In these pages, especially in The Lab articles, we often provide solutions to bypass specific anti-bot protections on particular websites, just as we’re doing today.
However, instead of focusing on the code for bypassing Cloudflare on Depop (which I’ll provide in the usual repository anyway), I wanted to share a broader perspective on how to approach anti-bot solutions in general, along with some numerical examples.
Before proceeding, let me thank Decodo, the platinum partner of the month. They are currently running a 50% off promo on our residential proxies using the code RESI50.
Depop is a social shopping app and online marketplace where users can buy, sell, and discover secondhand and vintage fashion, streetwear, and unique items. Just like other second-hand websites, such as Vinted or Mercari, it blends elements of e-commerce and social media, allowing sellers to create profiles, post listings with photos, and interact with buyers through likes, comments, and direct messages. Its focus is mainly on clothing and accessories, with a catalog of over 30 million items across the men's and women's categories.
Given its dimension and relevance in the second-hand fashion industry, Depop is a gold mine of data, and it doesn’t surprise me that it’s a requested target for scraping (and even a well-protected one).
This episode is brought to you by our Gold Partners. Be sure to have a look at the Club Deals page to discover their generous offers available for the TWSC readers.
Depop is protected by Cloudflare Bot Detection, configured in a quite restrictive way. In fact, just like most e-commerce websites, it has internal APIs to paginate items, which you can easily detect by inspecting the network traffic with the browser.
However, if you attempt to replicate this request via cURL, you encounter an error nine times out of ten, even if you don’t have to pass a Cloudflare cookie, as it usually happens when CF is involved.
The first idea that comes to mind when dealing with an anti-bot is to create a solution that lasts over time; therefore, we might be tempted to use a browser and extract data from it.
In this case, I’m using Camoufox to load the men’s catalog page and intercept the API calls happening at the network level (thanks to Antonello Zanini for the inspiration for the code).
from camoufox.sync_api import Camoufox
import json
import time
import random
import os
with Camoufox(
headless=False, # To save resource
geoip="86.62.29.238" # An IP from the US to geolocate the browser in the US
) as browser:
page = browser.new_page()
# Intercept the AJAX API request to the Depop APIs
def handle_response(response):
# If the API request is the one responsible for getting product data
if response.url.startswith("https://webapi.depop.com/api/v3/search/products/"):
try:
# Export product data to JSON
json_data = response.json()
with open("mens.json", "w", encoding="utf-8") as f:
json.dump(json_data, f, indent=2)
print(f"✅ mens.json file created successfully!")
print(f"Captured API response from: {response.url}")
except Exception as e:
print(f"Failed to get JSON from response: {e}")
# Attach the response handler
page.on("response", handle_response)
response = page.goto("https://www.depop.com/category/mens/")
# Wait for the product to appear on the page
page.locator("#main ol").wait_for(timeout=60000)
# Scroll down until mens.json is created
print("Starting to scroll down to capture products...")
scroll_count = 0
max_scrolls = 50 # Safety limit to prevent infinite scrolling
while scroll_count < max_scrolls and not os.path.exists("mens.json"):
# Scroll down using mouse wheel
page.mouse.wheel(0, 1000) # Scroll down by 1000 pixels
# Wait for content to load
time.sleep(random.uniform(2, 4))
scroll_count += 1
print(f"Scroll attempt {scroll_count}...")
# Check if file was created
if os.path.exists("mens.json"):
print("🎉 mens.json file found! Stopping scroll.")
break
if os.path.exists("mens.json"):
print("✅ Success! mens.json file has been created.")
else:
print("❌ mens.json file was not created after maximum scroll attempts.")
# Release the browser resources
browser.close()
It’s quite self-explanatory: we load the page and, since the API call does not immediately happen, we scroll down the page until new products are loaded and the mens.json file is created. using the handle_response method, we intercept the API calls and, when we find the right one, we save the results in the JSON file.
Before continuing with the article, I wanted to let you know that I've started my community in Circle. It’s a place where we can share our experiences and knowledge, and it’s included in your subscription. Give it a try at this link.
This simple scraper is working, but is it the best option for scraping the whole website?
Every API call returns 24 items. Let’s suppose that the information retrieved from that is enough for our needs. Considering that, including only men's and women's clothing, we have 34.4 million items, it means we need to make 1.43 million API calls.
The scraper needs to load the page, scroll down, and wait for the items to be shown, so we can estimate an average of 3 seconds per call, which, when multiplied by the total number of calls needed, makes a total of 4.3 million seconds of execution time (around 1195 hours).
If we deploy this scraper to AWS, using a t3.medium instance (below that, a browser barely runs), which costs 0.0416 USD per hour, we’re spending 50 USD for a single run, just for the execution runtime. This does not consider any potential technical issues, such as the degradation of performance during the usage of a browser (the more pages you load, the more memory you’ll need to run it).
Then you probably also need a proxy. Considering that just the HTML of the home page of the woman category, without the images (which can be excluded), weighs 450Kb, the JSON response of the API is 350KB, and there are many other API loaded when scrolling, we can estimate a rough 1MB per request of bandwidth. Multiplying by 1.43 million requests, we could easily pass the 1.5 TB of bandwidth for a single snapshot. For such a volume of bandwidth, according to the ProxyPrice calculator, the cost starts from 2000 USD, definitely something for deep pockets.
Delegating a browserless solution: ScraperAPI
But what if we find a way to use the internal API and delegate the bypass of the antibot to external tools, in this case, ScraperAPI?
First of all, we need to understand how the API works: when calling the API, we need to pass a few values as string parameters:
The cursor is a placeholder that indicates the starting point for the following API call.
The scripts mentioned in this article, like the Scrapy scraper and the Camoufox one, are in the GitHub repository's folder 92.DEPOP, available only to paying readers of The Web Scraping Club.
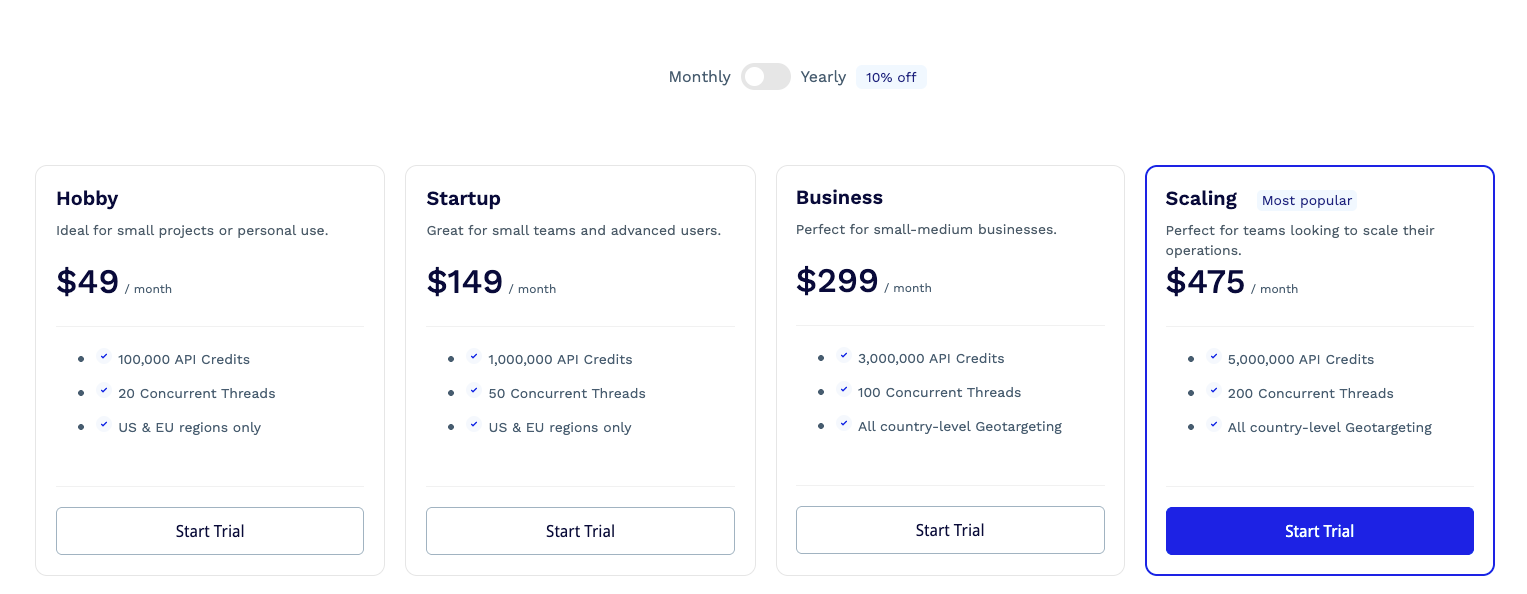
Since we don’t need to render the JS on the website to have a correct response, each request costs one credit, so we’re well inside the “Business” credit plan, which costs 299 USD for 3 Million credits.
Since proxies are included, we’re basically spending 143 USD in credits for 1.43 million API calls.
Build your own browserless solution with Scrapy
Continue reading this post for free, courtesy of Pierluigi Vinciguerra.