
Web Scraping Idealista and Bypass Idealista Blockers
Bypassing Datadome for getting real estate data

In today’s article, together with our partner ScraperAPI, we understand how to scrape real estate data from Idealista, bypassing Datadome protection.
Idealista stands as a leading online real estate marketplace in Southern Europe. With millions of listings encompassing homes, rooms, and apartments, it's an invaluable resource for businesses and individuals seeking insights into the real estate market.
Scraping Idealista opens up opportunities to extract this data, enabling market research, lead generation, competitor analysis, and a wealth of other data-driven applications.
However, like many websites, it uses DataDome to prevent automated scraping. This guide will walk you through the challenges, equip you with the right tools, and provide a step-by-step approach to extracting data from Idealista effectively and ethically.
Prerequisites
Before we begin, let's ensure we have the necessary tools:
Python: If you don't already have Python installed, download the latest version and install it on your system.
Required Libraries: You'll need to install several Python libraries. Open your terminal or command prompt and run the following commands:
pip install requests beautifulsoup4 lxml selenium selenium-wire undetected-chromedriverScraperAPI Account: To bypass Idealista's bot protection, you'll need a ScraperAPI account. You can follow this link to sign up to get 5000 scraping credits for free.
Chrome Driver: Download ChromeDriver. Make sure to select the version that matches your installed Chrome browser.
Understanding the Challenge: Bypassing DataDome
Idealista utilizes a robust bot protection system called DataDome, a cybersecurity company specializing in online fraud prevention and bot management. They offer a range of tools and services designed to shield websites, mobile applications, and APIs from various automated threats.
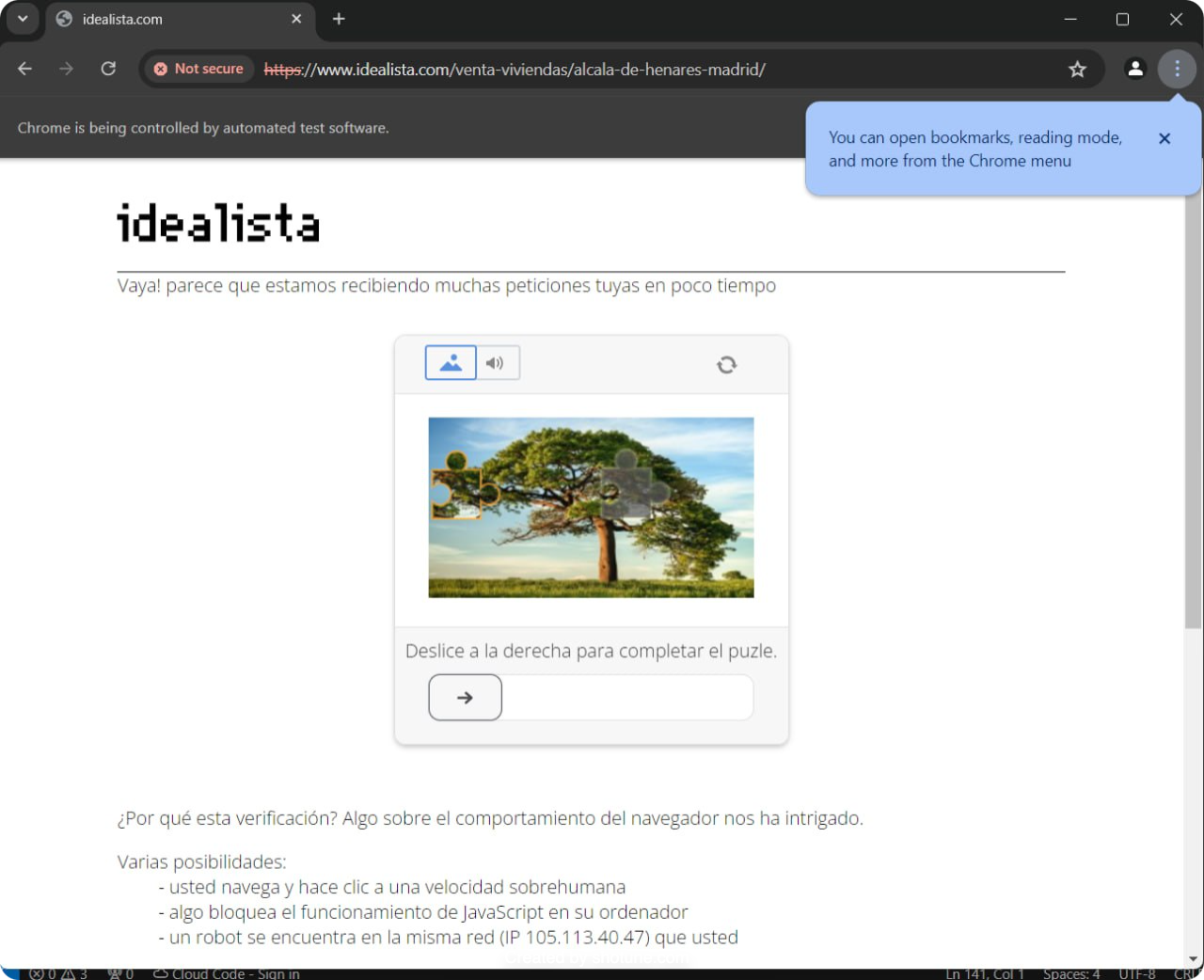
How Does DataDome Detect Web Scrapers?
DataDome employs advanced machine learning algorithms to analyze request fingerprints and behavioral signals. This analysis helps detect and block bot attacks in real-time, ensuring that only legitimate users can access the website's content.
A central component of their detection strategy is the trust score assigned to each visitor. This trust score indicates the likelihood that a visitor is a human rather than an automated bot.
DataDome calculates the trust score based on various behavioral and characteristic factors of the visitor. Depending on this score, DataDome may allow the visitor access, block them, or present a CAPTCHA challenge. Several key techniques contribute to this scoring process:
Browser Fingerprinting: This involves collecting detailed information about the visitor's browser, such as type, version, screen resolution, and IP address. If a particular fingerprint is seen frequently in a short period, it may indicate bot activity.
Behavioral Data: Humans and bots interact with websites in fundamentally different ways. DataDome analyzes subtle mouse movements, scrolling patterns, typing speed, and form-filling behaviors to spot unnatural precision indicative of bots.
IP Monitoring & Session Tracking: DataDome analyzes IP addresses to determine the visitor's location, ISP, and reputation. Multiple rapid requests from the same IP or known bot-associated IPs and unusually long or repetitive sessions can indicate automation.
HTTP Header Analysis: This examines metadata such as browser type, language, and referring website for discrepancies. Suspicious headers can reveal bots attempting to disguise themselves.
CAPTCHA Challenges: CAPTCHA challenges are tests presented to users to verify if they are human, such as selecting specific images. These challenges add a layer of security to distinguish between legitimate users and automated scripts.
By combining these techniques, DataDome can detect and block web scrapers, ensuring that only genuine users access the website's content.
Why Basic Scraping Often Fails
Automated browsers, such as Selenium, Puppeteer, and Playwright, often struggle to bypass DataDome's security measures due to their identifiable bot-like characteristics.
This is because they have distinct fingerprints compared to standard web browsers. Simply using tools like Selenium, Puppeteer, or Playwright out-of-the-box won't cut it.
These tools often inject flags or modify browser properties in ways that scream "automation!" to security systems. Let's illustrate this with a common scenario using a simple Selenium script.
Locating the Data
Our goal is to extract specific information about each property listing from Idealista. We can use our web browser's developer tools to understand the website's structure and identify the HTML elements we need to target.
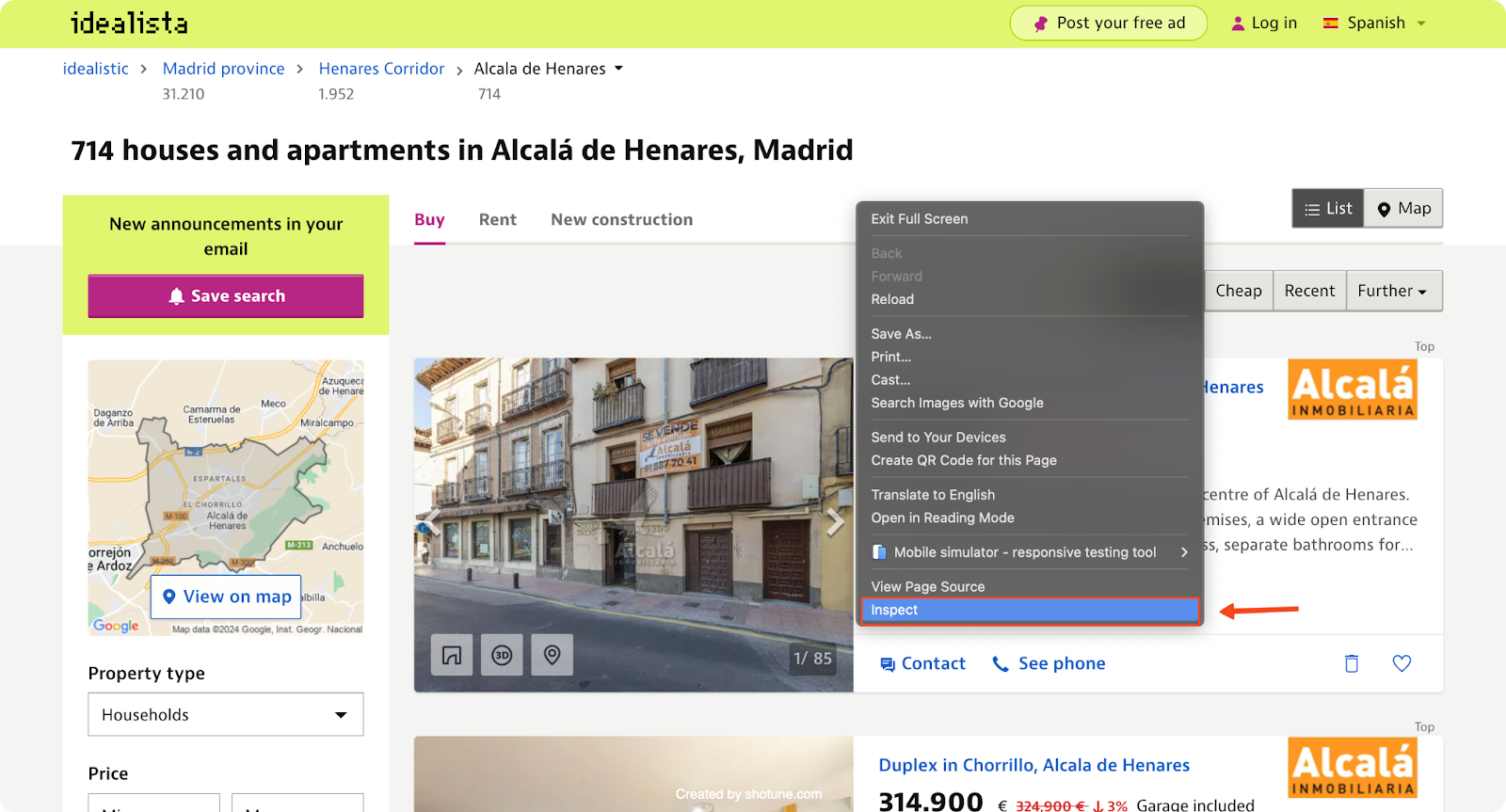
For this article, we'll focus on scraping property listings from Alcalá de Henares, Madrid, using this URL:
https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/
We want to extract the following data points from each listing:
Title
Price
Bedrooms
Area
Description
Image URL
By inspecting the HTML source code, we can identify the CSS selectors for each data point. CSS selectors are patterns used to select elements in the HTML document.

For example, we find that each property listing is contained within an <article> tag with the class item. Within each item, the title is within an <a> tag with the class “item-link”, the price is inside a <span> tag with the class “item-price”, and so on.
Step 1: Setting Up Selenium with ChromeDriver
First, we need to set up Selenium to use ChromeDriver. We start by configuring the chrome_options and initializing the ChromeDriver.
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
from datetime import datetime
import json
def listings(url):
chrome_options = Options()
chrome_options.add_argument("--headless")
s = Service("Replace with your path to ChromeDriver")
driver = webdriver.Chrome(service=s, chrome_options=chrome_options)This code imports the necessary modules, including seleniumwire for advanced browser interactions and BeautifulSoup for HTML parsing. We define a function listings(url) where we configure Chrome to run in headless mode by adding the --headless argument to chrome_options. We then initialize the ChromeDriver with the specified service path.
Step 2: Loading the Target URL
Next, we load the target URL and wait for the page to load fully.
driver.get(url)
time.sleep(8) # Adjust based on website's load timeHere, the driver.get(url) command instructs the browser to navigate to the specified URL. We use time.sleep(8) to pause the script for 8 seconds, allowing enough time for the webpage to load completely. This wait time can be adjusted based on the website's load time.
Step 3: Parsing the Page Content
After the page loads, we parse the content using BeautifulSoup:
soup = BeautifulSoup(driver.page_source, "lxml")
driver.quit()Here, we use driver.page_source to get the HTML content of the loaded page and parse it with BeautifulSoup using the lxml parser. Finally, we quit the browser instance with driver.quit() to clean up resources.
Step 4: Extracting Data from the Parsed HTML
Next, we extract relevant data from the parsed HTML.
house_listings = soup.find_all("article", class_="item")
extracted_data = []
for listing in house_listings:
description_elem = listing.find("div", class_="item-description")
description_text = description_elem.get_text(strip=True) if description_elem else "nil"
item_details = listing.find_all("span", class_="item-detail")
bedrooms = item_details[0].get_text(strip=True) if len(item_details) > 0 else "nil"
area = item_details[1].get_text(strip=True) if len(item_details) > 1 else "nil"
image_urls = [img["src"] for img in listing.find_all("img") if img.get("src")]
first_image_url = image_urls[0] if image_urls else "nil"
listing_info = {
"Title": listing.find("a", class_="item-link").get("title", "nil"),
"Price": listing.find("span", class_="item-price").get_text(strip=True),
"Bedrooms": bedrooms,
"Area": area,
"Description": description_text,
"Image URL": first_image_url,
}
extracted_data.append(listing_info)Here, we find all elements matching the "article" tag with the class "item" which represents individual house listings. For each listing, we extract the description, item details (like bedrooms and area), and image URLs. We store these details in a dictionary and append each dictionary to a list extracted_data.
Step 5: Saving the Extracted Data
Finally, we save the extracted data to a JSON file.
current_datetime = datetime.now().strftime("%Y%m%d%H%M%S")
json_filename = f"new_revised_data_{current_datetime}.json"
with open(json_filename, "w", encoding="utf-8") as json_file:
json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)
print(f"Extracted data saved to {json_filename}")
url = "https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/"
idealista_listings = listings(url)Here’s the full code:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
from datetime import datetime
import json
def listings(url):
chrome_options = Options()
chrome_options.add_argument("--headless")
s = Service("Replace with your path to ChromeDriver")
driver = webdriver.Chrome(service=s, chrome_options=chrome_options)
driver.get(url)
time.sleep(8) # Adjust based on website's load time
soup = BeautifulSoup(driver.page_source, "lxml")
driver.quit()
house_listings = soup.find_all("article", class_="item")
extracted_data = []
for listing in house_listings:
description_elem = listing.find("div", class_="item-description")
description_text = description_elem.get_text(strip=True) if description_elem else "nil"
item_details = listing.find_all("span", class_="item-detail")
bedrooms = item_details[0].get_text(strip=True) if len(item_details) > 0 else "nil"
area = item_details[1].get_text(strip=True) if len(item_details) > 1 else "nil"
image_urls = [img["src"] for img in listing.find_all("img") if img.get("src")]
first_image_url = image_urls[0] if image_urls else "nil"
listing_info = {
"Title": listing.find("a", class_="item-link").get("title", "nil"),
"Price": listing.find("span", class_="item-price").get_text(strip=True),
"Bedrooms": bedrooms,
"Area": area,
"Description": description_text,
"Image URL": first_image_url,
}
extracted_data.append(listing_info)
current_datetime = datetime.now().strftime("%Y%m%d%H%M%S")
json_filename = f"new_revised_data_{current_datetime}.json"
with open(json_filename, "w", encoding="utf-8") as json_file:
json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)
print(f"Extracted data saved to {json_filename}")
url = "https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/"
idealista_listings = listings(url)If you run your script at least two times during the course of this tutorial, you may have already noticed this CAPTCHA page:
While this script might seem sufficient, it often triggers Idealista's defenses. Here's why:
By default, headless browsers have unique characteristics that differ from regular browsers. DataDome can detect these discrepancies and identify the browser as automated.
This script directly fetches the target URL without any pauses, mouse movements, or other interactions that a real user would make. This mechanical precision is a clear sign of a bot.
As a result, DataDome will likely detect and block this script, preventing you from consistently accessing the webdata. When blocked, the response might look like this:
<html> <head> <title> idealista.com </title> <style> #cmsg{animation: A 1.5s;}@keyframes A{0%{opacity:0;}99%{opacity:0;}100%{opacity:1;}} </style> </head> <body style="margin:0"> <p id="cmsg"> Please enable JS and disable any ad blocker </p> <script data-cfasync="false"> var dd={'rt':'c','cid':'AHrlqAAAAAMABMHblZJBP9AAaXEoLw==','hsh':'AC81AADC3279CA4C7B968B717FBB30','t':'fe','s':17156,'e':'48fc4614c817656cf52e9b8deff8a80363239faa71fd764953530a0549b1ebff','host':'geo.captcha-delivery.com'} </script> <script data-cfasync="false" src="https://ct.captcha-delivery.com/c.js"> </script> </body></html>How to Bypass DataDome on Idealista with ScraperAPI
As we saw in the previous section, basic scraping techniques often fall short when dealing with sophisticated anti-bot systems like DataDome. Meanwhile, maintaining your own proxy infrastructure and constantly adapting to evolving bot detection techniques can be really time-consuming and resource-intensive.
Services like ScraperAPI provide a simple and reliable way to access data from websites like Idealista, without the need to build and maintain your own scraper. ScraperAPI handles proxy rotation, CAPTCHA bypass, and anti-bot detection, making it an efficient solution for web scraping.
The setup is quick and easy. All you need to do is create a free ScraperAPI account. You’ll receive your API key, which can be accessed from your dashboard.
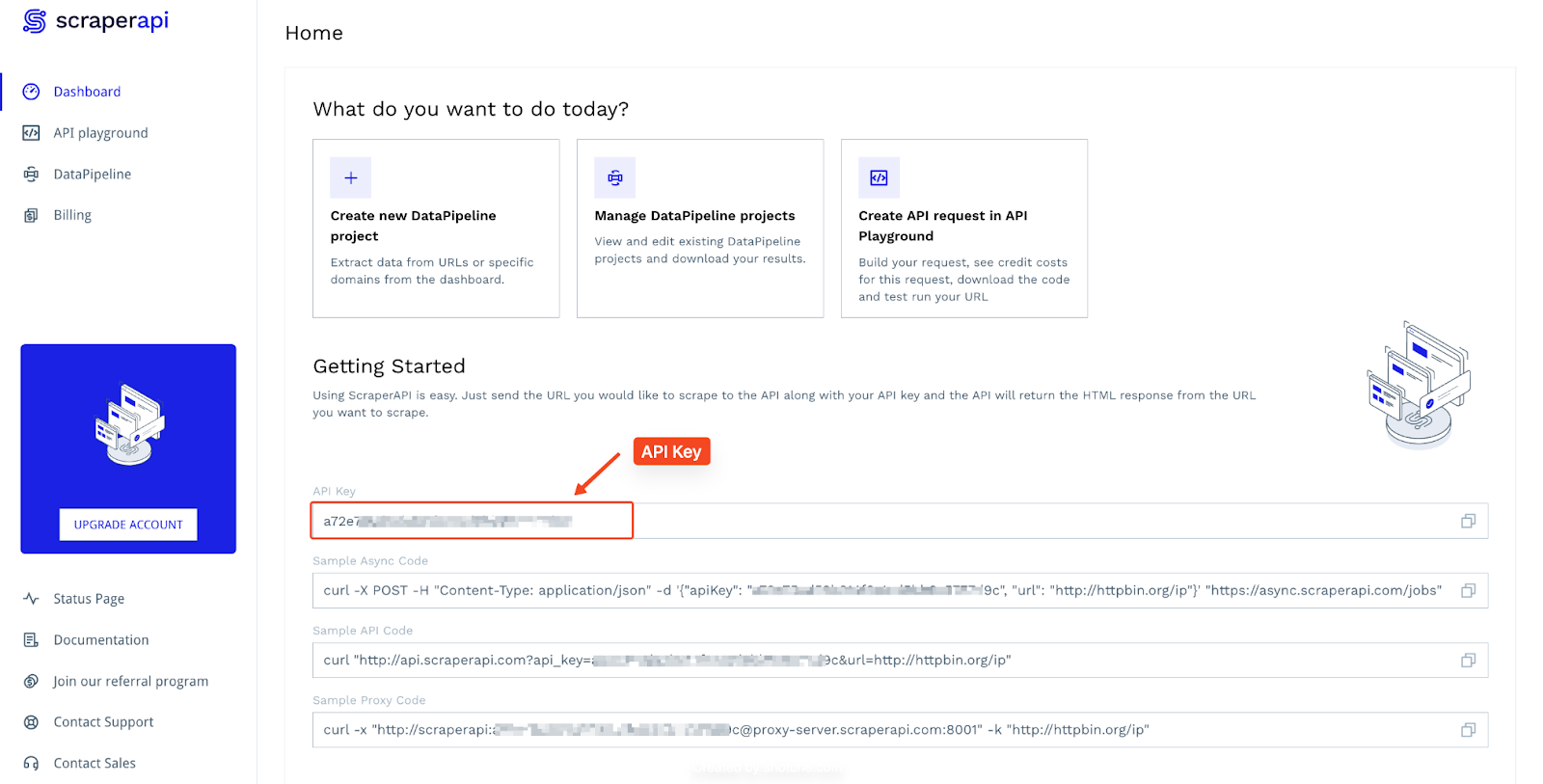
Let's break down how to use ScraperAPI to scrape Idealista effectively:
Step 1: Import Necessary Libraries
First, we'll import the required Python libraries.
import requests
from bs4 import BeautifulSoup
import json
from datetime import datetimeThis code imports the essential libraries: requests for handling HTTP requests, BeautifulSoup for parsing HTML content, json for working with JSON data, and datetime for generating timestamps.
Step 2: Set Up ScraperAPI
Next, we'll provide our ScraperAPI API key and define the target URL we want to scrape.
API_KEY = "API_KEY"
url = "https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/"
payload = {"api_key": API_KEY, "url": url, "render": True}Here, we replace "API_KEY" with your actual key. We then define the URL of the Idealista page we want to scrape
We create a dictionary (payload) containing our API key, target URL, and the render parameter render=True
This last parameter instructs ScraperAPI to render the webpage using a headless browser. This is essential for executing JavaScript and retrieving dynamically loaded content.
Step 3: Make the Request with ScraperAPI
Now, we'll use the requests library to send a GET request to ScraperAPI's server, passing in our payload.
response = requests.get("http://api.scraperapi.com", params=payload)This single line of code sends our scraping request through ScraperAPI.
Step 4: Parse the HTML Response
Assuming the request is successful, ScraperAPI will return the rendered HTML source code of the target webpage. We can then parse this HTML using BeautifulSoup.
soup = BeautifulSoup(response.text, 'lxml')This line creates a BeautifulSoup object soup from the text content of the response we received from ScraperAPI. We’ll parse this object using the lxml parser, known for its speed and efficiency.
Step 5: Extract the Desired Data
With the BeautifulSoup object ready, we can now target and extract the specific data points we need from the Idealista page.
house_listings = soup.find_all("article", class_="item")
extracted_data = []
for listing in house_listings:
description_elem = listing.find("div", class_="item-description")
description_text = description_elem.get_text(strip=True) if description_elem else "nil"
item_details = listing.find_all("span", class_="item-detail")
bedrooms = item_details[0].get_text(strip=True) if len(item_details) > 0 else "nil"
area = item_details[1].get_text(strip=True) if len(item_details) > 1 else "nil"
image_urls = [img['src'] for img in listing.find_all("img") if img.get('src')]
first_image_url = image_urls[0] if image_urls else "nil"
listing_info = {
'Title': listing.find("a", class_="item-link").get("title", "nil"),
'Price': listing.find("span", class_="item-price").get_text(strip=True),
'Bedrooms': bedrooms,
'Area': area,
'Description': description_text,
'Image URL': first_image_url,
}
extracted_data.append(listing_info)We first use soup.find_all() to find all the <article> tags with the class "item" as these contain the individual property listings. Then, for each listing, we extract:
The description text
The number of bedrooms and area
The first image's URL
Then, we create a dictionary listing_info containing all the extracted data points for the current listing and append it to our extracted_data list.
Step 6: Save the Data
Finally, we save the extracted data to a JSON file.
current_datetime = datetime.now().strftime("%Y%m%d%H%M")
json_filename = f"Idealista_results_data_{current_datetime}.json"
with open(json_filename, "w", encoding="utf-8") as json_file:
json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)
print(f"Extracted data saved to {json_filename}")We generate a timestamped filename for the JSON file to avoid overwriting existing files. We then open the file in write mode and use json.dump to write the extracted data into the file in a formatted manner. The script concludes by printing a confirmation message that the data has been saved successfully.
Full Code and Results
Below is the full code for scraping Idealista using ScraperAPI:
import requests
from bs4 import BeautifulSoup
import json
from datetime import datetime
API_KEY = "API_KEY"
url = "https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/"
payload = {"api_key": API_KEY, "url": url, "render": True }
response = requests.get("http://api.scraperapi.com", params=payload)
soup = BeautifulSoup(response.text, 'lxml')
house_listings = soup.find_all("article", class_="item")
extracted_data = []
for listing in house_listings:
description_elem = listing.find("div", class_="item-description")
description_text = description_elem.get_text(strip=True) if description_elem else "nil"
item_details = listing.find_all("span", class_="item-detail")
bedrooms = item_details[0].get_text(strip=True) if len(item_details) > 0 else "nil"
area = item_details[1].get_text(strip=True) if len(item_details) > 1 else "nil"
image_urls = [img['src'] for img in listing.find_all("img") if img.get('src')]
first_image_url = image_urls[0] if image_urls else "nil"
listing_info = {
'Title': listing.find("a", class_="item-link").get("title", "nil"),
'Price': listing.find("span", class_="item-price").get_text(strip=True),
'Bedrooms': bedrooms,
'Area': area,
'Description': description_text,
'Image URL': first_image_url,
}
extracted_data.append(listing_info)
# Save the extracted data to a JSON file
current_datetime = datetime.now().strftime("%Y%m%d%H%M")
json_filename = f"Idealista_results_data_{current_datetime}.json"
with open(json_filename, "w", encoding="utf-8") as json_file:
json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)
print(f"Extracted data saved to {json_filename}")Output:
[
{
"Title": "Chalet en Casco Histórico, Alcalá de Henares",
"Price": "579.900€",
"Bedrooms": "4 hab.",
"Area": "245 m²",
"Description": "Alcalá Inmobiliaria comercializa la venta de este Edificio en el centro de Alcalá de Henares. El edificio cuenta con un local de 74 m2 completamente equipado, entrada amplia diáfana y pasillo con estancias separadas por cristal, baños independientes para hombre y mujer, tomas de agua, luz y tv y suelos de tarima. Loc",
"Image URL": "https://img4.idealista.com/blur/WEB_LISTING-M/0/id.pro.es.image.master/9b/0a/01/1185220494.jpg"
},
{
"Title": "Dúplex en Chorrillo, Alcalá de Henares",
"Price": "314.900€",
"Bedrooms": "3 hab.",
"Area": "178 m²",
"Description": "Alcalá inmobiliaria presenta este maravilloso ático-dúplex en una de las mejores zonas de Alcalá de Henares. Este inmueble se ubica en la sexta planta de un edificio construido en el año 2008, lo cual garantiza una estructura sólida y moderna, muchísima luz y unas vistas espectaculares.\nLa planta baja se distribuye d",
"Image URL": "https://img4.idealista.com/blur/WEB_LISTING-M/0/id.pro.es.image.master/af/00/9f/1205367419.jpg"
},
{
"Title": "Chalet en Chorrillo, Alcalá de Henares",
"Price": "509.990€",
"Bedrooms": "5 hab.",
"Area": "197 m²",
"Description": "Alcalá inmobiliaria presenta espectacular chalet exclusivo en la urbanización El Plantío de Alcalá con 2 piscinas comunitarias y amplias zonas comunes con pista de tenis, a escasos 15 minutos andando del casco histórico, 5 minutos de la estación de RENFE y de todos los servicios públicos y privados. \nDistribuido en 3",
"Image URL": "https://img4.idealista.com/blur/WEB_LISTING-M/0/id.pro.es.image.master/87/a6/2f/1230157905.jpg"
}, more data …
]
Wrapping Up
Congratulations, you just scraped Idealista! At this point, you are now equipt to:
Extract valuable real estate data from Idealista, a popular Spanish real estate platform
Understand why simple web scraping approaches often fall short due to sophisticated anti-bot measures like DataDome
Overcome these challenges using ScraperAPI’s advanced anti-bot bypassing
Also worth mentioning, you don’t need to rely on headless browsers anymore, as ScraperAPI handles rendering for you, reducing development time and complexity.
If you would like to learn more about Web Scraping, then be sure to check out the ScraperAPI learning hub!
 | A guest post by
|
If you want to do scraping with Selenium / Puppeteer or Playwright on sites like Idealista that is blocked by DataDome you can use Kameleo. While the above mentioned automation frameworks fail due to as mentioned: "Headless browsers have unique characteristics that differ from regular browsers. DataDome can detect these discrepancies and identify the browser as automated." While Kameleo's browsers: Chroma and Junglefox is designed for webscraping. They hide under the radar, melts in the crowd as it provides a natural browser fingerprint. With this you will be able to scrape with Selenium+Kameleo or Puppeteer+Kameleo or Playwright+Kameleo
Well well, it can be easily bypassed / scrapped by solving the audio challenge by using any speech to text API. Now I can effortlessly bypass datadome protected sites in puppeteer itself.
Seriously guys there is no need to use an external service!