
The Lab #52: Scraping with LLMs and ScrapeGraphAi - part 1
Are LLMs the Holy Graal for web scraping?

There’s no need to say that LLMs are still on the news in these months, thanks to the daily feed of new startups, models, and improvements that we’re exposed to.
There’s a lot of interest in AI in general and if even my 70-year-old mother, the less tech-savvy person I know, talks to me about ChatGPT, I think that we peaked the hype cycle.
It’s clear that we are still in the early stages of this technology and expectations may not be met for some specific tasks (spoiler: I’m talking about web scraping).
Are general purposes LLMs a response to web scraping?
I am not a Luddite, this is for sure. On the contrary, I would define myself as a tech enthusiast, ready to try every new innovation. I tried to understand a bit the world of cryptos, I traded Bitcoin and other alt-coins in the past, created and traded NFTs, and, of course, I’m using ChatGPT almost daily.
I consider ChatGPT the intern I cannot afford to pay, assigning to it some low-risk/low-reward tasks that I usually don’t have time to do regularly.
If you follow me on Linkedin, you should have seen recently that I daily post about my older and the newest posts on The Web Scraping Club, with a tone of voice that is not like the one I usually use (have I ever used the word folks in 200+ issues of this newsletter?).

The reason is quite simple: showing up on Linkedin every day with a new article helps grow (a bit) the audience of this newsletter, organically reaching new potential readers. This also applies to Facebook (yes, there’s The Web Scraping Club Facebook page), X, and Reddit.
Summarizing the article to fit the format and size of every social media is not rocket science, but it takes time I don’t have. It’s a low-value activity but, at the same time, it must be done.
So, starting two weeks ago, I created an automation with Make.com that scrapes my blog content and publishes it on all social media. It’s an easy task and I don’t expect ChatGPT to make huge mistakes by summarizing it, and even if the content is not perfect, there’s not a great impact on my side, so I’m happy to use GPTs to automate this task.
But is this process suitable for tasks where errors could have a larger impact like web scraping?
As always, it depends on the ratio between risks and returns. How many times do we expect these errors to happen and what implications do they have?
The Uncertainty around LLM responses
Let’s be clear: the wet dream for every web scraper is a tool that can scrape any website, with no maintenance even when its code changes over time.

However, LLMs have some critical aspects that cannot be underestimated when deploying a solution.
I’ve recently read “The Pain Points of building a copilot” article by Austin Henley and I discovered that my point of view is somehow confirmed by AI experts.
Prompt engineering is time consuming and requires considerable trial and error. Additionally, it is tedious to parse the output and requires balancing more context with using fewer tokens. Another problem is managing the prompts, prompt templates, what worked, what didn't work, and why changes to them were made. As one developer said, "it's more of an art than a science".
Are we sure that finding the correct prompt for our task is more convenient in terms of time and money compared to a more traditional approach?
Testing is fundamental to software development but arduous when LLMs are involved. Every test is a flaky test. Some developers run unit tests multiple tests and look for consensus. Others try to build large benchmarks that can be used to measure how prompts or models impact the results, but it requires expertise and is expensive. When is it "good enough"?
And I would add: are we sure that a prompt that works today, will work in a week or a month?
This second point in particular is key when integrating an LLM in an automated process, where it’s impossible to have human supervision on the results.
Let’s think about web scraping: this should mean that we should check the results for every scraped page, which I think is quite impossible.
For these reasons, instead of using general-purpose LLMs, companies like Zyte and Nimble are integrating their AI models in scraping solutions.
From the outside, I think the difference between the two approaches is the following: while LLMs guess the next word to write in the results according to their training, scraping-specific models are more focused on finding where the information is in the HTML and then using it in the response.
Scraping with LLMs using ScrapeGraphAI
My concerns about web scraping with LLMs don’t mean that this technology is completely unuseful, but we should be aware of where it could be a good fit and where it’s not.
During the past weeks, a new Python library came out of the blue with a web scraping solution using different LLM models, and it has also gained popularity on Hacker News. I’m talking about ScrapeGraphAi. I’ve seen a huge amount of content about this library and it seemed a good way for a non-AI expert like me to test out this world. Having discovered that the main contributors are young Italians, the success of this repository, with more than 9k stars on GitHub makes me even happier.
Choosing the right model
As mentioned in the documentation, you can use different models for your scraping operations, both locally and hosted elsewhere. I’m not so into AI to understand which model is better according to the website I want to scrape, but I tried hosting Llama on my 4-year-old MacBook Pro and could not complete any scraping. So I decided to use GPT models.
Given the restrictions on the number of tokens I could spend, I needed to use the GPT-3.5-turbo for my tests.

So the configuration of my Graph, which is the main entity of this library, will be the following:
graph_config = {
"llm": {
"api_key": "MY_OPENAI_KEY",
"model": "gpt-3.5-turbo",
},
"verbose": True,
"headless": False
}As always, if you want to have a look at the code, you can access the GitHub repository, available for paying readers. You can find this example inside the folder 52.SCRAPEGRAPHAI
If you’re one of them but don’t have access to it, please write me at pier@thewebscraping.club to get it.
Selecting a Graph
Graphs are scraping pipelines aimed at solving specific tasks. They are composed by nodes which can be configured individually to address different aspects of the task (fetching data, extracting information, etc.).
There are several types of graphs available in the library, each with its own purpose and functionality. The most common ones are:
SmartScraperGraph: one-page scraper that requires a user-defined prompt and a URL (or local file) to extract information using LLM.
SmartScraperMultiGraph: multi-page scraper that requires a user-defined prompt and a list of URLs (or local files) to extract information using LLM. It is built on top of SmartScraperGraph.
SearchGraph: multi-page scraper that only requires a user-defined prompt to extract information from a search engine using LLM. It is built on top of SmartScraperGraph.
SpeechGraph: text-to-speech pipeline that generates an answer as well as a requested audio file. It is built on top of SmartScraperGraph and requires a user-defined prompt and a URL (or local file).
ScriptCreatorGraph: script generator that creates a Python script to scrape a website using the specified library (e.g. BeautifulSoup). It requires a user-defined prompt and a URL (or local file).
For these tests, we’ll see how to use SmartScraperGraph since we’re interested in scraping results from single pages of different websites.
First try: Scraping an E-commerce website
Let’s see how ChatGPT performs when the accuracy is key, especially for numeric fields like the price of a product.
We’ll scrape the Net-A-Porter website, in particular the first page of the Women’s Clothing category.
The core of the Graph is the following code
graph_config = {
"llm": {
"api_key": "MY-API-KEY",
"model": "gpt-3.5-turbo",
},
"verbose": True,
"headless": False
}
smart_scraper_graph = SmartScraperGraph(
prompt="This page contains a list of fashion products. Per each product, scrape the following fields for each product: product code, full price, price, currency, itemurl, imageurl, product category, product subcategory, product name. The product code is a numeric string that can be found in the item url. Full price is the price of the product without discounts, if any. If there is no discount, use the only price shown. Price is the product price after discounts: if there's no discount, use the only product price available. Currency is the ISO code of the currency used to display prices on this page. Imageurl is the URL of the image of the product, used as a thumbnail on this page.",
# also accepts a string with the already downloaded HTML code
source="https://www.net-a-porter.com/en-it/shop/clothing",
config=graph_config
)but if you want the full code, you can find it in the GitHub Repository in the file scrapegraph_nap_test.py.
The results, although not complete since the program is returning only four products, are plausible and in some cases, like the product categorization, pretty good, but there’s something strange in the prices. Let’s compare the results with the real website.
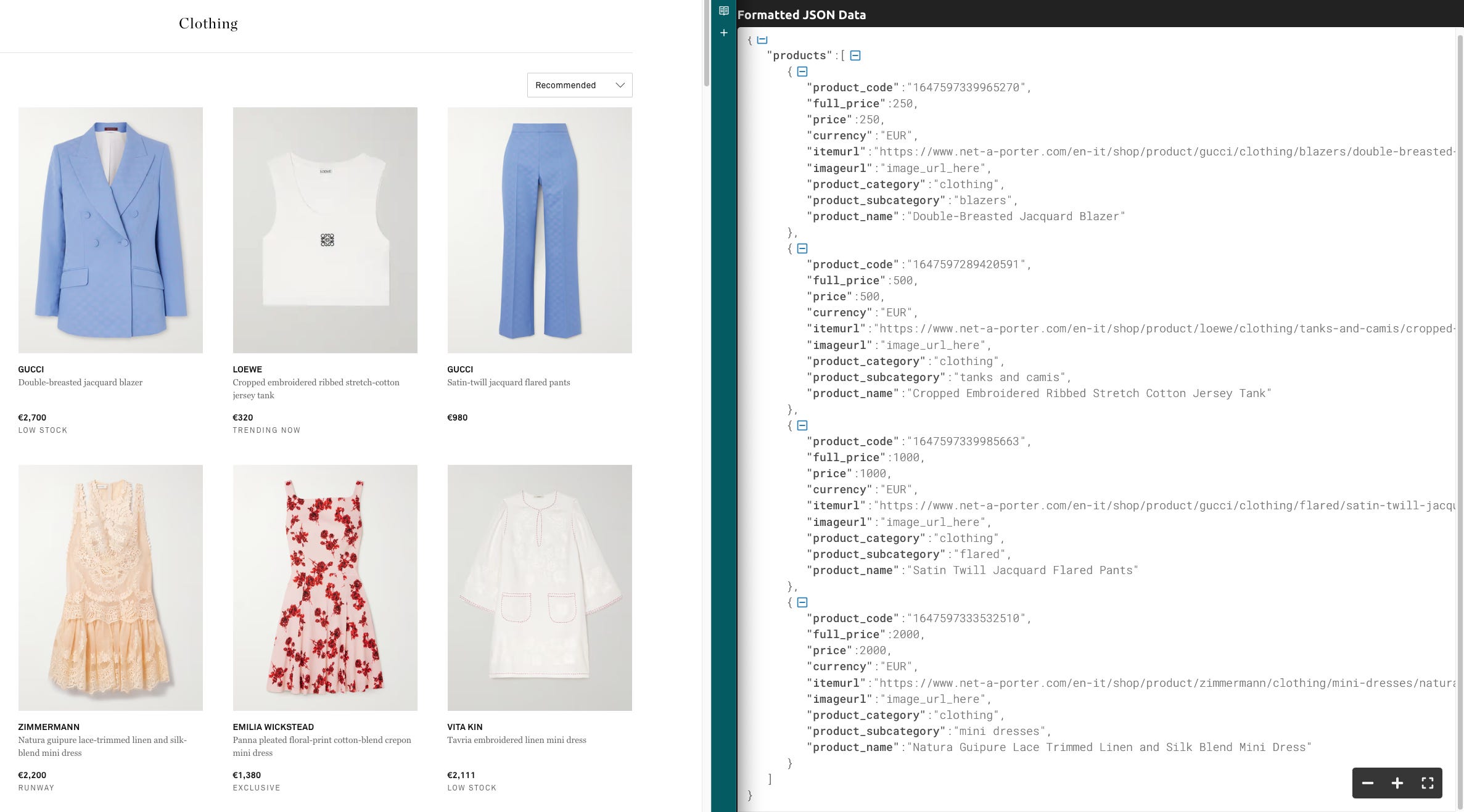
There’s not a single price that is correct! ChatGPT, when creating the response, is guessing what could be the next word to write but seems not to care about the price, which is already written in the code and needs only to be exposed.
Even worse, running the same command the day after, these were the results:

It used the filters by brand on the left of the website’s page and put some random prices and descriptions.
So, ChatGPT not only returned wrong results, but these were inconsistently wrong from day to day, using the same starting conditions. Any software behaving like it’s impossible to debug and can’t be considered reliable.
But let’s try to consider the positive aspects of this test, like the correct product classification (at least in the first case), and see another use case, always in the fashion e-commerce space, where results may be better.
Second try: extracting product information
This second experiment can be found in the repository in the file scrapegraph_nap_single_product_test.py.
In this case, we’re targeting a single-page product and trying to extract some qualitative information.

The graph configuration changes to send a new prompt, where I describe field by field what I desire in output.
smart_scraper_graph = SmartScraperGraph(
prompt="This page contains fashion product. I want in output the following fields: product code, gender, product category, product subcategory, brand, product color, description, sizes available, material composition. The product code is a numerical code that can be found in the URL. Gender information is Women, Men, or Kids, depending if the product is suitable for Women, Men or Kids. Product category could be Clothing, Shoes, Accessories depending from the product type. Product Subcategory must be coherent with product category and deducted from the product description. Brand is the fashion brand that produced this article. Product color is the color of the item and must be deducted from the product description. The product description is under Editor notes section of the page, Sizes available are the clothing sizes that are listed on this page, Material Composition are the material and technique used to produce the item ",
# also accepts a string with the already downloaded HTML code
source="https://www.net-a-porter.com/en-it/shop/product/gucci/clothing/blazers/double-breasted-jacquard-blazer/1647597339965270",
config=graph_config
)