vanson Bourne interviewed decision-makers from 500 medium and large companies, with more than 250 employees, in the USA and UK.
These premises are key to understanding the results of the survey: the people interviewed work for important companies in two of the most innovative and fast-paced markets in the world, where companies accept to take more risks trying out new solutions for their businesses.
I’m stressing this because, as a European citizen, some numbers that we’ll see in the next chapter seem unrelated to my personal experience with local companies (but make total sense when compared with US companies)
Web data is no longer a taboo

Most of the interviewees recognize the importance of web data for the global economy and have a plan to collect and action data.
Several years ago, collecting web data was seen as something shady and reserved to hackers and I’m happy to see that now it’s seen as important, if not crucial by most of the companies, at least in these markets.
In Europe, we’re traditionally lagging by several years, but things are slowly improving from when we started collecting data.
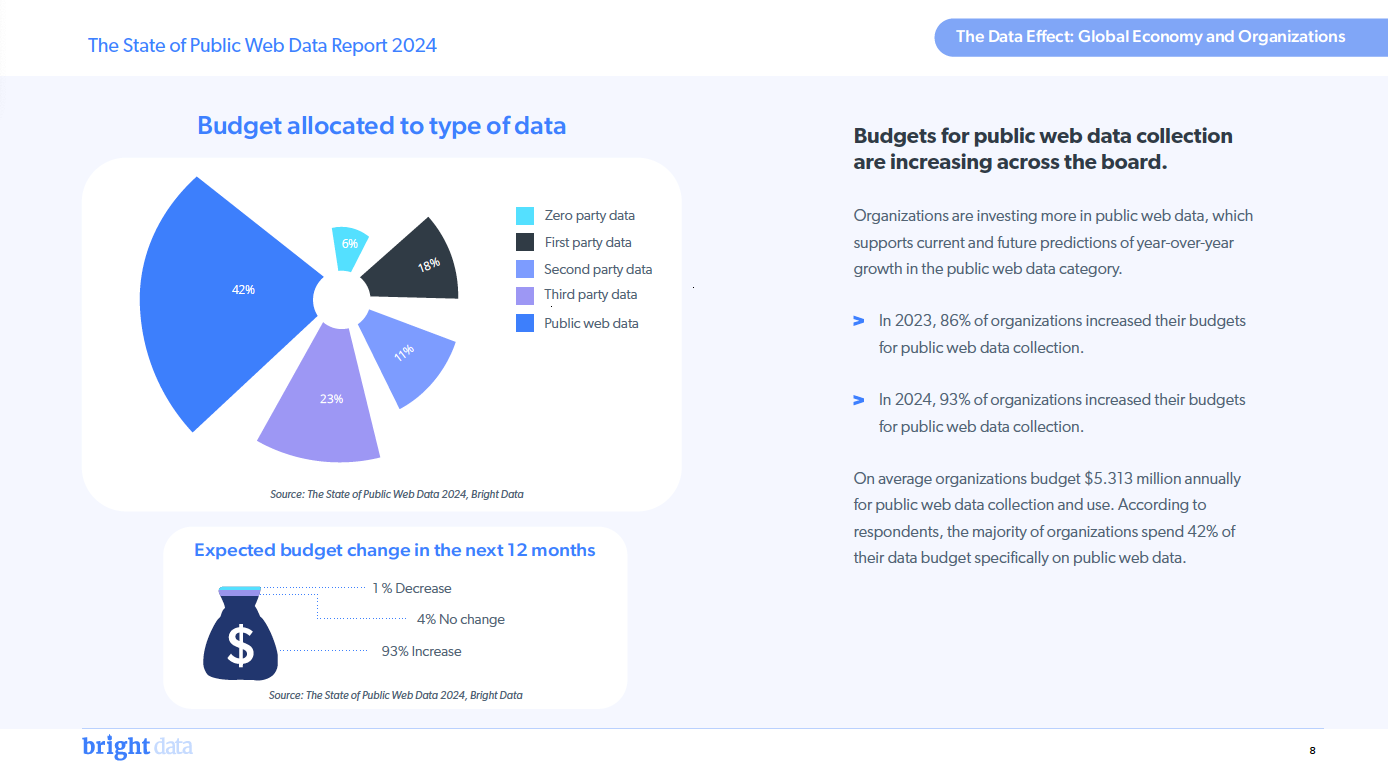
This slide is even more important: the vast majority of the interviewees say that in 2024 the budget for collecting and using web data is increased, compared to 2023, with an average of approximately 5M yearly expense per company.
I didn’t find any info about what’s included in this number: is the cost of the Data Engineering team included or it’s only the bill for the tech and data stack? This could change what feels like a great number just an average one. If we think that the average salary in the US for a data engineer is 128k USD, if their cost is included in this 5M, the space for the bills is reduced significantly.
Web Data is cross-purpose and cross-department

Web data usage, in general, brings different benefits to organizations, and this is a fact.
While internal data shows how your ship is sailing and where it’s headed, web data tells you what the sea looks like: where are the other ships? Is there any storm approaching? Is there any pirate fleet around?
Let’s say we’re the CEO of a shoe company called Y (X is already taken).
A number is just a number without a benchmark: the Y stores have sold 5% more sneakers than the previous year, but do we have an estimate on how many sneakers our competitor sold in the same period? Did the company perform like the others or 5% is far below the industry average? You can answer it by monitoring inventory on relevant e-commerce websites.
Or again: our e-commerce works well on newly launched products but then the sales stop after a few weeks or months. How can we understand the reason if we don’t monitor third-party e-commerce selling our products? We may discover that as soon your products are available on other websites, our prices are higher than the competitors.
Are we spending our advertising budget wisely? We’re promoting a certain product, just to find out that other websites sell it 10% cheaper than our website or stores. Basically, we’re paying advertising to our competition.
Last but not least, how the market is responding to our newly launched product? are customers satisfied or not?
In our example, we’ve seen examples of web data collection involving four different departments of your hypothetical company: business strategy, e-commerce department, marketing, and customer service.
And the most important thing is that without web data, the Y company would be almost blind in all these business aspects.
I’m glad to see that companies are well aware of it, but, as data providers, there’s probably still more work to do to bring this level of awareness to other markets.
Web Data and AI

In 2024, there’s no report without the world AI inside of it, and this is no exception.
But it’s not just hype: generative AI models heavily rely on web data, this is clear to (almost) everyone.
Despite some recent articles saying that AI is running out of data from the web, a thing that seems unrealistic to me, companies that want to enrich models or train new ones, for sure they need web data to do so.
And that’s great news for the whole web scraping industry, which also leads to the last point of this article.
More data and more often

Once companies understand the benefits of having web data, they want more, for more purposes and more frequently.
Of course, this depends on the business cases: a dynamic pricing algorithm based on web data or a revenue optimizer for travel fares will require an almost real-time data feed. At the same time, a real estate market monitor could be refreshed weekly if not monthly.
But again, this is great news for the web scraping industry, hoping this attitude from the companies will expand to other markets, opening opportunities for companies with a more strong sales power in Europe, where we still haven’t completely seen this opening.
What’s missing in this report?
The report continues with insights on single industries and I invite you to read it till the end, since it’s a great one.
There’s only one thing I feel it’s missing, probably because it’s too hard to estimate (and you cannot do it by interviewing “only” 500 companies): how big is the market for web data?
How much companies are spending for extracting data (proxies, unblockers, managed scraping services), both with third-party companies like Bright Data and internally?
In 2023, Zyte showed a slide with some estimates during their Extract Summit, which is the only number I’ve seen about the total market of web scraping.

I’d be curious to understand if the cost for web data, given also the AI boom, for 2023 was still 6BN USD, which seems an amount that could be spent by OpenAI itself, not to mention all the Google and Chinese companies in the field.
I think it’s too hard to get an answer, even because there are also plenty of unserved companies that are willing to adopt web data but, given their dimension, they could not put a team in place but also could not afford to spend 100k a year for some data feeds.
That’s why we started building Databoutique.com, a marketplace for web data, since we want to lower the costs and frictions for the adoption of web data, in a historical moment where there’s more need than ever for high-quality public web data.
If you’re interested in knowing more about it, from a seller, buyer, or investor perspective, feel free to reach out at pier@thewebscraping.club
Great insights!