
THE LAB #29: Bypass Cloudflare Bot Protection with Scrapy
Is it possible to bypass Cloudflare without using an headful browser?

In the past episodes of The Lab, we’ve already seen different solutions to bypass Cloudflare several times, from using Playwright adequately tuned or paired with anti-detect browsers like GoLogin, to using commercial products like the different web unblockers available on the market.
In my experience, as new web unblockers arrived on the market, I’ve shifted from using a headful browser with Playwright to these super APIs. In fact, a headful instance of a browser requires more resources and time than a Scrapy program with an unblocker attached. Making some math, despite Playwright being free to use, the cost of scraping was not that different than using the new and cheaper unblockers, which were even more reliable.
But since this is a cat-and-mouse game, this setup lasted only a few weeks. Suddenly all the websites protected by Cloudflare and Datatome were no longer scrapable by the unblockers and this obliged me to find a solution.
Why do you need to bypass Cloudflare Bot Protection?
According to Statista, Cloudflare has more than 86% of the market share for anti-bot software.
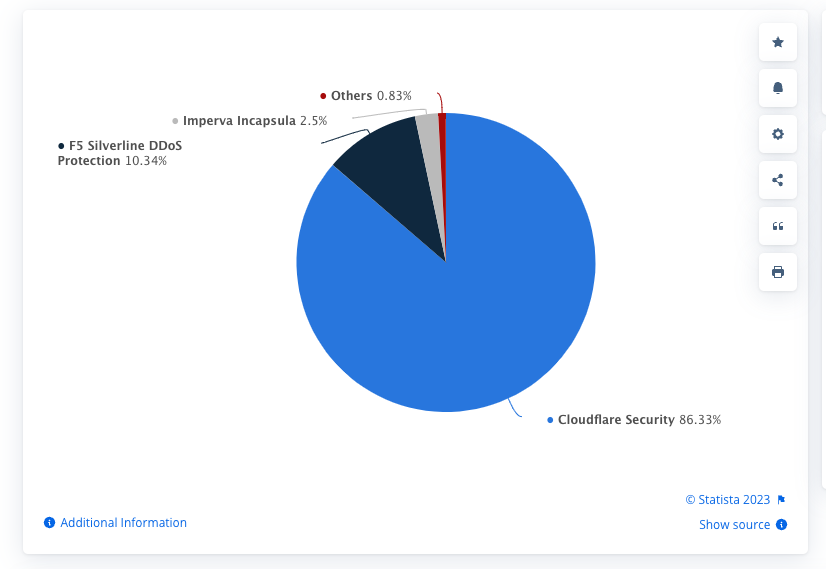
So, if you’re doing web scraping on a medium-large project, I’m pretty sure you’ve encountered a website protected by Cloudflare.
You can easily check its presence by using the Wappalyzer Chrome Extension when browsing your target website.
If you’re trying to use Scrapy on a website protected by Cloudflare, your scraper will get immediately a 429 error and cannot proceed further.
How does Cloudflare Bot Protection work?
Cloudflare does not open source the whole code behind its technology and it’s quite obvious the reason for this: it would be too easy to understand the criteria behind the bot detection and consequently create scrapers who could bypass it, making the software unuseful.
There are some people who try to reverse-engineer the API call behind the challenges and try to figure out how they work, but I’m not one of them. It takes too much effort for too long time, and once there’s an update on the software, you need to start again.
So my understanding of its functioning comes from my experience, my trial and error, and the study of the key principles of bot detection, whose implementation may vary for any anti-bot solution vendor.
Sometimes my guess could be wrong, and we’ll see later in this article that until you test something on the ground, you cannot be sure of the outcome.
To add some entropy, every website can set its own rules, so a solution could work for one website but not for another one.
Cloudflare Turnstile: the noCaptcha Captcha
We’ve already dedicated a whole post about Cloudflare Turnstile if you want to know more about it.
It’s basically a Javascript challenge that is triggered if Cloudflare thinks your request is not reliable enough to go straight to the website. If this is the case, the Captcha will appear in your browser and will solve by itself if everything ok or could require you to tick a box if the software is still unsure about the trustworthiness of your connection.
Once you get past the challenge, you receive a cookie which is your green pass for the whole website. I suppose that, depending on the website, the challenge could be thrown again after an established amount of time.
Unlike the good old Captchas, which are based on proof-of-work since you need to complete a task to get past, Turnstile is based on direct detection of the anti-bot software. While for the end-user this solution is preferable since in most cases is transparent, if someone uses a peculiar configuration (like a proxy network or a VPN), this setup may create some accessibility issues and there’s no way to bypass it since you don’t have to complete any task to prove you’re human.
On the other side, for web scrapers this solution is always challenging since you need to impersonate a real user on a real browser with a proper hardware configuration, since there’s no task to complete to bypass the Captcha, with a proper configuration it becomes easier to scrape data.
Fingerprinting the website’s visitors
But how does Cloudflare decide if your request needs to be challenged with Turnstile or if it’s a legit one?
As always is a mixture of rules with a sensitivity that probably changes from website to website, but the main techniques are the usual ones we’ve already seen on these pages:
IP reputation and type: given your IP, there are a bunch of services that calculate its reputation, by checking inside lists of blacklisted addresses. If found, it could be a red flag because that address could have been used in the past for DDoS attacks or sending spam. Another attribute checked if it’s an IP included in the ranges of addresses of data centers, like AWS, which could be a sign of automated access to the website and not from home.
Fingerprinting: this happens when, given your hardware and software environment, the anti-bot solution creates your fingerprint, compares it to a database of legit fingerprints, and assigns to your session a degree of trustworthiness. This is true at different hardware and software layers, from TLS layer to the browser configuration, giving the anti-bot an incredibly fine-grained picture of your running environment.
Javascript challenges: related to fingerprinting techniques, some Javascript code could be executed inside your browser, and from its result, the anti-bot software could detect your browser fingerprint. Of course, these scripts require a headful browser to be executed and the incapability of doing so is a red flag that could signal an automation software.
Given these three factors, as mentioned before, my solution was to use Playwright with a real browser running from a data center. After one of the previous updates, it became needed for certain websites to use residential proxies on top of this solution, making it economically inconvenient compared to the cheapest web unblockers on the market, so I’ve decided to switch to them for better reliability.
But two/three weeks ago, some of these unblockers stopped working with Cloudflare and I needed to find another solution, and while I was working on the previous post I saw this Scrapy Impersonate package and decided to give it a try.
If you want to see the code and how I’ve implemented the solution, you can see it on the GitHub repository available only for paying readers.
If you’re one of them but don’t have access to it, please write me at pier@thewebscraping.club to obtain it.
