
THE LAB #81: Scraping Zillow for fun and profit
Get real estate data from the biggest US website

Real estate has long been one of the first interesting use cases for web scraping, and for good reason. Housing data is rich with structured information – every listing has clear fields like price, address, number of bedrooms, etc., making it easy to extract and organize. Unlike personal social media data, property listings are public information, so there are minimal privacy concerns about scraping details about homes for sale.
When we started with Re Analytics 10 years ago, it was the first market we targeted, and we created around 100 scrapers for websites all around the globe. Those were definitely easier times.
In fact, another benefit is the consistency across markets: whether it’s Zillow in the U.S. or Rightmove in the UK, real estate websites tend to present data in similar formats, which means that the output data format and structure and the browsing logic of the websites are similar.
To put the importance of online real estate data in perspective, about 97% of homebuyers start their home search online. This means virtually all the information a buyer or investor might want – from prices to photos – should be available on listing sites.
The leading real estate portals attract massive traffic: Zillow, for example, gets over 200 million monthly visitors in the U.S. That signals huge interest from consumers and an abundance of accessible data that scrapers can harvest for analysis.
Today, we’re learning how to scrape data from one of the most important real estate websites in the US, Zillow. Next Sunday, we’ll see how we can monetize this data by selling it on a data marketplace like Databoutique.com.
What is Zillow?
Zillow is one of the largest real estate platforms in the United States, often the first stop for home shoppers and renters. Launched in 2006, it has grown into a real estate data powerhouse. Zillow’s database covers over 110 million U.S. properties (including homes for sale, for rent, and even off-market homes). Essentially, if it’s a house in America, odds are Zillow has some info on it.
The site’s popularity is staggering – it attracts around 200 million unique visitors each month, and according to the company, 80% of all homes in the United States have been viewed on Zillow at some point. In other words, four out of five houses have had the digital equivalent of a window shopper on Zillow!
This immense user base and inventory translate into serious business. Zillow makes money through advertising, lead sales to realtors, and other services, and those millions of eyeballs add up. In 2024, Zillow raked in about $2.2 billion in revenue, according to Marketscreener.com, highlighting how valuable this platform is in the real estate ecosystem.
Before proceeding, let me thank NetNut, the platinum partner of the month. They have prepared a juicy offer for you: up to 1 TB of web unblocker for free.
How to Look for Homes on Zillow
Let’s see now how the website works and how we can scrape data from it.

The site features a big map-based search interface. Typically, you might enter a location (city, ZIP code, or even an entire state) in the search bar, and Zillow will show a map of that area dotted with listings. Users can pan and zoom the map, and Zillow dynamically loads homes for sale or rent in the viewport. This map view is coupled with a list of properties on the side – as you move the map, the list updates to show the homes in that area. Or, as I did in the previous screenshot, you can select directly a state on the map and get all the listings from there.
To narrow things down, Zillow provides a slew of filters. You can filter by price range, number of bedrooms/bathrooms, home type (house, condo, townhouse, etc.), lot size, year built, and many more criteria. For example, a user might filter to see only 3-bedroom houses under $500,000 in a certain neighborhood. Zillow even allows drawing custom regions on the map to restrict your search to a specific area you outline.
In our case, the best way to proceed if we want to scrape Zillow data is to filter by state, so we don’t have to combine too many filters in our requests. Since the listings are available dynamically on a map and on a list, there will probably be an internal API that retrieves data. Let’s open the Network tab of the browser and check it out.
Thanks to the gold partners of the month: Smartproxy, Oxylabs, Massive, Scrapeless, Rayobyte, SOAX, ScraperAPI and IPRoyal. They prepared great offers for you, have a look at the Club Deals page.
Study of the Internal APIs
So, what powers Zillow’s map and search results behind the scenes? It turns out that every time you move that map or apply a filter, your browser is making calls to Zillow’s internal web APIs to fetch the updated list of homes.
When you perform a search on Zillow, the site sends a background request to a hidden search API with all the parameters of your search (location, filters, etc.). This request isn’t documented publicly – it’s an internal endpoint that the web app uses, but we can figure out the details by observing the traffic.
The core of Zillow’s search request is a JSON payload (or sometimes a query string) containing something called searchQueryState. This includes the map coordinates (the geographic bounding box of the area you’re looking at) as well as filter settings and the current results page number. For example, it will have fields for the west, east, south, and north boundaries of the map view to define the area. It also contains a regionSelection (identifying the place if you searched by name, like a specific ZIP code or city) and various flags for filters. In our example, we’re willing to scrape all the listings in New York State, so the regionSelection field has the regionId = 42. By changing the desired state, this value will change.
There’s also a parameter called wants, which tells Zillow what data to return. By tweaking wants, you can ask for different bits of info – typically, you’ll request the list of results (homes) and perhaps a summary count. A request might look like this (in a simplified form)
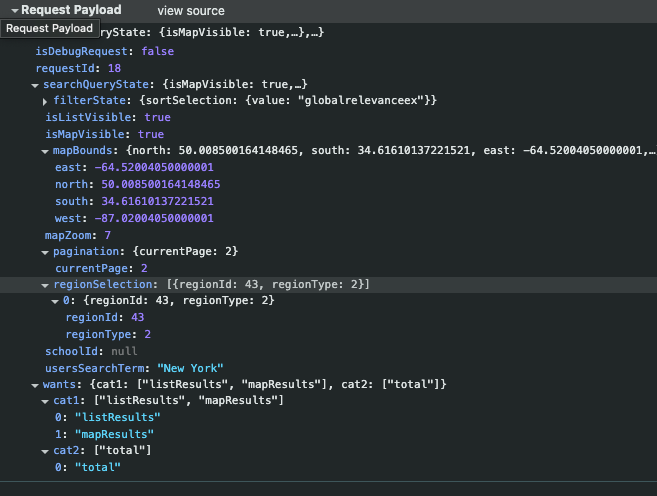
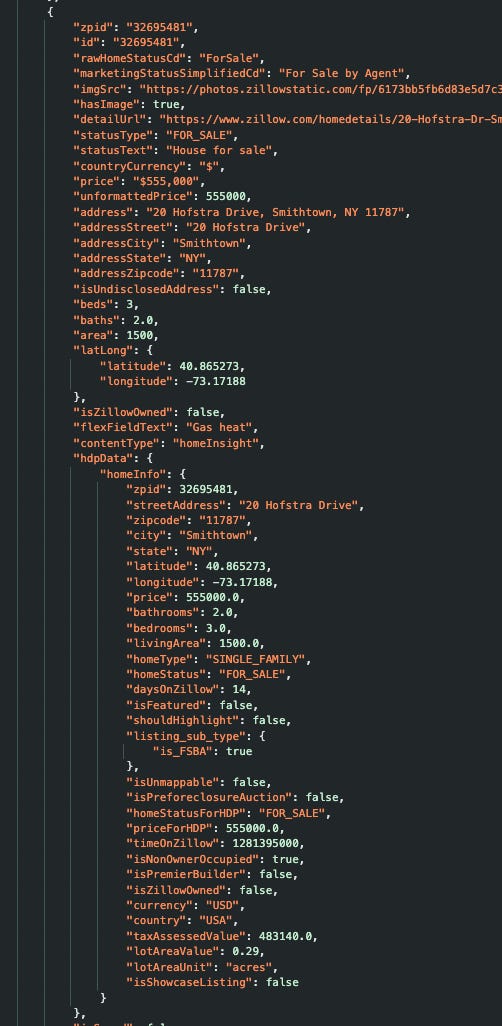
Here we’re asking for all the results (cat1) in the given map box, as well as the total count of results (cat2). The response is a big JSON structure containing the listings that match the query. Each listing in the JSON includes data like a unique Zillow Property ID (“zpid”), the price, address, coordinates (latitude/longitude), and other details like number of beds and baths. Essentially, it’s the same info you see on the website, but in machine-friendly form. By replicating these internal API calls, we can retrieve Zillow data programmatically.
Limitations of Data Visualization
Before we start coding, it’s essential to understand Zillow’s built-in limitations on search results. If you use the website typically, Zillow will not show you endless pages of homes even if thousands match your query. Zillow caps the results at 20 pages, with 40-41 listings per page, so any search on the site will show at most about 820 properties.
If there are more homes than that in the area or category you searched, Zillow stops paginating and typically will prompt you to zoom in or apply more filters. This limit makes sense for user experience – no one wants to click through hundreds of pages – but it poses a challenge for scraping. If you naively query the whole state of New York in one go, for example, you might get “20 pages of 41 homes” and miss the rest, even though tens of thousands may be for sale.
This is a common scenario in real estate websites, where we have thousands of requests that will never be seen by a human. That’s why these platforms invite you to zoom into the map or apply more filters to the selection. For this reason, you need to split larger areas into smaller ones, so that the number of results never exceeds the limit of the platform. One approach, my favourite in these cases, is the tiling of the surface, which I described in this post.

The scripts mentioned in this article are in the GitHub repository's folder 81.ZILLOW, which is available only to paying readers of The Web Scraping Club.
If you’re one of them and cannot access it, please use the following form to request access.
Workaround Using Square Tiling
How do we bypass the 20-page/820-listing limit? The trick is to divide and conquer. Instead of treating a large region as one big search, we break it into smaller geographic chunks (squares or tiles), scrape each chunk separately, and then combine the results. This approach is often referred to as square tiling or map tiling. The idea is simple: if Zillow gives up to ~800 results per area, we make sure no area we query has more than that many listings by making the area small enough.
In practice, you might start with a certain bounding box (say, the whole state of New York). If the API indicates that the area has hit the 20-page max, you split that box into four quarters (imagine dividing the map into four smaller rectangles of equal size) and query each of those. If any of those quarters still return 20 pages of results, you split them further, and so on. You recursively zoom in until each sub-area yields less than the maximum number of pages. At that point, you know you’re getting all the listings in each sub-area, because if there were more, Zillow would have shown more pages. Finally, you aggregate the listings from all these sub-areas to reconstruct the full dataset for the original large region.
For example, suppose New York State as a whole shows 20 pages of results (meaning there are well over 800 homes). We break NY into, say, four quadrants: perhaps Northeast NY, Northwest NY, Southeast NY, Southwest NY. We query each quadrant’s bounding box separately via the API. Maybe the NYC metro quadrant is still maxed out (lots of homes there), so we split that quadrant again into smaller boxes (maybe by boroughs or smaller regions). Upstate NY quadrants might be fine on their own if they have fewer listings. By iteratively doing this, we end up covering the entire state with multiple API calls, each yielding a manageable chunk of data. This tile-based scraping ensures we don’t miss properties that would be hidden behind the pagination limit.
One advantage of this approach is efficiency – we only subdivide where necessary. Sparse rural areas won’t need many splits (they might not hit the page limit at all), whereas dense cities will be divided more times. The result is a clever balance: we avoid creating unnecessary requests on tiny areas if we don’t need to, but we zoom in deeply where the data is dense. For our purposes, it means no matter how large the search region or how many properties, we can get all the data by slicing the map into squares until the limitation is no longer an issue.
Code example
The file zillow_with_grids.py inside the GitHub repository is quite self-explanatory, but let’s give a brief read of it.
