
Browser fingerprinting and web scraping
What are fingerprints and how they can be modified, even with proxies

July is the Smartproxy month on The Web Scraping Club. For the whole month, following this link, you can use the discount code SPECIALCLUB and get a massive 50% off on any proxy and scraper subscription.

We’ve already seen in the past articles how fingerprints are created, using data read from the browser’s API and the various network layers.
To be honest, this is a rabbit hole and I still didn’t enter it but here are some resources if you wish to anticipate me:
CreepJS GitHub repository, where you can find some details about the famous fingerprint test created by AbrahamJuliot
Always in his GitHub profile, you can find a list of studies and papers about fingerprinting techniques
FingerprintJS repository, the Fingerprint.com repository, where you can understand better the information retrieved by the tool.

But why it is so important for web scraping?
Anti-bot softwares use fingerprinting techniques to detect the hardware and software configuration used by scraper using webdrivers or browser automation tools.
In fact, scrapers made with Scrapy or similar tools are already getting blocked by them since they fail the first challenges thrown. But to detect more advanced bots, you need to understand better their environment and behavior and compare them with a list of human-like setups. If the scraper has a plausible fingerprint, it’s not detected as a bot and can continue scraping the website.
Privacy concerns
The client IP and all the derivate information that can be deducted from it are surely a part of the anti-bot strategy but they have little impact on a fingerprint. In fact, fingerprints are made, like cookies, with the intent to track users (or better, their devices) and generate a unique id, independently from where they are connecting.
This raises, of course, privacy concerns: nowadays every website requests explicit consent for using cookies after the legislation made its progress in this field. As a result, we have a worse navigation experience, with hundreds of pop-ups everywhere, but also more awareness by the masses about cookies in general.
And with more awareness, also companies that base their revenues on targeted advertising like Google, need to adapt and are moving away from this technology.
With fingerprinting, now, we’re at the same point where we were at the beginning of the cookie era: there’s not a general awareness of what is it and basically, we cannot decide to opt out of being tracked, unless we use some less knows solutions which sometimes are not compatible with websites we’re visiting.
In fact, most of the information included in a fingerprint comes directly from our browser and IP address, so unless we use a more privacy-oriented browser that gives away less data to the websites, at the risk of breaking something, we don’t have many other options.
If telling the web servers which operating system you’re using for browsing doesn’t seem a huge threat to your privacy, have a look at this study from some years ago about the Battery API available on most browsers until not so long ago. Since it returned the estimated time in seconds that the battery will take to fully discharge, as well the remaining battery capacity expressed as a percentage, the different combinations of these two numbers are 14 Million. If you sum up hundreds of these values, you can understand how fine-grained can be a browser fingerprint nowadays. If all the possible combinations of these parameters are in the order of billions, tracking a single user across the web it’s not that impossible.
The role of fingerprinting in web scraping
Of course, what can be used for tracking humans, can be used also to distinguish humans from bots. An example explains the situation better than one thousand words. Try to open a website heavily protected by Cloudflare like harrods.com, first on your computer and then from a browser opened on a virtual machine hosted on a cloud provider.
You should be able to do this in both cases since you’re a human, but what usually happens in the second case?
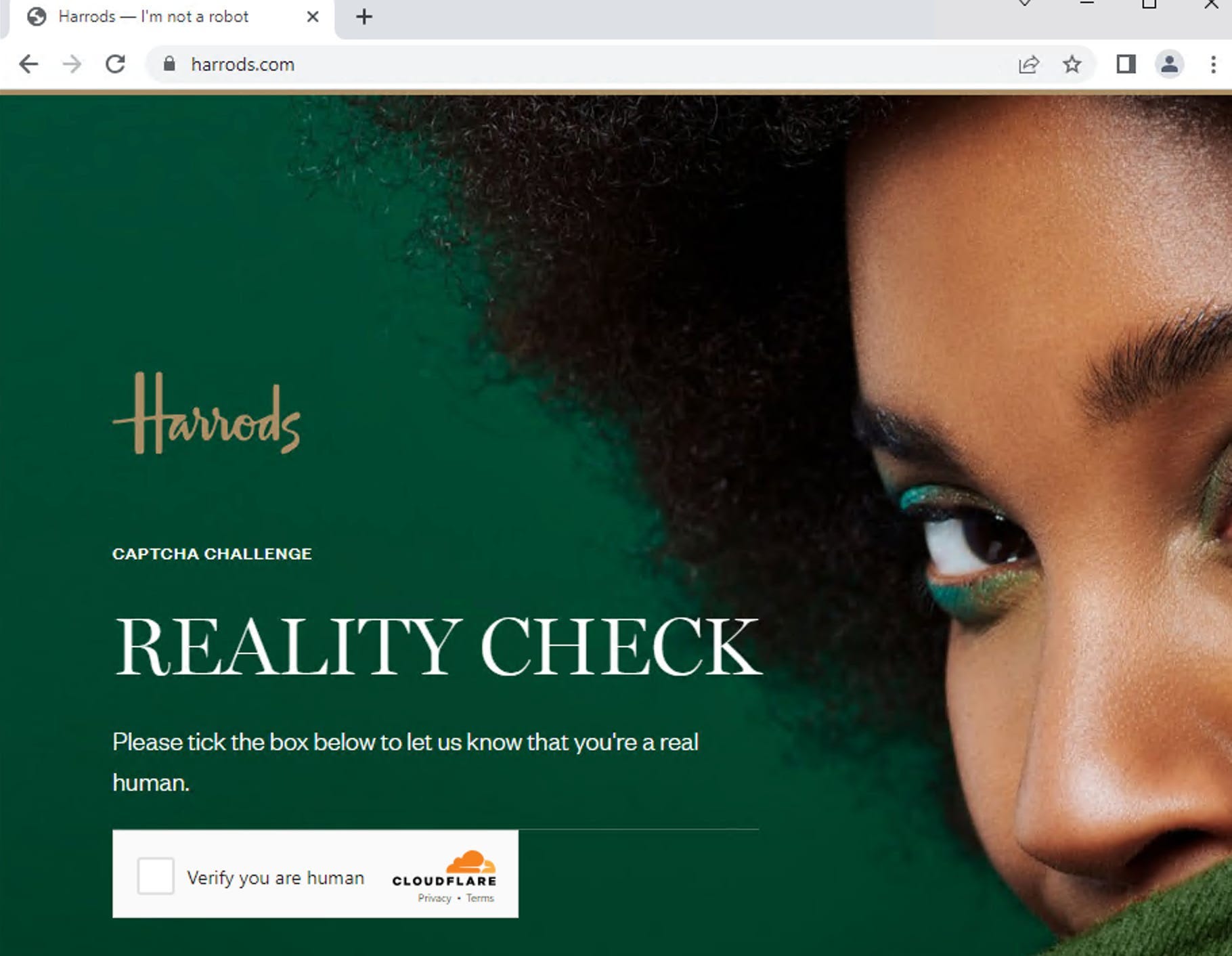
You need to convince the website you’re a human. What happened? Using several pieces of information combined, like the ones described in this post, Cloudflare detected that the traffic was coming from a virtual machine. People usually don’t browse from data centers and virtual machines, while bots do. So the mix of IP-related information and browser parameters raised some red flags for Cloudflare, which decided to throw the challenge in the first place.
In this particular case, using a Smartproxy residential proxy, I could bypass the Cloudflare challenge when browsing. This means that in this configuration, the weight of the IP-related data is more relevant than the one coming from the hardware environment.
Altering the fingerprints
Luckily for web scraping professionals, as soon as fingerprinting has become an issue, several types of solutions were created.
Scraping APIs, like the Smartproxy website unblocker, are one of them. They manage internally the best fingerprint to show to the target website, fooling the anti-bot defenses.
Another solution to the fingerprinting issue is to use anti-detect browsers or AI-powered browsers, which can be configured to alter their final fingerprint.
I find this theme fascinating, so expect soon an in-depth post about fingerprinting techniques and how to mask the one of your scrapers.