
How to Scrape E-Commerce Websites With Python
A tutorial on the Oxylabs' E-commerce Scraper API

In today’s article, together with our partner Oxylabs, we’re deep-diving into the usage of their E-commerce Scraper API for getting data from Amazon and Aliexpress.
In the e-commerce industry, market analysts largely use web scraping to gather public web data at scale. This data can then be used for multiple purposes, such as market research, trend analysis, or even pricing new products. This tutorial demonstrates scraping public data from e-commerce platforms using Python and Oxylabs’ E-Commerce Scraper API.
What is Oxylabs’ E-Commerce Scraper API?
Oxylabs’ E-Commerce Scraper API scrapes region-specific data from multiple e-commerce websites with a high success rate without revealing your IP. It scales well and allows for scraping Amazon, Ali Express, Best Buy, eBay, Etsy, Google Shopping, Walmart, and many more. This article demonstrates scraping products from Amazon and AliExpress. Before scraping, you’ll have to log in to your Oxylabs account to retrieve API credentials. You can simply sign up for free and go to the dashboard.
Support for Amazon
E-Commerce Scraper API has exclusive support for the Amazon platform – you post an Amazon data source along with a query, and the API scrapes the results on your behalf while automatically parsing them.
A source key tells the E-Commerce Scraper about the particular page type we will target for scraping. Here’s the list of all Amazon data sources supported by the API:

Support for other e-commerce websites
Scraping e-commerce platforms other than Amazon is also easy. You just need to provide the full URL of the product page, a target from which you want to scrape data, and the source key set to universal_ecommerce. The scraper does all the rest.
Step-by-step guide for scraping e-commerce website
It’s time to see E-Commerce Scraper API in action. For the demonstration, let’s target Amazon and AliExpress.
Step 1 - Creating the environment
Ensure that Python 3.6+ is installed on your system. Additionally, you would need the following packages, too:
Requests: Send the request to the Scraper API.
Pandas: To populate the data in the DataFrame data structure.
To install the packages, use the following command:
pip install requests pandasStep 2 - Code in action
As stated earlier, we’ll code two different scrapers: one for the Amazon Search Page to scrape the list of products against a search query, and the other for scraping single product information from the AliExpress Product Information page.
Scraper for Amazon search results page
On the Amazon website, you can search for a product using any search query for that product. Amazon displays all the related products for that query. For example, for the search query “kids t-shirts”, the resultant page looks like this:

This contains the product title, price, ratings, picture, and other details. The search data source is designed to retrieve the search results page data. We can get this data in HTML form and the structured output using the parse flag. Let’s have a look at how to get such results.
The first step is to create a payload structure that contains different parameters. Here is a list of all the parameters, along with their description:


We can create a payload structure using any of these parameters. Only the source and search parameters are mandatory; the rest are optional.
payload = {
'source': 'amazon_search',
'domain': 'com',
'query': 'kids tshirt',
'start_page': 2,
'pages': 2,
'parse': True,
}After the payload structure is ready, you can create a post request by passing your authentication key.
response = requests.post(
'https://realtime.oxylabs.io/v1/queries',
auth=(USERNAME, PASSWORD),
json=payload
)Once the parsed response is ready, convert it to JSON format and extract the required product attributes from this JSON result. We will extract the Product title, Product ASIN, price and URL.
result = response.json()["results"][0]["content"]
search_results = result["results"]["organic"]
# Create a DataFrame
df = pd.DataFrame(columns=["Product Title", "Product ASIN", "Product Price",
"Product URL"])
for item in search_results:
title = item["title"]
asin = item["asin"]
price = item["price"]
url = item["url"]
df = pd.concat(
[pd.DataFrame([[title, asin, str(price), url]], columns=df.columns),
df],
ignore_index=True )In the above code, we extracted and stored the data in a DataFrame to save it. You can then print or save the data in CSV or JSON format.
# Print the data on screen
print("Product Name: " + title)
print("Product ASIN: " + asin)
print("Product Price: " + str(price))
print("Product URL: " + url)
# Copy the data to CSV and JSON files
df.to_csv("amazon_search_results.csv", index=False)
df.to_json("amazon_search_results.json", orient="split", index=False)Let’s have a look at the complete code and its output:
# Import required library files
from pprint import pprint
import requests
import pandas as pd
# Define credentials
USERNAME = "<your_username>"
PASSWORD = "<your_password>"
# Structure payload
payload = {
"source": "amazon_search",
"domain": "com",
"query": "kids tshirt",
"start_page": 2,
"pages": 2,
"parse": True,
}
# Get response
response = requests.post(
"https://realtime.oxylabs.io/v1/queries",
auth=(USERNAME, PASSWORD),
json=payload
)
# Print prettified response to stdout
pprint(response.json())
# Extract data from the response
result = response.json()["results"][0]["content"]
search_results = result["results"]["organic"]
# Create a DataFrame
df = pd.DataFrame(columns=["Product Title", "Product ASIN", "Product Price", "Product URL"])
for item in search_results:
title = item["title"]
asin = item["asin"]
price = item["price"]
url = item["url"]
df = pd.concat(
[pd.DataFrame([[title, asin, str(price), url]], columns=df.columns),
df],
ignore_index=True
)
# Print the data on screen
print(f"Product Name: {title}")
print(f"Product ASIN: {asin}")
print(f"Product Price: {price}")
print(f"Product URL: {url}")
# Copy the data to CSV and JSON files
df.to_csv("amazon_search_results.csv", index=False)
df.to_json("amazon_search_results.json", orient="split", index=False)
Note: The source key in the payload is set to amazon_search because we are scraping the search results page.
Output:


Scraper for AliExpress product page
Assume we want to scrape the following product page:
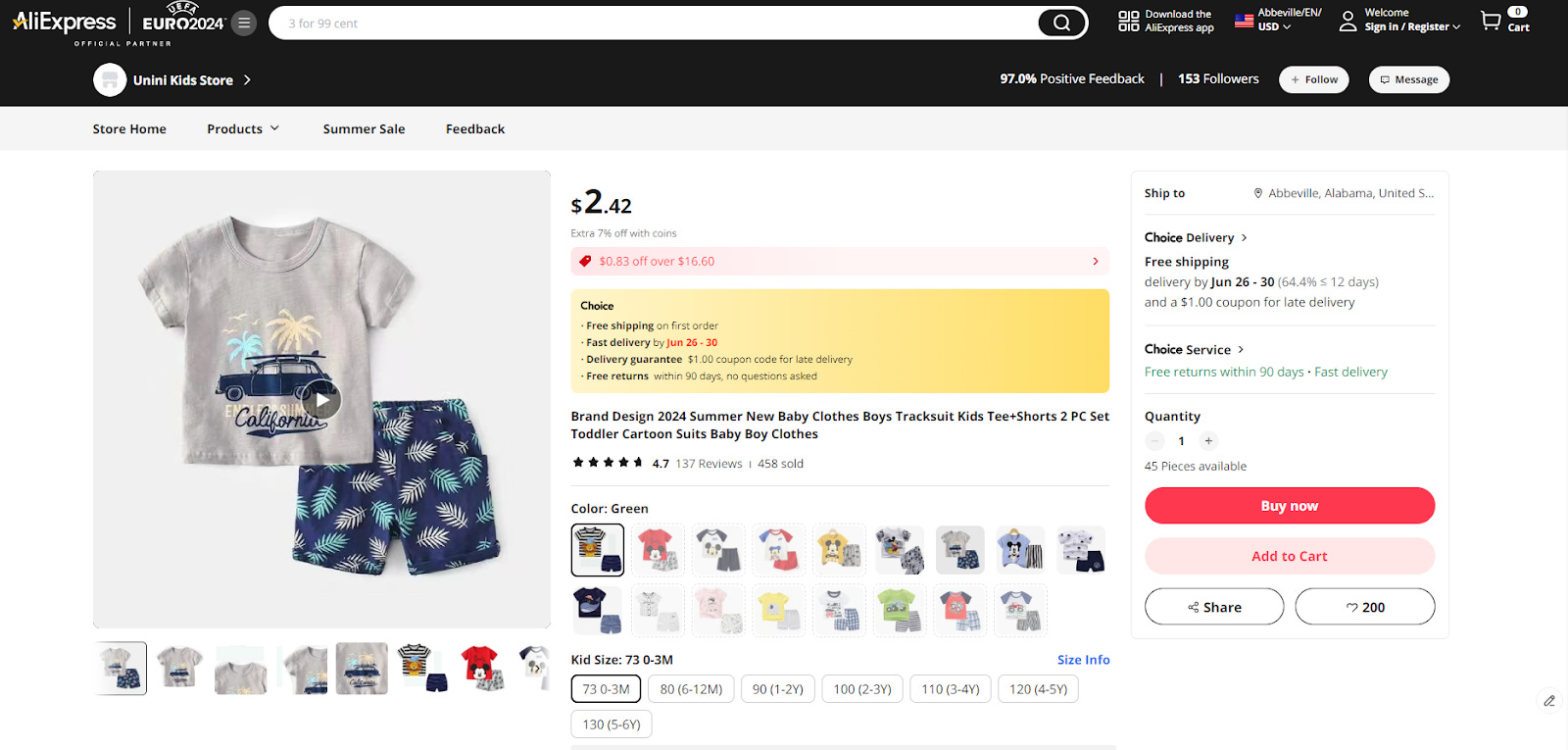
This page contains information about the product title, price, description, size details, and much more.
To scrape data from this AliExpress product page, we need to change the payload structure and set the data source to universal_ecommerce:
# Structure payload.
payload = {
'source': 'universal_ecommerce',
'url': 'https://www.aliexpress.com/item/1005006722301692.html',
'parse': True,
}As we did in the Amazon example, send a post request with your account credentials to the scraper API and then extract and print the desired attributes.
# Get response.
response = requests.post(
'https://realtime.oxylabs.io/v1/queries',
auth=(USERNAME, PASSWORD),
json=payload
)
# Instead of response with job status and results url, this will return the
# JSON response with the result.
result = response.json()["results"][0]["content"]
print ("Poduct Name: "+ result["title"])
print ("Price: " + result["currency"]+ str(result["price"]))
print ("Description: "+ result["description"])Let’s have a look at the complete code and its output:
# Import required modules
import requests
# Define credentials
USERNAME = "<your_username>"
PASSWORD = "<your_password>"
# Structure payload
payload = {
"source": "universal_ecommerce",
"url": "https://www.aliexpress.com/item/1005006722301692.html",
"parse": True,
}
# Get response
response = requests.post(
"https://realtime.oxylabs.io/v1/queries",
auth=(USERNAME, PASSWORD),
json=payload
)
# Extract result from the response
result = response.json()["results"][0]["content"]
# Print product details
print("Product Name: " + result["title"])
print("Price: " + result["currency"] + str(result["price"]))
print("Description: " + result["description"])
Here is the output:

Conclusion
This article demonstrated how to scrape e-commerce stores using Python as well as explored Oxylabs’ E-Commerce Scraper API. Oxylabs’ E-Commerce Scraper API makes scraping public data from various e-commerce websites easy, secure, and scalable, ensuring a high success rate for each scrape request.
 |
|