In a previous article, we scraped Booking.com with Playwright by loading pages and extracting hotel info via HTML elements.
That’s for sure a feasible and interesting approach, but when it comes to massive scraping, it can be challenging. Playwright makes you pay a heavy toll for computing and memory, and scaling the operations can be painful.
Today, we’re trying a different approach: we’ll have a look at the internal APIs of the website and use them to extract data without the need for a browser. By reverse-engineering Booking’s private GraphQL API, we can also eliminate the need to parse complex HTML and use the structured JSON data directly, making our data extraction pipeline more reliable.
Before proceeding, let me thank Decodo, the platinum partner of the month, and their Scraping API.
Scraping made simple - try Decodo’s All-In-One Scraping API free for 7 days.
Using Booking’s internal API (GraphQL endpoint) offers several advantages over traditional HTML scraping:
Faster & More Efficient: Without a browser, requests are lightweight. You can use a fast HTTP client (e.g. Python’s httpx with HTTP/2 support) to fetch data quickly. There’s no need to render pages or wait for UI interactions, so scraping completes much faster. You can even send multiple requests in parallel if needed, which is harder to do with a single browser instance.
Simpler Data Parsing: Instead of scraping HTML and dealing with CSS selectors for each property card, the internal API returns data in structured JSON format. This means no brittle selectors or DOM traversal – you can directly parse JSON fields (hotel name, price, rating, etc.) from the response. In short, no more worrying about HTML structure changes, just straightforward JSON parsing.
Less Resource Intensive: Running a headless browser (like Playwright) consumes a lot of memory and CPU. By using raw HTTP calls, you drastically reduce resource usage. This makes the scraper more scalable and easier to run in cloud functions or simple servers.
Access to Hidden Data: Sometimes the internal API provides data that might not be directly visible in the initial HTML. For example, Booking’s GraphQL can return detailed pricing, availability, or map coordinates without additional page loads. You can take advantage of these endpoints to obtain more comprehensive information (such as all prices for a specific date range) that would otherwise require additional steps with HTML scraping.
Avoiding Some Anti-bot Mechanisms: Because you’re mimicking the site’s own network calls, you may appear more like a normal user’s browser activity. As long as you include the correct headers and behave reasonably, this can help evade simple anti-scraping measures. (Of course, you still need to respect rate limits and possibly use proxies – scraping ethics and legal considerations remain important.)
This episode is brought to you by our Gold Partners. Be sure to have a look at the Club Deals page to discover their generous offers available for the TWSC readers.
Of course, all these advantages don’t come for free. These endpoints are private and undocumented, which means we have to do some homework to use them. And if we want to cover a certain portion of land, we should use our evergreen grid technique, which we also used for Zillow in the past.
Discovering Booking.com's Internal GraphQL API
The first step is to figure out what API calls Booking.com uses internally when you search for properties.
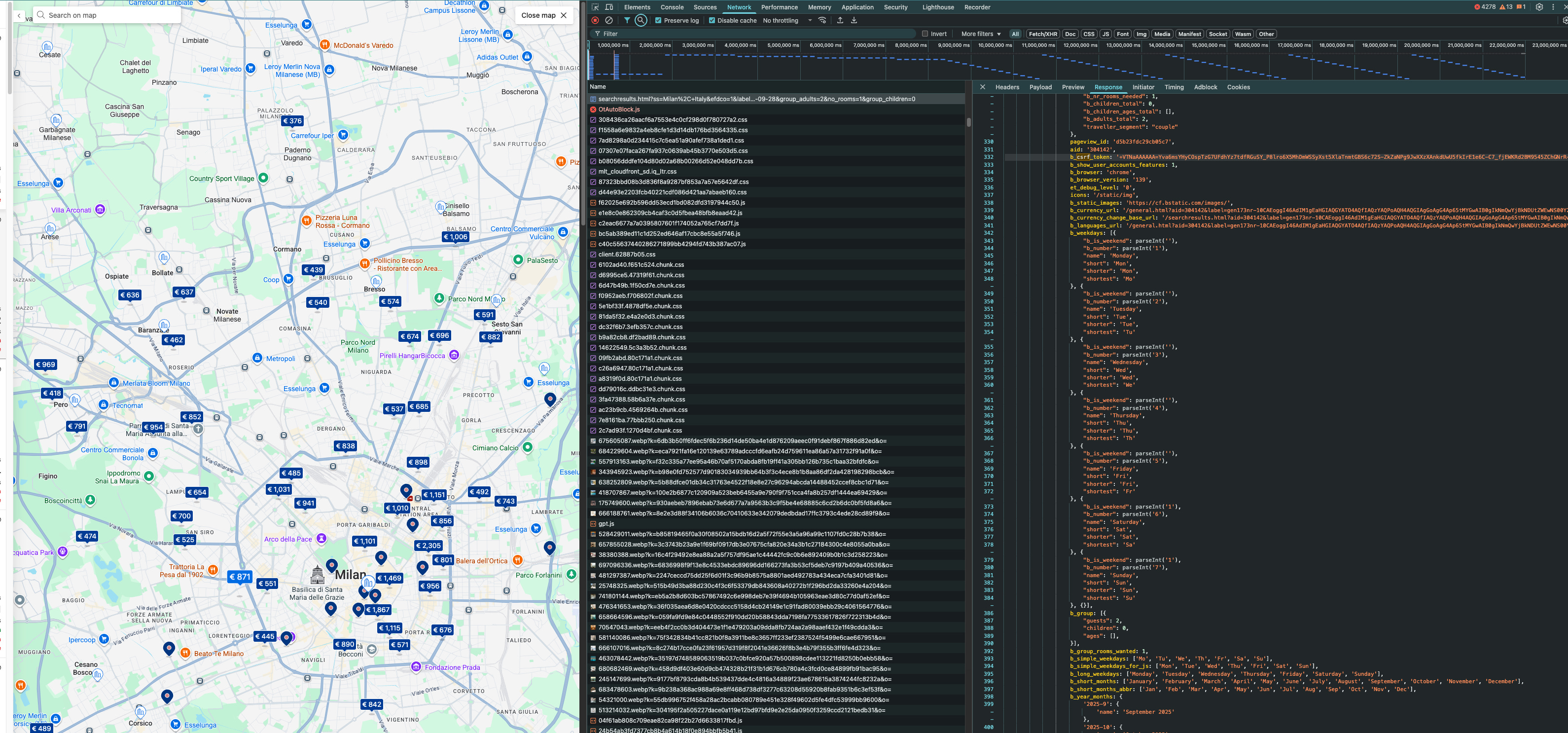
If you perform a hotel search on the website (e.g. search for hotels in “Milan, Italy” with dates), you can inspect your browser’s Network panel. Booking.com’s site uses GraphQL requests to load search results (especially in map view or as you scroll). Open the “view on map” page and zoom in or out, you will see requests to an endpoint like https://www.booking.com/dml/graphql?.... These are GraphQL queries with names such as FullSearch or MapMarkersDesktop that return hotel listings and metadata.
How to find the GraphQL request: Open DevTools, go to the Network tab, and filter by XHR or Fetch requests. Scroll or interact with the page to trigger loading more results or the map. You should see a request to booking.com/dml/graphql appearscrapfly.io. You can right-click this request and choose “Copy as cURL” (in Chrome/Firefox) to get the full details. This will give you the URL, request headers, and the JSON payload being sent. The payload will include an operation name (e.g. "operationName":"MapMarkersDesktop" or "FullSearch") and a large GraphQL query string with variables (such as dates, destination, number of guests, etc.).
For instance, here’s a simplified example of what such a GraphQL payload might look like (highly truncated for brevity):
Don’t be intimidated by the size of the query – you typically don’t need to craft it from scratch, and once you change the checkin/checkout dates, the bounding box and the number of people for the booking, you’re almost good to go.
But there’s one more crucial ingredient to obtain first: the CSRF token.
Retrieving the CSRF Token (Authentication Step)
Booking.com’s GraphQL endpoints are protected by a token to prevent unauthorized access. Specifically, the requests require an X-Booking-CSRF-Token header. If you try to call the GraphQL URL without this token, you’ll get an error or no data. Fortunately, this token is provided to your browser when you load the search page, and we can grab it for our scraper.
When you load a search results page (either the regular list or the map view), the HTML contains a line with a b_csrf_token value. For example, in the page source you might find something like: b_csrf_token: 'vFCWaAAAAAA=AbCdEfGh...';. We can extract this token via a simple regex or HTML parse. In fact, an example from a scraper shows extracting it with:
import httpx, re
search_url = "https://www.booking.com/searchresults.html?dest_id=-121726&dest_type=city&checkin=2025-09-27&checkout=2025-09-30&group_adults=2&no_rooms=1&group_children=0"
# (The URL above is an example for Milan, Italy with specified dates and 2 adults)
client = httpx.Client(http2=True) # use HTTP/2 for better simulation of browser:contentReference[oaicite:7]{index=7}
res = client.get(search_url)
html = res.text
# Extract CSRF token from HTML
csrf_token = re.findall(r"b_csrf_token:\s*'(.+?)'", html)[0]
print("Got CSRF token:", csrf_token)
After running the above, csrf_token will hold a long string (for example, "+VTNaAAAAAA=Yva6msYHyCOspTzG7UFdhYz7tdfRGuSY_P8lro6X5MhDmWSSyXst5XlaTnmtGBS6c72S-..."). This token is essentially an anti-CSRF measure. We need to include it in our subsequent API requests.
Note on token expiration: The CSRF token is not permanent. It can expire after some time (or number of requests). If you start getting 401/403 errors from the API, you likely need to fetch a fresh token. A simple strategy is to request a new search page (or refresh the existing one) periodically to grab an updated token, especially if your scraping session is long-lived. In practice, you can write your code to automatically retry obtaining a new token if a request fails due to authentication.
Before continuing with the article, I wanted to let you know that I've started my community in Circle. It’s a place where we can share our experiences and knowledge, and it’s included in your subscription. Give it a try at this link.
Calling the Internal GraphQL API with an HTTP Client
Now that we have the GraphQL request payload and a valid CSRF token, we can simulate the Booking.com API call. Continuing with our Python example using httpx, here’s how to set up the request:
# Construct the GraphQL request payload (obtained via DevTools or page parse).
# For simplicity, assume we have it as a Python dict called `graphql_payload`.
graphql_payload = {
"operationName": "FullSearch",
"variables": { ... }, # use the variables exactly as obtained
"query": "query FullSearch($input: SearchQueryInput!) { ... }"
}
# Define headers for the POST request
headers = {
"Content-Type": "application/json",
"Origin": "https://www.booking.com",
"Referer": search_url,
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)...", # a realistic UA
"X-Booking-CSRF-Token": csrf_token
}
response = client.post("https://www.booking.com/dml/graphql?lang=en-us", json=graphql_payload, headers=headers)
data = response.json()
The scripts mentioned in this article, like the Scrapy scraper and the Camoufox one, are in the GitHub repository's folder 93.BOOKING, available only to paying readers of The Web Scraping Club.
We include necessary headers like Content-Type: application/json, an Origin and Referer matching Booking.com, and the X-Booking-CSRF-Token with the token we extracted. These help our request look legitimate. Using a realistic User-Agent string is also important (often you can reuse the one from the copied cURL).
The GraphQL endpoint URL can include some query parameters (like lang=en-us, aid=... etc.). It’s usually fine to include the same query params you saw in the network call or those from the page’s URL.
We send the JSON payload in the POST request. This payload should be exactly what the site expects.
The response will be a JSON object as follows
results = data["data"]["searchQueries"]["search"]["results"]
for hotel in results:
name = hotel["displayName"]["text"]
price = hotel.get("priceDisplayInfoIrene", {}).get("displayPrice", {}).get("copy", {}).get("translation")
# ... and so on for other fields
Handling Pagination and Result Limits
Continue reading this post for free, courtesy of Pierluigi Vinciguerra.