THE LAB #80: Scraping food delivery data
Use both the website and the mobile apps to get data from food and grocery delivery data

If you live in a city big enough, you probably have seen delivery riders speeding all day to bring people tasty Crispy Mac Bacon to their homes as fast as they can. In any case, even if you haven’t tried this service by yourself, it’s clear that food delivery services like Deliveroo, Glovo, Uber Eats, and others host an incredible amount of information we can use to understand the food and restaurant market in a city.
Extracting details on menus, prices, and customer feedback from these platforms enables analysts and industry operators to perform robust competitor analysis. For example, analyzing data from food delivery apps enables identifying popular cuisines in an area and unserved niches, tracking customer ordering habits, and benchmarking competitor performance. Insights gleaned from such data – pricing strategies, promotions, and customer feedback – allow businesses to refine their offerings and find room for improvement.
In short, web scraping food delivery data can inform menu design, pricing optimization, and marketing strategies based on market trends.
One peculiarity of food delivery apps is that usually have both a web version and an app, which may contain different data, as we’ll see later in the article. So if we want to scrape data from food delivery apps, we must be prepared to inspect the traffic both from the website and from apps, which is not always straightforward, but may be worth the extra effort. In fact, in some cases, apps use different API endpoints, in some cases with more details.
This means that by looking at the data flowing in mobile apps, you might access endpoints or details that web pages don’t directly show (such as internal API endpoints or more granular data). In the sections below, we’ll explore data from these services and then dive into a practical example with Glovo – using both the website and mobile app – to demonstrate how to scrape such data.
Before proceeding, let me thank NetNut, the platinum partner of the month. They have prepared a juicy offer for you: up to 1 TB of web unblocker for free.
What Data Can You Get from Food Delivery Services?
Before going into details of the Glovo example, let’s see what we can extract from a food delivery platform. Some examples of data points you can scrape include:
Restaurant details: names, addresses, coordinates (latitude/longitude), cuisine types, operating hours, contact details (imagine you’re a salesman of a CRM solution for restaurants, how this can be helpful to build your prospect list)

Menu items and prices: the list of dishes or products each restaurant offers, along with their descriptions and prices (including any meal deals or combos).
Promotions and discounts: any ongoing special offers, promo codes, or loyalty rewards being advertised on the platform.

Customer ratings and reviews: aggregated ratings for restaurants or specific dishes and textual reviews or feedback from customers.
Delivery and logistics info: delivery fees, estimated delivery times, and coverage areas or delivery zones for particular locations.
Operational data: indicators like preparation times, order histories (for logged-in users, you can see past orders), and other metadata.


Thanks to the gold partners of the month: Smartproxy, Oxylabs, Massive, Scrapeless. From today, please welcome also Rayobyte, SOAX, ScraperAPI and IPRoyal. They prepared great offers for you, have a look at the Club Deals page.
Unique Challenges of Scraping Food Delivery Data
Scraping food delivery platforms is rewarding, but it comes with some unique challenges:
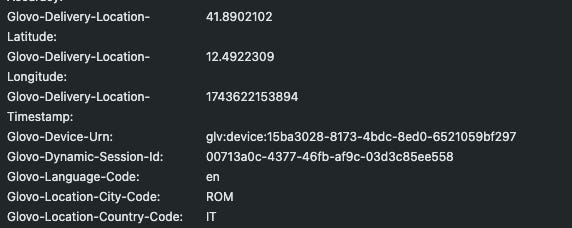
Geo-targeted content: These services are highly location-specific. The list of restaurants or availability of items depends on the user’s address or GPS location. This means a scraper must emulate providing a location. For example, Deliveroo or Glovo will ask for your address or city before showing any restaurants. As a scraper, you may need to supply coordinates or city identifiers to retrieve data. If you want data from multiple cities, you have to iterate over those locations, as example, setting coordinates in the headers of the requests.
Dynamic content loading: Food delivery websites often use single-page applications or heavy AJAX/JavaScript. The initial page load might be just a skeleton; then, the actual restaurant lists or menu data are fetched via background XHR requests. If you try to scrape HTML directly, you might miss dynamically loaded data. A naive HTML scraper could get an almost empty page. Instead, you often need to replicate the API calls that the front end makes (or use a headless browser). In practice, the underlying API endpoints (which return JSON data) are far more reliable than parsing HTML for these sites.
Anti-bot and anti-scraping measures: Prominent platforms implement defenses to protect their data and availability. For instance, Glovo has described using AWS CloudFront and AWS WAF (Web Application Firewall) to shield their public APIs from abuse, including blocking common web exploits and bots that attempt to evade detection. This can manifest as rate limiting, IP blocking, or presenting challenges like CAPTCHAs to clients that appear non-human. In practical terms, a scraper may need to use rotating proxies or solve challenge pages if hitting these endpoints too aggressively. Sometimes, the mobile app APIs have slightly different protection levels than the public web endpoints – but as a rule, be prepared to handle things like authentication requirements, hidden tokens, or request signatures.
Content variability and volume: A large city can have hundreds or thousands of restaurants on a platform. The data might be paginated or segmented by cuisine categories. Scrapers need to handle potentially big lists and possibly paginate through results. Also, menus can be nested (categories within a menu, options for items), requiring traversing multiple endpoints or pages per restaurant.
Despite these challenges, you can successfully scrape and aggregate food delivery data with careful planning (setting proper location parameters, mimicking required headers, respecting rate limits, etc.). Next, we will move to a hands-on example using Glovo, a popular international delivery service, to illustrate how to scrape the website and the mobile app data.
Hands-On Tutorial: Scraping Glovo Data (Web & Mobile)
Glovo is an on-demand delivery platform operating via web and mobile apps. We’ll use Glovo as a case study to demonstrate scraping techniques. First, we’ll look at how to find and use the website’s API endpoints to get data. Then, we’ll show how to scrape data from the mobile app by intercepting its network calls (using a tool called HTTP Toolkit). The goal is to extract structured information such as restaurant lists and menu details.
Scraping Glovo’s Website API Endpoints
Even though Glovo does not provide a public REST API for general use, the web application itself uses internal API calls to fetch data (in JSON format) after you select a location. By inspecting the network calls that the website makes, we can identify these endpoints and use them directly. This saves us from parsing HTML and gives cleaner data.
The scripts mentioned in this article are in the GitHub repository's folder 80.GLOVO, which is available only to paying readers of The Web Scraping Club.
If you’re one of them and cannot access it, please use the following form to request access.
1. Setting a location: On the Glovo website, the first thing you do is choose your city or allow location access. The site might internally translate an address or city name into coordinates or an internal city ID. In Glovo, in both the mobile and web versions, we can simply set our location by passing special headers in our requests to the API endpoints.