
The starter toolkit for a python web scraping developer (2022)
Tools you can't miss for your web scraping project

Let's find together what tools can't be missed for a Python web scraper developer, for any suggestions feel free to write in the comment section below. If you wish to receive articles like this directly in your email, you can subscribe below.
Scrapy
Web Scraping + Python = Scrapy, by definition. Born in 2009, It's the most complete framework for web scraping, that gives the developer plenty of options to control every step of the data acquisition process.
Open source, maintained by Zyte (formerly known as Scrapinghub), has the great advantage that there's plenty of documentation, tutorials, and courses on the web to start with. Being written in Python allows you to start instantly to create your first spider within minutes.
Another great advantage is its modular architecture, described in the picture below and well explained in the official documentation.
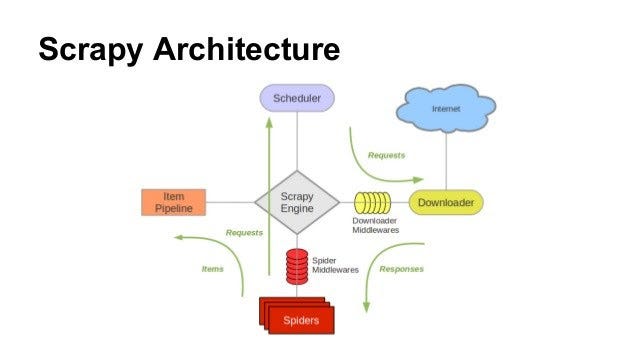
Briefly summarizing the workflow, The Engine gets the initial Requests from the Spider, passes them to the scheduler, and then asks for the next requests to crawl.
The Scheduler returns the requests to make to the Engine that sends them to the Downloader, via its Middlewares. The Downloader returns a Response that goes to the Engine via its Middlewares.
Again the Engine sends the Response to the Spider via its Middlewares and the Spider returns Items and next Requests.
Finally, the Engine then sends Items to Items Pipelines and then asks for more Requests to crawl.
Most of the magic of Scrapy happens in the two middlewares: in the Downloader Middlewares, you can add some manipulations to Requests and Responses. As an example, you can filter the Requests before they are sent to the website, maybe because they are duplicated. Or maybe you want to manipulate the Responses before they are used by the spider.
In the Spider Middlewares, you can post-produce the Spider output ( Items or Requests) and handle Exceptions.
Items are the standard output of Scrapy spiders and in the Item Pipelines, there are options and functions to manage the output of the scrapers, like file formats, field separators, and so on. This makes Scrapy extremely useful for structured data with several columns per row.
Advanced Scrapy Proxies
A little self-promotion here, This is a Python package for Scrapy written by me that handles lists of proxies in several formats and uses it in your Scrapy project. You can use a list accessible on a public URL, a list on the local machine, or a proxy directly in the options. Far from perfect but we use it daily in production.
Scrapy Splash
Scrapy is great but has some limitations, the biggest one is that it reads only static HTML.
To overcome this limit, the scrapy-splash plugin adds the ability to make Splash API calls inside your Scrapy project.
Splash is a lightweight browser with an HTTP API, implemented in Python 3 using Twisted and QT5.
This downloader middleware modifies the Requests, routing them to a Splash server specified in the Scrapy options, so the response contains the result of the Javascript executions.
Microsoft Playwright
In case there's the need for a real browser to scrape some websites, Microsoft Playwright is the newest solution we can rely on.
It is not the only automated test solution that allows us to script a browser execution and scrape its content, there's Selenium too as an example, but it's the easiest to use and at the moment the one that guarantees more successful responses in case of strong anti-bot software.
Its installation package already includes the most popular browsers and when included also the playwright-stealth package in the execution, the browser is almost indistinguishable from a real human installation.
Wappalyzer Python
I recently discovered this Python wrapper for Wappalyzer.
Wappalyzer is a tool that discovers the technology stack behind a website, like the anti-bot software and common e-commerce platform.
This wrapper in Python allows you to programmatically study your target website from the command line.
At the moment this seems to be the best tool set for Python web scrapers, but if something is missing or you’re using something else and want to reach out, feel free to add a comment in the section below.
Upcoming events
September is a month full of web scraping-related events.
7-8 September, Oxycon 2022, free to attend online event powered by Oxylabs. Link here
29th of September, Web Data Extract Summit, a full day packed with talks.
For our readers, we have a special discount code 50% off: use the code thewebscrapingclub when buying your tickets.