
THE LAB #2: scraping data from a website with Datadome and xsrf tokens
A real world use case of a simple scraper that does not get blocked by Datadome

Here’s another post of “THE LAB”: in this series, we'll cover real-world use cases, with code and an explanation of the methodology used.
In the future, this kind of content will be available only to paying subscribers. Being one of the first of the series, this one will be available for free until 22th of Sept 2022, then will be behind a paywall.
Being a paying user gives:
Access to Paid Content, like the post series called “The LAB”, where we’ll go deep diving with code real world cases (view here an example).
Access to the Github repository with the code seen on ‘The LAB”
Access to private channels on our Discord server
But in case you want to read this newsletter for free, you will always get a post per week about:
News about web scraping
Anti-bot software and techniques insights
Interviews with key people in the industry
And you can always join the Web Scraping Club Discord server
Enough house-keeping for now, let’s start.
What is Datadome?
Datadome Bot protection is one of the key players in the anti-bot software industry.
As stated on their website, the solution is used on several important websites such as FootLocker, Rakuten, and even Reddit, as you can see from the picture below.

So, sooner or later, in your life as a web scraper, you'll surely face one website protected with this technology.
These days I needed to update a scraper that eluded Datadome so it's a good time for writing the process that allowed me to scrape the data from this website.
Are you looking for a Birkin?
In case you know what a Birkin is, you probably understood that the website in question is Hermes.com. For the others, a Birkin is one of the most iconic bags crafted by the Maison Hermes and it costs like a supercar (and no, it's not sold online anyway).

From a quick analysis of the network tab of the browser, we can see that by browsing the products in every category, we call an internal API that shows the product details we need.
Let's start with the basic stuff
Let's start with our standard Scrapy spider and see if we can get inside the website, after some make-up to our DEFAULT_REQUEST_HEADERS property.

And soon we can see Datadome at work. We got redirected and locked out of the website, while on the browser the redirect leads to the Home page of the website.
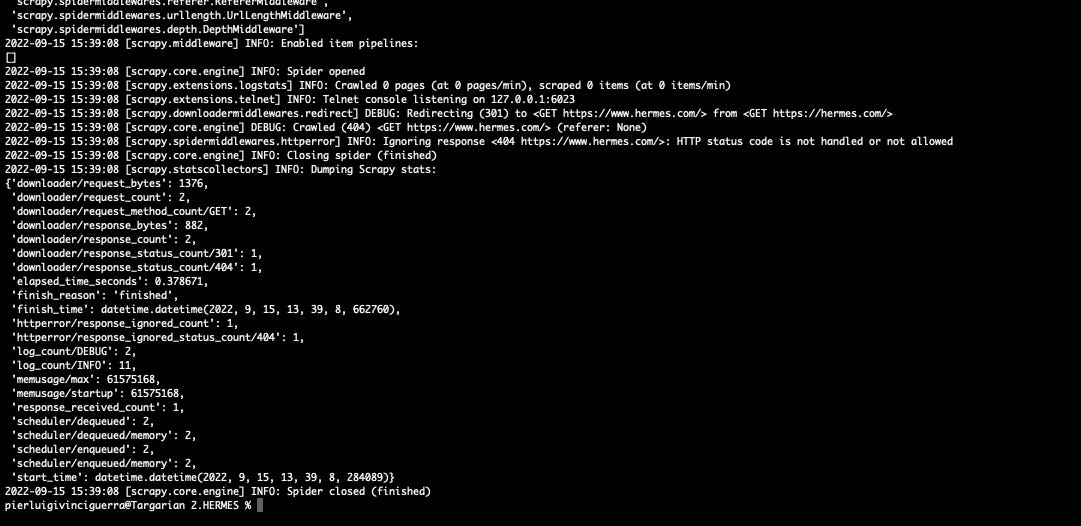
A different path.
Hermes does not have an official App but I can use the same procedure explained in the first post of THE LAB to see how the website behaves when accessed by mobile.
