
The Framework That Won't Quit: Scrapy's Continued Relevance in Data Extraction
Mature, not obsolete: making the case for Scrapy in the modern web scraping environment.

If you’ve been in web scraping for a while, you know that it’s a field that seems like it reinvents itself every couple of years:
New frameworks explode onto the scene.
Anti-bot measures become sophisticated enough to require PhDs.
APIs become the promised land.
And now, LLMs are promising to automate everything.
In this tornado of news, it’s easy to get caught up in the hype cycle, chasing the shiniest new tool or framework.
And yet... there’s Scrapy! Scrapy feels almost... venerable. In our industry, we’ve seen the rise (and sometimes the fall) of countless libraries and approaches in the last decade. So, a question hangs in the air: is Scrapy still relevant?
Well, I’m here to argue: absolutely yes!
Scrapy's longevity isn't an accident or a sign of stagnation. It's a testament to a brilliant architectural design. Let's peel back the layers and understand why Scrapy remains an indispensable tool.
Before proceeding, let me thank NetNut, the platinum partner of the month. They have prepared a juicy offer for you: up to 1 TB of web unblocker for free.
Scrapy’s Core: Asynchronous I/O From The Ground Up
When you scrape websites, you often encounter the necessity of performing asynchronous requests. This necessity may come in different situations:
You are scraping a high-traffic website.
Your requests are too much, and the server can not respond to all.
Blocking systems.
Also, your scraper spends most of its time not crunching numbers, but waiting for:
DNS resolution.
The server to respond.
Data to trickle down the wire.
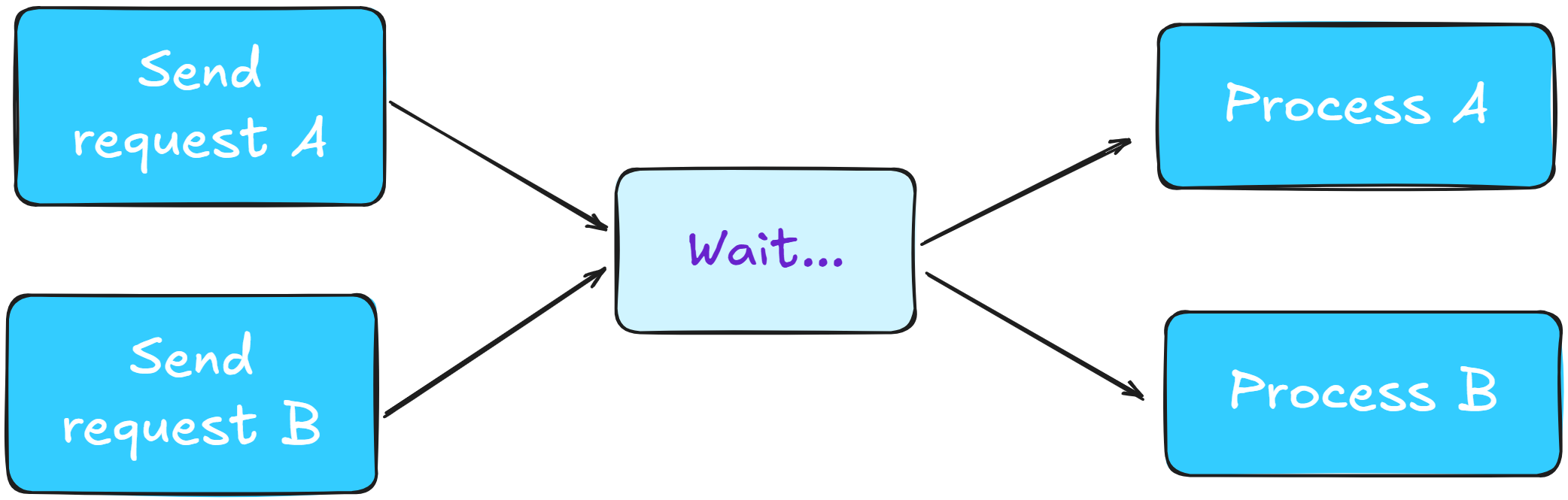
So, let’s consider a simple scenario where you need to send two requests, A and B. A synchronous approach handles waits linearly:
Send request A.
Wait.
Process A.
Send request B.
Wait.
Process B.

This approach it's simple to reason about, but incredibly slow when you need to fetch a big amount of data. Also, if requests A fails for any reason, request B is not initiated, and you need to restart the process from the beginning. An asynchronous approach, instead, handles waits concurrently, allowing other tasks to proceed while waiting for responses:
Initiate request A**.** (Send it off)
Initiate request B**.** (Send it off immediately after A, without waiting for A's response)
Wait for either A or B to complete**.** (The program doesn't block; it can potentially do other work or simply wait)
When A's response arrives, process A**.** (This might happen before or after B's response arrives)
When B's response arrives, process B**.** (This might happen before or after A's response arrives)
Thanks to the gold partners of the month: Smartproxy, IPRoyal, Oxylabs, Massive, Rayobyte, Scrapeless, SOAX, ScraperAPI, and Syphoon. They’re offering great deals to the community. Have a look yourself.
The key difference is that the waiting periods for requests A and B overlap. Instead of waiting for A, processing A, then waiting for B, and processing B (linear execution), the asynchronous approach sends both requests out and then processes the responses as they become available.
So, since using asynchronous requests is a frequent need in web scraping, this is the point:
If you use libraries such as Requests, BeautifulSoup, Selenium, or any other, you need to manually set up asynchronous requests. Typically, this involves using the libraries *asyncio and* AIOHTTP.
Scrapy provides asynchronous requests natively.
While there’s nothing wrong with writing custom code for making asynchronous requests, this Scrapy’s native feature is a fundamental, enduring performance. Scrapy is built on top the Twisted—an event-driven networking framework for Python. At its core, Twisted is built around a concept called the Reactor. Think of it as a central loop that constantly does two things:
Waits for events: These events can be network activity, timers expiring, file descriptors becoming readable or writable, or any others.
Dispatches events: When an event occurs, the Reactor triggers the specific function that was registered to handle that type of event for that specific resource.
This way, Scrapy uses non-blocking I/O via Twisted. It sends a request and, instead of waiting, moves on to other tasks. When a response arrives, Twisted notifies Scrapy, which picks up processing where it left off for that specific request.
Thanks to this built-in integration, Scrapy provides:
High throughput: This concurrency model allows Scrapy to send hundreds or even thousands of simultaneous connections, limited primarily by network bandwidth and server availability, not by waiting sequentially. This is important in different situations, particularly for large-scale scraping.
Resource efficiency: Scrapy's Twisted-based engine is highly optimized for network tasks and provides a robust framework for managing concurrency.
Foundation for everything else: This async core grounds the entire framework, enabling features like the Scheduler, Downloader, and Item Pipelines to operate efficiently without blocking each other.
Scrapy's Modular Architecture: Separation of Concerns
Complementing its asynchronous processing core, Scrapy employs a highly modular architecture based on the principle of separation of concerns. This design partitions the framework's functionality into distinct, interacting components:
**Engine:** Is the central component responsible for orchestrating data flow among all other modules.
Scheduler: Manages the queue of pending requests, implementing logic for prioritization and deduplication.
Downloader: Fetches web pages, handling the actual HTTP requests and responses.
**Spiders:** User-defined classes containing the primary crawling logic.
Item pipelines: A sequence of components dedicated to the post-processing of extracted items.
Middlewares: Extensible interfaces positioned within the request/response cycle (Downloader Middlewares) and the spider processing workflow (Spider Middlewares), allowing for the injection of custom logic and modifications.

This architectural design represents a deliberate implementation of the separation of concerns principle, where each component encapsulates a distinct responsibility within the web scraping process. Its adoption provides several advantages, like:
Maintainability and debugging: The separation of functionalities facilitates targeted debugging and system maintenance. Issues can be isolated to specific components based on their nature.
Testability: The architecture enhances testability by enabling individual components to be unit-tested in isolation. For example, a Spider's parsing logic can be validated using locally stored HTML content, decoupling the test from network operations.
Team collaboration: The defined interfaces and responsibilities of each component support team collaboration on large projects. Different engineers or teams can work concurrently on distinct modules with minimized integration conflicts.
Reusability: The design promotes component reusability across different Scrapy projects. Standardized interfaces allow for the development of generic Item Pipelines or Middlewares that can be incorporated into various scraping applications.
I had the privilege to chat with Shane Evans, CEO of Zyte, about the 10 years of Scrapy.
To learn more, watch the interview on The Web Scraping Club's YouTube channel.
Extensibility Mechanisms: Middlewares and Item Pipelines
A defining characteristic of the Scrapy framework is its extensibility, facilitated through its Middleware and Item Pipeline systems. These mechanisms allow developers to customize the core crawling process to address complex requirements beyond basic data extraction.
Let’s see them more in depth.
Downloader Middlewares
Positioned between the Engine and the Downloader, these middlewares process:
Outgoing requests before they are dispatched to the target server.
Incoming responses upon receipt from the Downloader.
This layer is the primary interface for implementing network-level customizations and addressing anti-scraping countermeasures. Here are some typical custom use cases for downloader middlewares:
Proxy management: You can implement logic for rotating IP addresses, managing proxy sessions, and handling proxy-specific error conditions or rate limits beyond only proxies randomized selection.
User-Agent rotation: Dynamically cycle through realistic User-Agent strings and associated headers to lower the possibilities of being blocked.
Custom retry logic: You can implement tailored retry strategies, such as exponential backoff, handling non-standard HTTP status codes indicative of temporary blocks, or re-issuing requests with modified parameters.
Request signing/authentication: Injecting generated tokens, managing session cookies across multiple requests, or constructing complex authentication headers required by specific web services or APIs.
Spider Middlewares
Positioned between the Engine and the Spiders, these middlewares can:
Process responses returned from the Downloader before they invoke the spider's parsing callback methods.
Intercept requests and items yielded by the spider.
Here are some typical custom use cases for spider middlewares:
Response filtering: Discarding irrelevant responses based on content analysis or header inspection before they consume spider processing resources.
Response modification: Performing preliminary processing on response content before parsing by the spider's selectors.
Dynamic spider configuration: Adjusting spider attributes or behavior based on characteristics of initial responses or external configuration sources.
Global request filtering: Implementing sophisticated duplicate request detection based on criteria beyond the URL alone.
Item Pipelines: The Data Processing Sequence
After a Spider extracts data, it enters the Item Pipeline. The Item Pipeline represents a configurable sequence of components, each executing a specific, ordered processing step. Pipelines enable post-extraction data handling like the following:
Data cleaning and normalization: Performing operations such as whitespace stripping, data type conversion, date format standardization, and resolution of relative URLs to absolute forms.
Validation: Enforcing data integrity by verifying the presence of required fields and ensuring data conforms to predefined schemas or value ranges.
Deduplication: Preventing the processing and storage of duplicate items by checking against previously seen items, typically based on a unique identifier field within the item.
Data enrichment: Augmenting scraped items with additional information from internal databases or external APIs.
Multiple storage destinations: Persisting processed items to various storage systems concurrently, such as writing to a primary relational database, archiving to a NoSQL store, and publishing to a message queue for downstream real-time consumption.
Image/File downloading: Scrapy's ImagesPipeline or FilesPipeline allows you to asynchronously download associated media files referenced within items, manage storage paths, and prevent redundant downloads.
Performance Optimization, Scalability, and Network Politeness Mechanisms
Scrapy is designed for high-throughput network operations. Beyond raw speed, it incorporates configurable mechanisms to manage performance, scale effectively, and adhere to responsible crawling practices by mitigating target server load, like:
AutoThrottle: This built-in extension dynamically adjusts request concurrency and download delays based on observed network latency and server response times. It aims to maximize throughput while respecting server capacity. It also automatically slows down when servers appear overloaded and speeds up when they respond quickly. Custom configuration allows tuning its sensitivity and target concurrency.
Concurrency controls: Settings like CONCURRENT_REQUESTS, CONCURRENT_REQUESTS_PER_DOMAIN, CONCURRENT_REQUESTS_PER_IP allow fine-tuning parallelism.
Download delays: The DOWNLOAD_DELAY setting enforces a fixed minimum waiting period between consecutive requests sent to the same domain or IP. This provides a predictable throttling mechanism.
Robots.txt: Obeys robots.txt rules by default. This behavior can be explicitly disabled if necessary, but adherence is standard practice for ethical scraping.
Scrapy Integration in The Modern Technology Stacks
Scrapy’s utility is amplified by its capacity to integrate within the contemporary technological ecosystems, particularly concerning:
JavaScript-intensive web applications.
Advanced anti-bot mechanisms.
The increasing prevalence of Artificial Intelligence (AI).
Addressing JavaScript-Rendered Content With Scrapy
Scrapy's core functionality is parsing static HTML and XML documents retrieved via HTTP requests. In particular, Scrapy’s Selectors is a wrapper around the library Parsel. This is for the purpose of providing better integration with Scrapy Response objects, as Parsel uses the lxml library under the hood, and implements an easy API on top of the lxml API.
So, Scrapy does not natively execute client-side JavaScript, which is a limitation when targeting websites where content is dynamically rendered or loaded post-initial page load. Common strategies to bridge this gap are:
Integration with Splash: This approach uses Splash, a lightweight, headless browser service. By routing requests through a Splash instance via dedicated Scrapy middleware (called scrapy_splash), you can leverage Splash's rendering engine. Splash executes JavaScript and can perform browser interactions defined by Lua scripts before returning the resultant HTML DOM to the Scrapy spider for conventional parsing. This method integrates browser rendering within a controlled service.
Orchestration with full browser automation tools: For interactions demanding complex browser automation or where Splash capabilities are insufficient, a common architectural pattern involves using Scrapy as the primary crawl orchestrator while delegating JavaScript-dependent tasks. In this case, Scrapy identifies URLs requiring browser rendering and interaction. Independent worker processes, utilizing libraries such as Playwright or Puppeteer, consume tasks
Management of Advanced Proxy and Anti-Detection Measures
Scrapy's architecture—particularly its Downloader Middleware system—provides a robust framework for integrating proxy management and anti-detection strategies. Scrapy itself does not provide proxy infrastructure, but it can be integrated with third-party proxy services or custom-built rotation systems. Common functionalities include:
Integrate with specialized proxy services: This includes leveraging large pools of residential or mobile IPs—which are less likely to be flagged than datacenter proxies—and managing geo-targeting or session stickiness. This also extends to integrating with proxy management APIs that handle rotation, blacklisting, and health checks automatically.
Implement advanced fingerprinting countermeasures: This involves not just rotating User-Agents, but also mimicking consistent and realistic browser fingerprints. This can include several technical aspects and even mimicking typical human browsing timings and mouse movements when combined with browser automation tools. These can be managed by integrating with external libraries or APIs specifically designed for generating and managing these complex fingerprints.
Handle dynamic challenges: You can develop logic to detect and attempt to solve CAPTCHAs, often by integrating with third-party solving services.
Orchestrate request patterns: You can create middlewares that adapt request rates, headers, and proxy usage dynamically based on server responses, observed error patterns, or even the perceived "strictness" of the target site.
Synergies With Large Language Models (LLMs)
The rise of Large Language Models (LLMs) doesn't signal the end for Scrapy. Instead, it opens up powerful new avenues for synergy.
In fact, the Item Pipelines—identified by the pipelines.py file at the code level—can be extended to incorporate AI-driven data processing for implementing tasks like:
Nuanced information extraction: LLMs can identify and extract specific pieces of information from text that might be difficult to extract with selectors alone. This can involve specific tasks like extracting product specifications from a descriptive paragraph, identifying key individuals and their roles in an article, or pulling out event details from unstructured announcements.
Data Structuring: Thanks to LLMs, you can convert blocks of unstructured text into structured formats like JSON or CSV easily. For example, you can transform a free-form product description into a set of key-value pairs for features.
Classification and categorization: By integrating an LLM with Scrapy you can automatically classify scraped content into predefined categories or tag items with relevant keywords.
Data cleaning and normalization: LLMs can assist in cleaning messy text data, correcting typos, standardizing formats, and more. And you can do so in the same environment if you integrate an LLM with Scrapy, reducing the overhead of context switching.
As a final not, consider that implementing this approach also requires consideration of factors like API costs, latency implications, and the use of asynchronous techniques within the pipeline to handle potentially blocking API calls efficiently.
Conclusion
While web scraping is characterized by rapid evolution and the constant emergence of new tools and techniques, Scrapy stands firm. Its modular architecture, and extensibility have allowed it to remain relevant and far from being made obsolete by modern challenges.
What’s your experience with Scrapy? Let’s discuss it in the comments!
Great summary of Scrapy's journey and its role in the web scraping ecosystem over the past decade!
Earlier this year, in February, I hosted a webinar in collaboration with Zyte where we explored how to bypass Cloudflare Turnstile using Scrapy. It was a hands-on session focused on practical implementation, and we also published an article about it.
Here's the link to the webinar: https://vimeo.com/1059738822
And here's the article: https://kameleo.io/blog/how-to-bypass-cloudflare-turnstile-with-scrapy
Might be an interesting addition for those diving deeper into using Scrapy for real-world challenges.
Thanks again for the great post!