In this second article, you’ll get your hands on the code so that you can learn how to implement sentiment analysis practically.
Let’s dive in!
Before proceeding, let me thank Decodo, the platinum partner of the month. They are currently running a 50% off promo on our residential proxies using the code RESI50.
How to Scrape Amazon Products With Bright Data: Step-by-step Tutorial
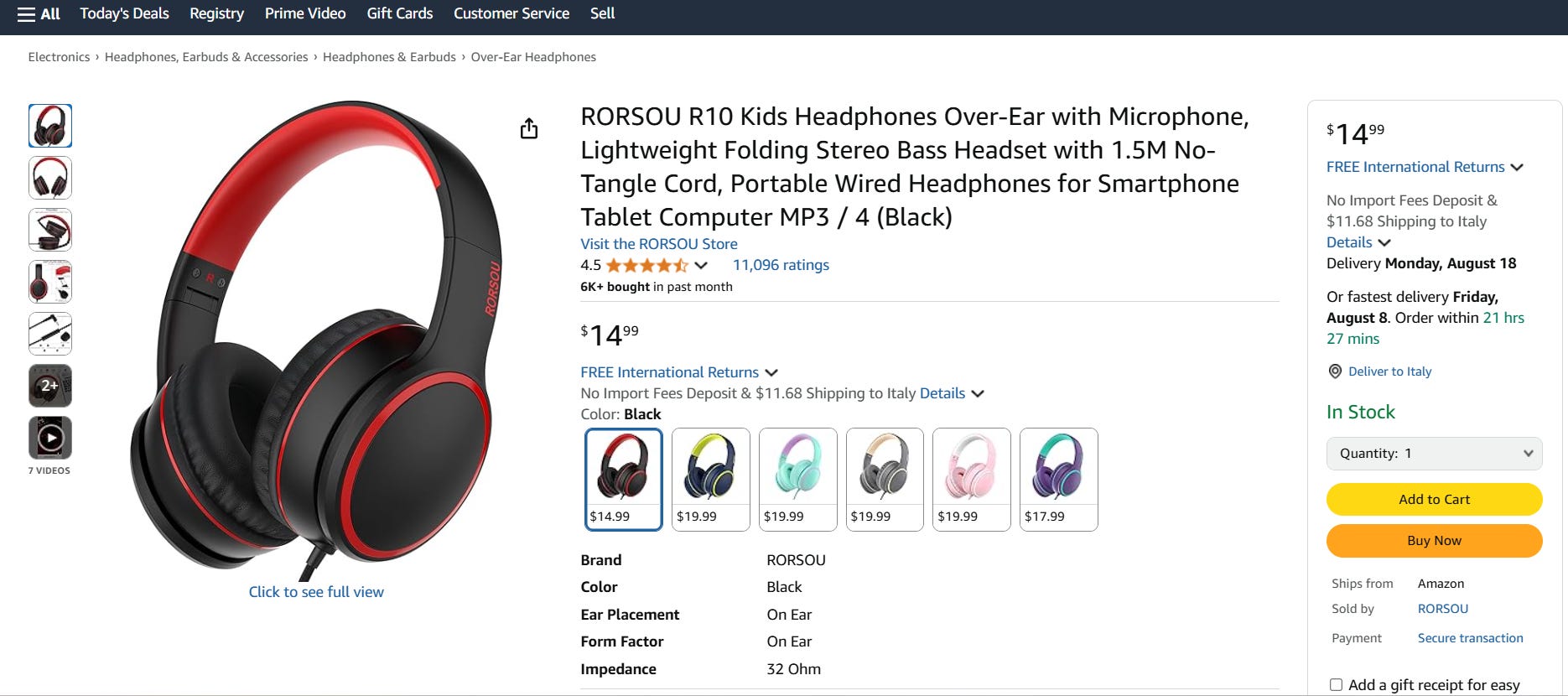
First things first: you need to retrieve Amazon data from the web. In this tutorial section, I’ll show you how to do so using Bright Data’s Scraper APIs. The target products of this scraping section are headphones:
In particular, the scraper will retrieve all the data from three different brands:
Follow the upcoming steps to learn how to use Bright Data’s Scraper APIs to retrieve the data of all three products.
This episode is brought to you by our Gold Partners. Be sure to have a look at the Club Deals page to discover their generous offers available for the TWSC readers.
In the activated virtual environment, install the dependencies with:
pip install requests
Great! You are now ready to get the data of interest using the Scraper APIs by Bright Data.
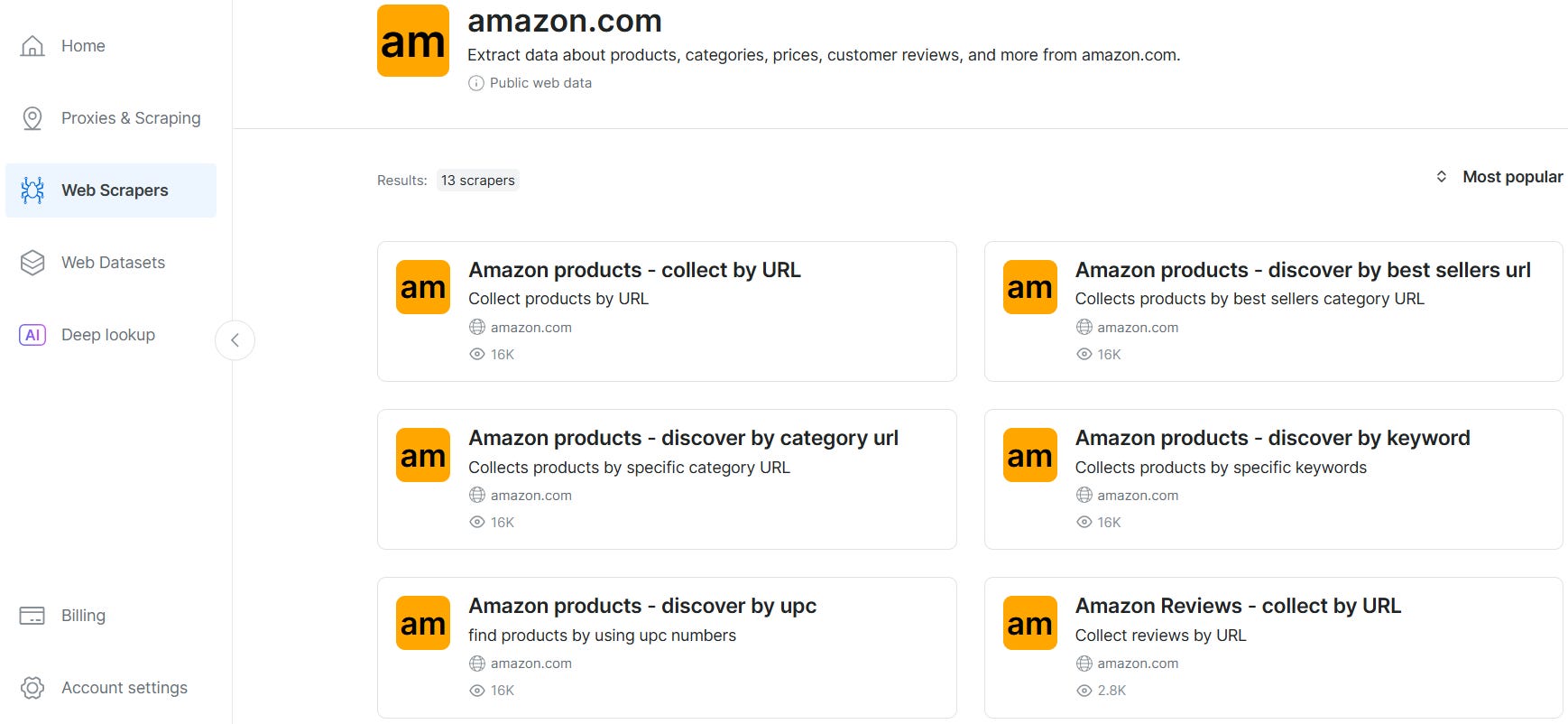
Retrieving The Data With The Web Scraper APIs
When you want to use Bright Data’s Web Scraper APIs for retrieving Amazon data, you can choose among several possibilities:
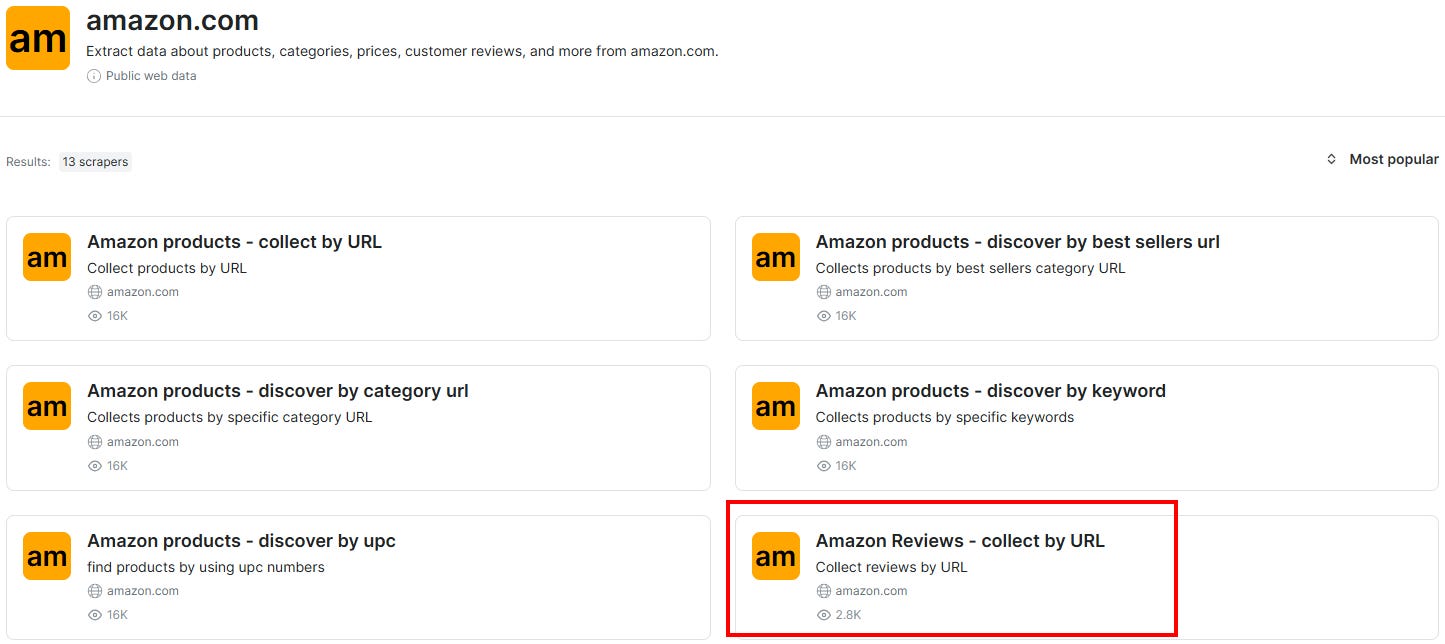
The products you are going to scrape are fairly simple. They are all headphones with a microphone, and they are all within the same pricing range. For this reason, in this case, you can just focus on the products’ reviews without retrieving all the available data.
To do so, you can choose the “Amazon Reviews - collect by URL” option:
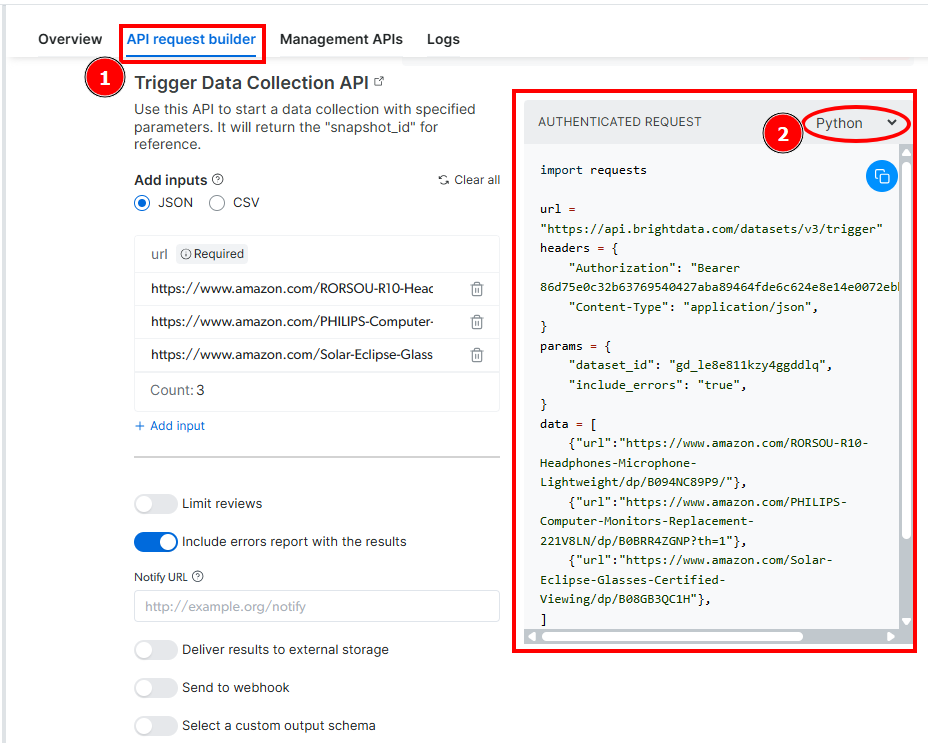
The API Request builder provides you with a sample code in your preferred language:
This code is a sample and needs to be modified to scrape the data you are interested in. However, it is important to note that the url, headers, and params must be copied and pasted as is in your code editor. In particular, the dataset_id inside parameters is the parameter that identifies unequivocaly the “Amazon Reviews - collect by URL” API.
Below is how you can change the sample code to download the reviews of the three target headphones:
import requests
import json
import time
def trigger_amazon_products_scraping(api_key, urls):
# Endpoint to trigger the Web Scraper API task
url = "<https://api.brightdata.com/datasets/v3/trigger>"
params = {
"dataset_id": "gd_le8e811kzy4ggddlq",
"include_errors": "true",
}
# Convert the input data in the desired format to call the API
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"<https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json>"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
# Write the snapshot to an output json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "<your_api_key>" # Replace it with your Bright Data's Web Scraper API key
# URLs of products to retrieve data from
urls = [
"<https://www.amazon.com/RORSOU-R10-Headphones-Microphone-Lightweight/dp/B094NC89P9/>",
"<https://www.amazon.com/LORELEI-X8-Headphones-1-45m-Tangle-Free-Lightweight/dp/B08JCD23MJ/ref=pd_sbs_d_sccl_1_4/147-2299959-1156345?pd_rd_w=pXlbk&content-id=amzn1.sym.2cd14f8d-eb5c-4042-b934-4a05eafd2874&pf_rd_p=2cd14f8d-eb5c-4042-b934-4a05eafd2874&pf_rd_r=ZR6PBH01PN0XEDXQTGK0&pd_rd_wg=e75eK&pd_rd_r=7480cd35-089c-4496-85f4-40260ceaad5b&pd_rd_i=B08JCD23MJ&th=1>",
"<https://www.amazon.com/Elecder-i45-Ear-Headphones-Microphone/dp/B09XV4BSF1/ref=pd_ci_mcx_di_int_sccai_cn_d_sccl_1_5/147-2299959-1156345?pd_rd_w=1ayEt&content-id=amzn1.sym.751acc83-5c05-42d0-a15e-303622651e1e&pf_rd_p=751acc83-5c05-42d0-a15e-303622651e1e&pf_rd_r=ZEB73ZEF1CZ7G2K1F41Q&pd_rd_wg=Oy6rE&pd_rd_r=9ce1e5bc-3f99-4d27-8798-912550a7393a&pd_rd_i=B09XV4BSF1&th=1>"
]
snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "amazon-data.json")
In this code:
The trigger_amazon_products_scraping() method takes care of triggering the endpoint to retrieve the data. As you can see, the code is similar to the sample code you’ve seen above. The major change lies in the data parameter. In this case, you need to use a list comprehension because you want to scrape the URL of more than one Amazon product. The function also takes care of managing the response to the snapshot.
The poll_and_retrieve_snapshot() method is the one that actually retrieves the data as it triggers the snapshot endpoint.
The final part of the script manages your API key and the URLS of the products to retrieve the data from (the urls parameter).
When the process is completed, the data will be saved in the amazon-data.json file. Below is a scraped data result example:
{
"url": "<https://www.amazon.com/Elecder-i45-Ear-Headphones-Microphone/dp/B09XV4BSF1/ref=pd_ci_mcx_di_int_sccai_cn_d_sccl_1_5/147-2299959-1156345?pd_rd_w=1ayEt&content-id=amzn1.sym.751acc83-5c05-42d0-a15e-303622651e1e&pf_rd_p=751acc83-5c05-42d0-a15e-303622651e1e&pf_rd_r=ZEB73ZEF1CZ7G2K1F41Q&pd_rd_wg=Oy6rE&pd_rd_r=9ce1e5bc-3f99-4d27-8798-912550a7393a&pd_rd_i=B09XV4BSF1&th=1>",
"product_name": "ELECDER i45 Headphones Wired, On-Ear Headphones with Microphone, Foldable Stereo Bass, 1.5M No-Tangle Cord, Portable 3.5MM Headset for School Kids Teens Smartphones Computer PC Tablet Travel, Purple",
"product_rating": 4.5,
"product_rating_object": {
"one_star": 104,
"two_star": 70,
"three_star": 209,
"four_star": 488,
"five_star": 2612
},
"product_rating_max": 5,
"rating": 5,
"author_name": "Teri Flora",
"asin": "B09XV4BSF1",
"product_rating_count": 3483,
"review_header": "Great purchase!",
"review_id": "R2R32MENIFBWY2",
"review_text": "These are perfect for when everyone is watching something different on their tablets in the living room. We use them everyday. They are comfortable and the price is great!",
"author_id": "AGLHA7QU4D6OIOGT2BZRDYFJVDXQ",
"author_link": "<https://www.amazon.com/gp/profile/amzn1.account.AGLHA7QU4D6OIOGT2BZRDYFJVDXQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8>",
"badge": "Verified Purchase",
"brand": "ELECDER",
"review_posted_date": "July 15, 2025",
"review_country": "United States",
"helpful_count": 0,
"is_amazon_vine": false,
"is_verified": true,
"variant_asin": "B0BF525Z32",
"variant_name": "Color: Pink",
"videos": null,
"categories": [
"Electronics",
"Headphones, Earbuds & Accessories",
"Headphones & Earbuds",
"On-Ear Headphones"
],
"department": "Electronics",
"timestamp": "2025-07-22T07:51:00.017Z",
"input": {
"url": "<https://www.amazon.com/Elecder-i45-Ear-Headphones-Microphone/dp/B09XV4BSF1/ref=pd_ci_mcx_di_int_sccai_cn_d_sccl_1_5/147-2299959-1156345?pd_rd_w=1ayEt&content-id=amzn1.sym.751acc83-5c05-42d0-a15e-303622651e1e&pf_rd_p=751acc83-5c05-42d0-a15e-303622651e1e&pf_rd_r=ZEB73ZEF1CZ7G2K1F41Q&pd_rd_wg=Oy6rE&pd_rd_r=9ce1e5bc-3f99-4d27-8798-912550a7393a&pd_rd_i=B09XV4BSF1&th=1>"
}
}
As you can see, you are able to access lots of data related to the review. The field you’ll be using later is review_text, which is the one that stores the content of the reviews.
Very well! You scraped the review data from all the target products in a matter of seconds using Bright Data’s Web Scraper APIs. You are now ready to go through the sentiment analysis.
Before continuing with the article, I wanted to let you know that I've started my community in Circle. It’s a place where we can share our experiences and knowledge, and it’s included in your subscription. Give it a try at this link.
Setting Up Jupyter Notebook and Installing Dependencies
Before going through the process of sentiment analysis, you need to install other dependencies and set up Jupyter Notebook. The notebook is useful for analyzing data as it allows you to visualize results via the UI.