
The importance of scraping inventory levels data in the retail industry
Understanding the business logic behind inventory levels on retail e-commerce websites

This article has been in the draft section for months but, thanks to Alex Lokhov recent posts about inventory levels, I’ve decided to publish it, adding my two cents to the discussion.
During my career as a professional web scraper, mainly focused on the fashion industry, I saw different real-world cases of inventory levels exposed inside websites, so I wanted to share my findings with you.
Why scraping inventory levels in retail
Before understanding the importance of scraping inventory levels, we need to understand how retailers usually work. Let’s use a well-known sportswear brand as an example for a better understanding, but we can translate the logic to other industries.
Let’s speak about Nike: the brand is sold in sports stores like Footlocker or in its direct channels, which means its own stores and e-commerce website.
The revenues per channel type, according to the latest financials statement, are split almost equally between wholesalers (Footlockers and any other third-party seller, with 56% of the revenues) and direct channels (44% of the revenues), as we can see from the Statista report.

One of the most important and common use cases for scraping inventory levels is to predict revenues, just like Alex Lokhov described in this post.

Nike is a listed company and a revenue predictor algorithm would be greatly appreciated and valuable for its investors.
The reality is that most of Nike’s revenues come from wholesalers, so even if the Nike website contained granular information about inventory levels, we wouldn’t have a detailed picture of the revenues but only a partial (and probably less valuable) one.
But let’s focus now on the direct channels: unluckily we don’t have the split of the revenues between the e-commerce and the physical stores. Let’s suppose that the majority of the revenues (90%) come from the physical stores while the remaining 10% come from the e-commerce website.
In this case, even if there’s the exact amount of the inventory hidden somewhere in the website, if we build a revenue forecasting model on top of it, we would predict the approx 4% of the total revenues of the company. This could be a weak signal to determine the health of the brand but not a great indicator of the total revenues of the company.
If, instead, there’s the chance to get also the exact stock level from each physical store of Nike, this could be much more interesting for investors, since we could cover the whole 46% of the revenues.
But investors are not the only people interested in this kind of data. Let’s say you’re working for a Nike competitor, with the same distribution channels.
It could be interesting for you to know which shoe model sells most on a wholesaler's website. Or how’s the Nike e-commerce compared to yours. Or, again, if a physical store near to yours is performing better.
So also the competitive intelligence for brands is a great use case for the inventory-level scraping.
But this is too good to be true: in fact, unlike pricing data, which is needed to sell online, the availability of the inventory levels data and its granularity depends on the website tech architecture.
In the case of Nike, just to continue the example, from a rapid look at the website you can see only if a product is available or not on a website and in a store, so there are very few details you can rely on.
In some other cases, instead, the data not only is available but also shown to the visitors.

Understanding more of the company in terms of revenue split and then investigating the data we could fetch from the website is the starting point which makes us understand what kind of product we can build and its potential target audience. After this study, we have clearer ideas but we only scratched the surface of the project. Before coding, we need to understand more about the logistics behind the company’s website and the granularity level of details we could get.
Understanding the logistics behind a website
Let’s say we studied a target website and discovered that there’s a chance to get the exact stock amount available for each item on sale. This is great, but it’s not over. Typically websites sell in multiple countries and if we’re interested in understanding their performance on a global scale, we cannot simply sum the numbers per each country. Doing so, we’ll probably incur in counting multiple times the same items: depending on case to case, e-commerces could have dedicated warehouses that serve multiple countries.
Let’s see a practical example: the Stone Island website sells mainly in Europe and then in the USA, Canada, Korea, and Japan.

In order to understand how the distribution works behind the website, one trick could be to select a few items and, only for them, scrape their inventory levels for every country.
Let’s see what happens if we scrape inventory worldwide for these yellow shoes.

Here are the results.

As we can see, probably there’s a warehouse serving the whole of Europe, then one for the USA and Canada, one for Japan, and one for Korea. This means that we need to scrape only 4 countries instead of all the ones available on the website.
But where do these shoes come from? From a central warehouse or from the inventories of the physical stores that will send the item to the customer?
That’s an interesting question and with a single snapshot it’s hard to say, but we can understand more using the function “book in store”, available after being logged in.
This function exposes an open API where, given an item and a size in input, it returns the availability in each store which seems to be the exact number of items inside the inventory.
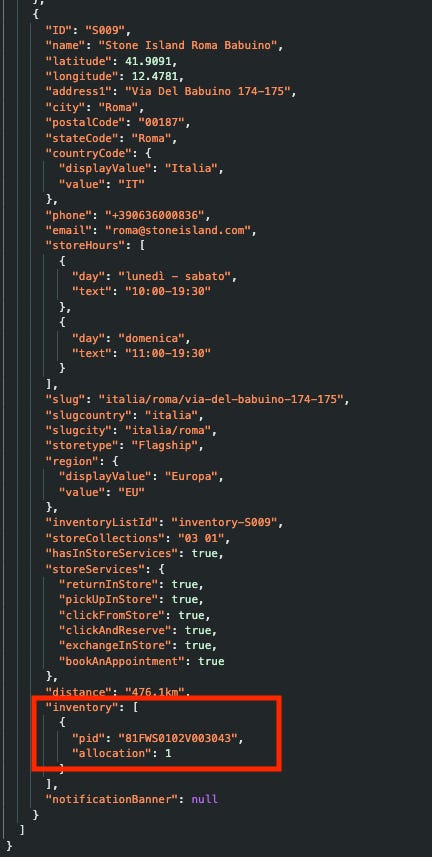
The fun fact is that by summing up all the store inventory for all the sizes and stores in Europe for this pair of shoes available today we have exactly 32, which is the inventory we measured two days ago on a product-level detail, without querying the stores.
This is not true for other items, so probably the e-commerce has a different warehouse, which is labeled using the value contained in the field “inventoryListId” in the ERP software.
If you want to have some fun and play with this inventory data, you can find it on the Databoutique.com data marketplace.
Handling the data granularity
The Stone Island example shows the best situation we could face: we get the punctual inventory level for every single item sold on the website, both in the e-commerce warehouses and in stores.
The situation is more heterogeneous across different websites:
some of them don’t display any data, so not useful for this case study
some websites show availability only when a few items are left. While this is not useful for estimating the revenues, can have some value for competitive intelligence, to check when competitors run out of stock and how fast this happens.
the same can be said for websites that use a discrete set of values: instead of showing a number they say something like “Many items left”, “Few items left”, or “Only 3/2/1/ items left”.
some other websites share the exact number, like Stone Island
The reason why this happens is still unknown to me: while I understand that in the IT departments of these brands, there’s the need to create and maintain as less APIs as possible, and make them more complete with more data, sharing this level of details openly and publicly can be an advantage for their competitors (and bring nothing to the brand itself, that could hide this info from the public).
Where to find inventory data on e-commerce websites
Given the differences between the tech stack of e-commerce websites, there’s no silver bullet to find this data, but I can share some tricks I often use.
Generally speaking, inventory levels can be found in the API response used for showing data about a product, so mainly in the so-called Product Detail Page (PDP).
If there’s no internal API call when loading this page, check if the website offers the chance to pick up in-store the item: by doing so, selecting an item and a delivery store, the website is almost forced to query the backend systems to know the real-time item availability. If you’re lucky, the response shows a detailed result, at least for the store.
The same can be done by adding the item to the cart: there could be an API that checks the item availability before letting you do so. In this case, please keep in mind that adding items to the cart programmatically could damage the business of the website, so don’t include the “add to cart” API in your scraper.
Last but not least, sometimes this data can be found inside the HTML of the page, typically in a JSON structure loaded by the framework, with names like inventory, stock, ATS, availability and similar.