
Scraping Akamai-protected websites with Scrapy
A quick checklist for a successful scraping project

In the latest The LAB post about Bearer Tokens I’ve chosen Loewe’s website as a target for demonstrating how we can scrape API endpoints that use these tokens as an authentication method.

The website is also protected by the Akamai Bot Manager so, given my previous experience, I used a quick cheat for bypassing it since it was not the main purpose of the article.
I’ve basically filled up the cookie jar with some Akamai cookies obtained by browsing from my laptop, in order to say to the website that I’ve already passed successfully its challenge, allowing me to get the data I needed.
My original idea for this article was to write a how-to aimed to describing the process of getting this token automatically with Playwright before starting the Scrapy spider (and probably I’ll do the same article for other anti-bot solutions).
I started writing some code but then… I realized it was not necessary! Following a very basic checklist is enough to bypass Akamai Bot Manager with a simple Scrapy spider.
If you’re aware of some Akamai-protected website that doesn’t behave like this, please let me know. I’ve tested the following solution on Zalando, Loewe, Versace, NewBalance, and Rakuten, all with the same results and I’m still quite staggered of the low level of sophistication needed to get the data.
Let’s use for this example a scraper for the Versace website, since the version running in my company stopped working and, ironically, it took some time for me to understand how to make it work again.
I’m creating a simplified version of the scraper where we basically crawl all the products’ pages, scraping only their titles as a test.
The original scraper’s configuration
I’m anticipating your considerations: this original scraper was written years ago, probably in a hurry, and worked until some weeks ago, with some fixes during the time due to changes in the HTML code of the website.
In fact, we never got blocked because of an anti-bot before, and fixing XPATHs was the only maintenance we did during these years.
So the settings.py file of our scrapers looked like this:
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36'
...
...
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}We were using an outdated User Agent and no custom headers for the requests, so when the website implemented Akamai, the scraper stopped working.
The funny part is that I didn’t immediately have a look at these settings, imagining they were updated, but I tried to use scrapy-impersonate and other solutions as a workaround, without success.
The new scraper’s configuration
After realizing that the settings were more than out of date, I refreshed them.
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
...
...
DEFAULT_REQUEST_HEADERS = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US,en;q=0.7",
"cache-control": "max-age=0",
"priority": "u=0, i",
"sec-ch-ua": "\"Brave\";v=\"125\", \"Chromium\";v=\"125\", \"Not.A/Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"macOS\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"sec-gpc": "1",
"upgrade-insecure-requests": "1"
}With an updated User Agent and a coherent set of headers, the scraper runs smoothly without any additional configuration, at least on my laptop.

Let’s see how the scraper behaves when running on a virtual machine in a datacenter.
Testing the solution on cloud platforms.
Now we know the scraper works, let’s see how we can make it run on a production environment.
Let’s start on an AWS machine and launch the scraper to see what happens.

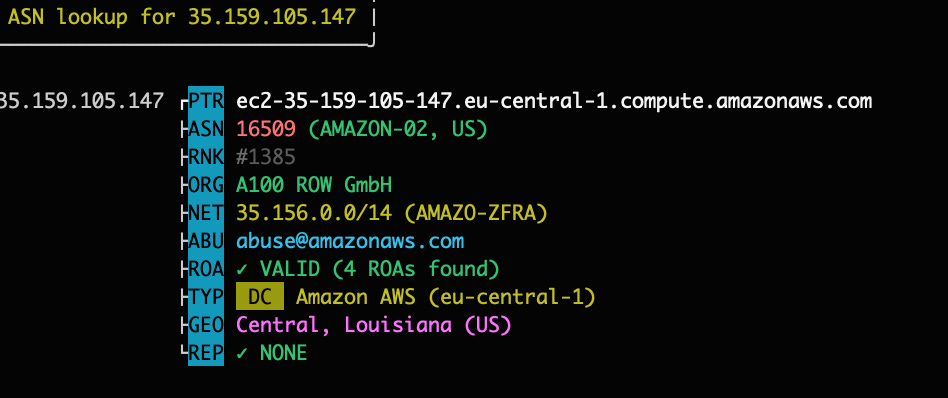
The first request gets blocked and disconnected, so no results are returned. Every cloud provider publishes the addresses of the subnet of their datacenter, so it’s very easy for anti-bot solutions to block them.
Using the ASN tool, in fact, the IP we used is easily associated with an AWS datacenter and its region, so it’s not a surprise the scraper is blocked.
In my experience, not every cloud provider is the same when it comes to web scraping.
Usually, AWS IPs are the first that are getting blocked while Azure and GCP have lesser chances to be banned, probably because anti-bots are afraid to block their search engine.
In fact, moving the scraper to Azure makes it work, without the need for any proxy.
Final remarks
To me, it seems strange that a well-known anti-bot solution could be bypassed so easily, but this is the configuration of all the actual scrapers we have in production that are getting data from Akamai-protected websites. Probably, for more sensitive data and use cases, like fraud protection, the countermeasures taken are more effective, but when scraping public data the most challenging sites I’ve encountered just need only some datacenter proxies to bypass the rate limit on a single IP.
https://www.hermes.com/kr/ko/
https://www.hermes.com/us/en/faq/
Can you confirm if it also works on Hermes? Use playwright.
Hi Pierluigi how are you hope youre fine
As i am a data engineer i am confronted to these bot managers i am specialised in retailers websites i was confronted months ago to akamai in the website of american retailer Kroger , the token expires after like 3 requests and the tokens created by headless gives partial results , and i found that this is intentional i made some tests to deobusfucate the challenge to understand it but no way it will take an eternity, please if you can take a look to this retailer website if you need any informations from my previous experience with feel free to contact me at nab3945@live.fr