
THE LAB #21 - Bypass anti-bot challenges with AI
How Nimble Browser performs against the most famous anti-bot solutions like Cloudflare, Datadome, Perimeterx, Kasada and F5

This is the month of AI on The Web Scraping Club, in collaboration with Nimble.
During this period, we'll learn more about how AI can be used for web scraping and its state of the art, I'll try some cool products, and try to imagine how the future will look for the industry and, at the end of the month, a great surprise for all the readers.

And we could not have a better partner for this journey: AI applied to web scraping is the core expertise of the company and I’m sure we will learn something new by the end of the month.
June is going to end soon and so is the AI month, in collaboration with Nimble. We talked about the future of AI and web scraping, how models depend on web data, and the changing landscape for the industry. Today we’ll be much more practical, using our classic testing methodology to see if the AI included in the Nimble browser could defeat the AI used in the most common anti-bot solutions.
AI vs AI: is this the anti-bot endgame?
Today, artificial intelligence is everywhere, and anti-bot solutions are not exempt from it.
If you open their website, you’ll read sentences like
Cloudflare’s Machine Learning trains on a curated subset of hundreds of billions of requests per day to create a reliable bot score for every request.
or
DataDome processes, in real time, 3 trillion data signals from client-side and server-side detection every day. Every single request to your mobile apps, websites, and APIs is analyzed and subjected to AI/machine learning models to determine in less than 2 milliseconds whether or not access should be granted to block threats from the first request.
For years, anti-bot solutions are using the billions of data points they receive daily, to train AI models to detect anomalies in fingerprints or user behavior.
At the same time, AI can also be used to generate reliable fingerprints and mimic human behavior, so it’s becoming a war between AI Models.

In the past, we’ve already tested the “web unblocker” solutions in our “Hands On” series and today we’ll use the Nimble browser, a headful and automated browser specifically studied for web scraping, to check if it could defeat the most common anti-bot solutions.
The testing methodology
For each of the five anti-bot selected for the tests (Cloudflare, Datadome, Kasada, F5, PerimeterX), I’ve picked five random product URLs.
I’ll always ask the browser to render the page, maybe it could be an overshoot, but at least we know that a certain anti-bot can be bypassed without making too much back and forth.
The output for each request is composed of a JSON containing both the HTML of the page and a parsed version of it. We’ve already seen that this works particularly well for marketplaces like Amazon or Walmart, not included in the test, while for smaller websites the API usually returns the product’s JSON schema.
The results of the test represent the actual situation of the product that, being quite new and with a great team behind, has large margins for improvements.
According to Statista in 2022 the anti-bot market was dominated by Cloudflare, with more than 80% of the market share, followed by F5, Imperva, and others. We’ll follow the same order.
All the code used in the test can be found in the GitHub repository of The Lab, reserved for paying readers.
Nimble Browser Vs Cloudflare
Let’s start with the main course, tackling Cloudflare at its highest level of security, like we one we encountered on Harrod’s website.
After declaring the proxy variable with the Nimble credentials, we can use some simple Python requests to try to collect data.
cloudflare_urls=['https://www.harrods.com/en-it/shopping/aquazzura-leather-tequila-sandals-105-19433559',
'https://www.harrods.com/en-it/shopping/manolo-blahnik-satin-nadira-pumps-90-19061500',
'https://www.harrods.com/en-it/shopping/arizona-love-leopard-print-trekky-sandals-19228612',
'https://www.harrods.com/en-it/shopping/aquazzura-embellished-mini-tequila-sandals-105-19434138',
'https://www.harrods.com/en-it/shopping/aquazzura-embellished-mini-tequila-sandals-105-19434138']
for url in cloudflare_urls:
cloudflare_data = requests.get(url,
proxies=proxies, headers={'x-nimble-render':'true', 'x-nimble-parse': 'true'},verify=False)
cloudflare_json=json.loads(cloudflare_data.text)
print(cloudflare_json['parsing'])And the test is passed! ✅
Here’s an example of parsed results, as mentioned before we get the product schema, but it’s enough for us to have all the data we need without writing a scraper.
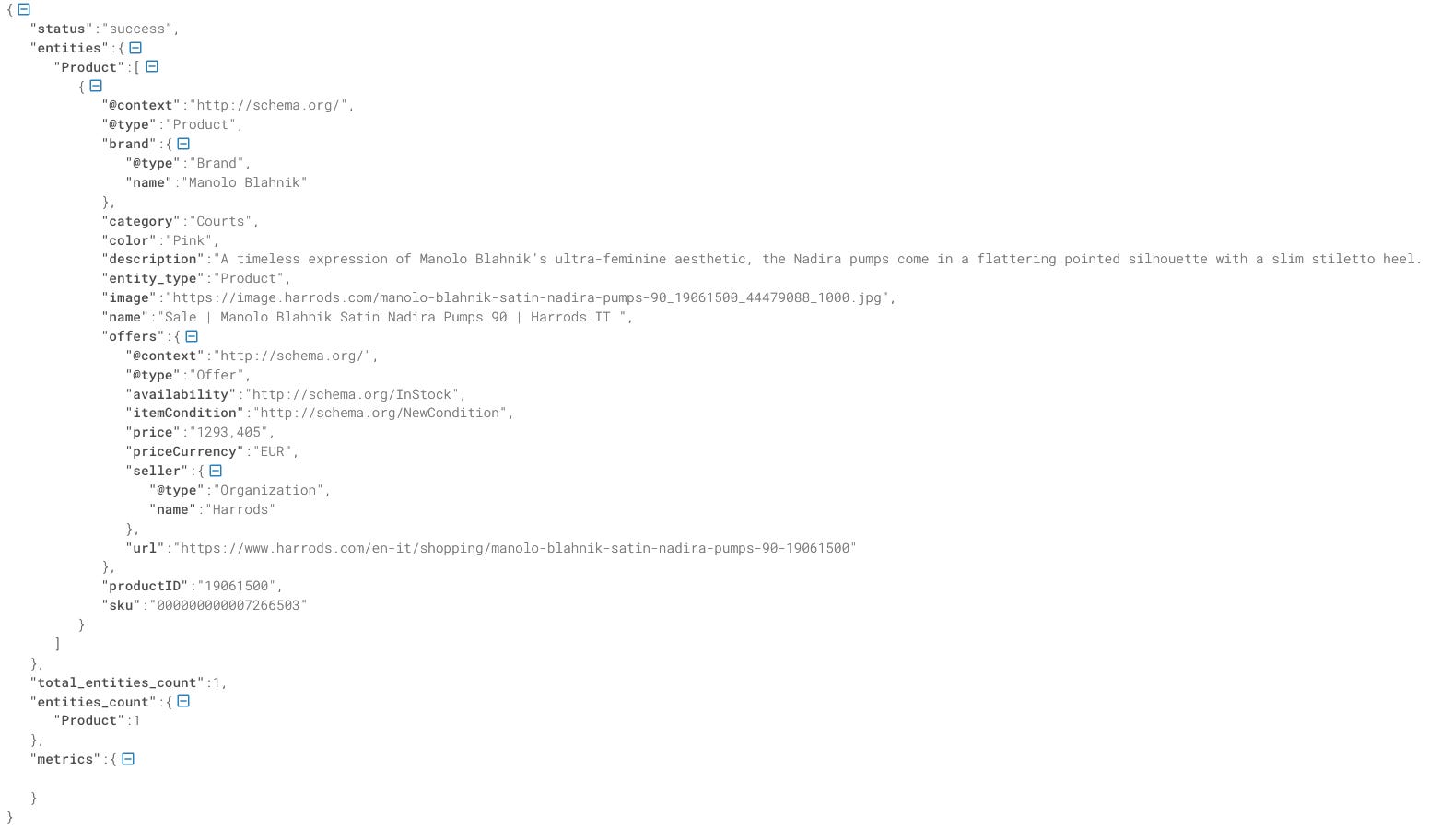
Since Cloudflare is the most diffused anti-bot, with more than 80% of the market share, this is a great result!
Nimble Browser Vs F5 (former Shape)
Performing the same test on Nordstrom's website gave slightly different results.
While the anti-bot has been bypassed, the Browser cannot parse the output because the HTML returned is obfuscated and not readable.
Unluckily for F5 the test is not passed ❌
Nimble Browser Vs Datadome
Here’s another famous anti-bot who’s gaining traction, I honestly was surprised to don’t find it mentioned in the Statista report. In my experience in e-commerce web scraping, I’ve seen much more websites protected with Datadome rather than F5.
I’ve tested Nimble Browser on the Footlocker Italian website and it performed greatly, as you can see from the parsed output.

So test passed! ✅
Nimble Browser Vs PerimeterX
As per Datadome, I would have expected PerimtereX to be mentioned on the report since I’ve seen much more websites protected with PerimeterX than with F5.
One of them is Neiman Marcus and I’ve tested the Nimble Browser on it, with the following result.

This means, another test passed for the Nimble Browser ✅
Nimble Browser Vs Kasada
This is a niche solution that I’ve seen only one time in my entire career so I usually have low expectations when I test some tools against it.
Unluckily in this case the test fails, since the Browser cannot retrieve any data from the website. ❌
Final remarks
When you need to solve a challenge, in any field of life, it’s always good to follow the Pareto rule. Ask yourself: “On what I should focus first, to solve the greatest part of the problem?”.
And here it seems what they have done at Nimble: they focused on a solution that works in the vast majority of cases, and that’s a great one. With a simple Python request, you don’t only bypass the anti-bot but have already the results you need, without writing any scraper. This is a great case of AI helping save time and money for companies doing web scraping today.