
HTTP requests in Python explained
A basic introduction on how make HTTP requests with different python tools

What is an HTTP request?
If you’re reading this newsletter, I’m sure you already know all the stuff I’m going to explain but let’s make a brief introduction in case someone is approaching web scraping for the first time.
HTTP requests are one of the founding stones of the HTTP protocol and basically, it’s the call a client/browser makes to a server. The outcome of the request is the server response, which contains the content placed at the URL passed in the request.
A request is composed by:
Method
Url
Headers
Body
Method
Each request can have only one method between the ones listed in the HTTP Protocol. The most important ones are:
GET: to retrieve data from a url
POST: to modify data on a server
PUT: to substitute data on a server
DELETE: to delete data on a server
Basically, in our web scraping projects when we need to read data from a server we’ll use several GET requests, while if we need to send data to an API to query it or to fill a form, we’ll use POST requests.
Url
Needless to say, it’s the target URL for our request. Can contain a query string and one or more couples of keys and values. In this example
https://news.ycombinator.com/?p=2
the query string starts after the question mark and we have p as a key and 2 as its value.
Headers
Here’s the most important part of the request for our web scraping projects.
They are basically couples of keys and values and each request can have many headers. The most known keys are User Agent (where the client auto declares its identity), cookies, and Accept-Encoding (where the client tells the format of data it expects from the server, like JSON as an example).
Headers are also used for authenticating access to the API, with the usage of tokens that may vary from the tech stack. Also, anti-bot software use headers to pass their “OK to go” to the server once they verified the client is not a bot.
Body
They are used in POST method to pass data to the server.
Analyzing the requests
Now we have seen the theory, we can proceed with the practice. Until some years ago, when anti-bot systems were much less sophisticated and most of websites used only some generic rules on user agents to block bots, it was enough to modify some values to bypass any block.
Now avoiding blocks is much more complex but keeping the request headers “in order” and coherent with a standard installation of a browser is the first step to take.
Using a website called
https://webhook.site/
we’ll see what servers receive when we make requests using the most common python tools, starting from python-requests, to Scrapy and Playwright.
The script used in this post is available on the GitHub repository and open to free readers.
Python request
The first request is made with the Python Requests module, using default settings without any change in headers.
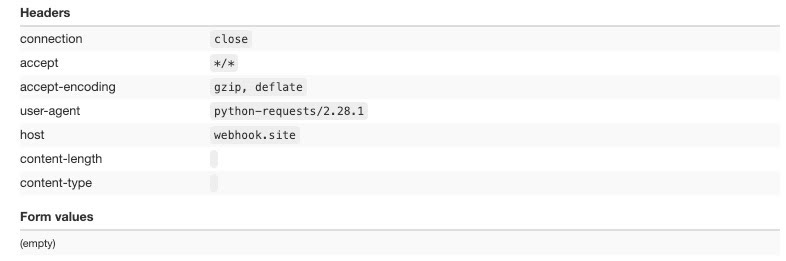
The headers are limited in number and the request is clearly coming from a bot since the python-request user agent is being used.
Plain Scrapy request
The second test is made by using Scrapy, without DEFAULT_REQUEST_HEADERS and USER_AGENT options set.
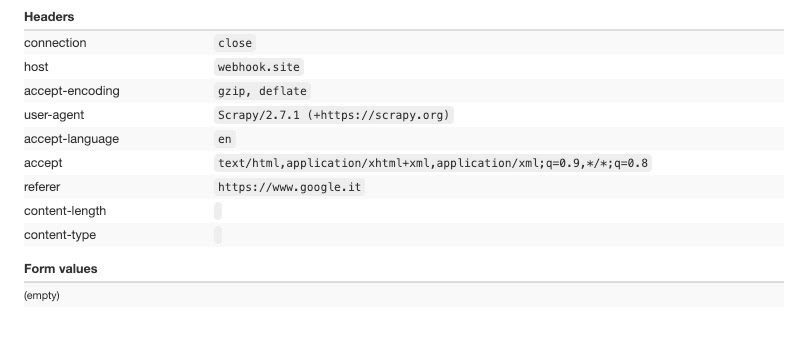
The user agent is set with Scrapy’s default value (here’s the list of all the default values of Scrapy settings) while we can notice the Cookie handling: since the first page we crawl in this example is google.it, we find it in the referer headers, since it’s the previous page we’ve visited before taking this test.
Scrapy with custom headers set
Of course, for both python requests and Scrapy we can set custom headers to be passed. In this third example we can see a request made with Scrapy with a custom set of headers.
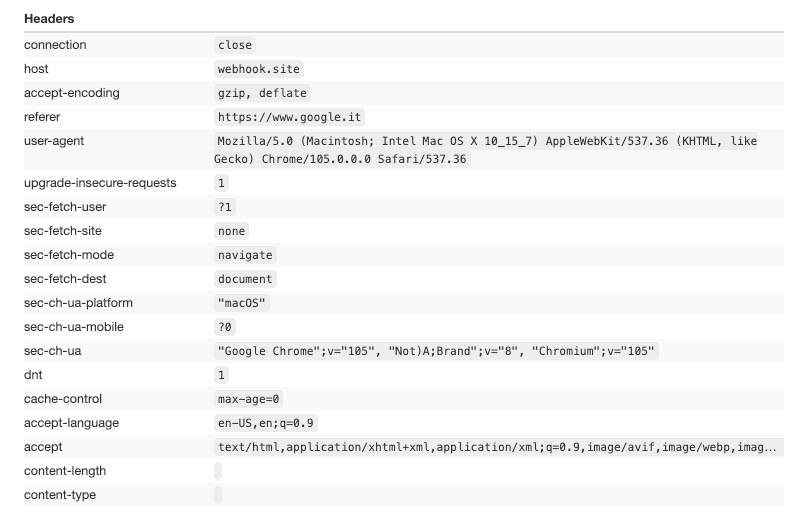
Of course, it has the results we expected.
Playwright with bundled Firefox
For this test we’re going to use the Firefox’s browser that comes inside the Playwright installation, with no other setting or package installed.
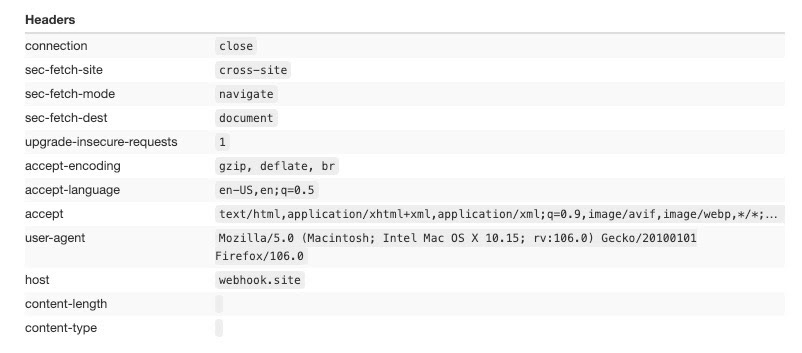
Now the headers start to look like a real connection from a user.
Playwright with bundled Chromium
Let’s repeat the test but using the Chromium bundled with the installation, always with no other setting or package installed.
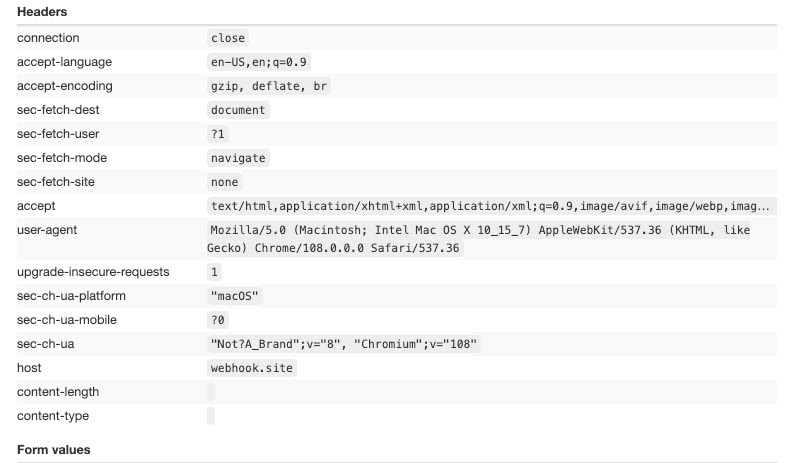
Of course, the User Agent changes but also the number and the order of the keys are different, and both are factors that anti-bot solutions to check if a connection is genuine or not.
Playwright with bundled Chromium and Stealth Plugin
Now we add the playwrigh_stealth plugin to see if something changes in our headers.
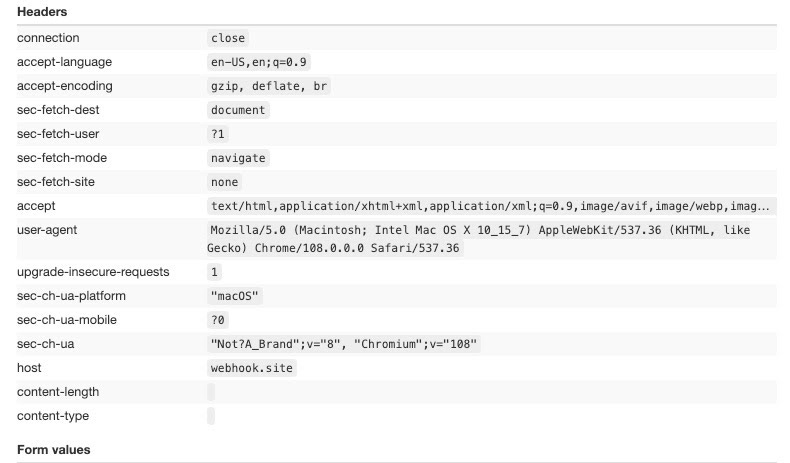
No, it does not change anything, and the reason is that this package works on other browser attributes, like the window.navigator ones. As soon as I find out a good tool to visualize these settings, I will make a similar post focused on them.
Playwright with Chrome standard installation
Last but not least, we’re testing a standard Chrome installation with Playwright.
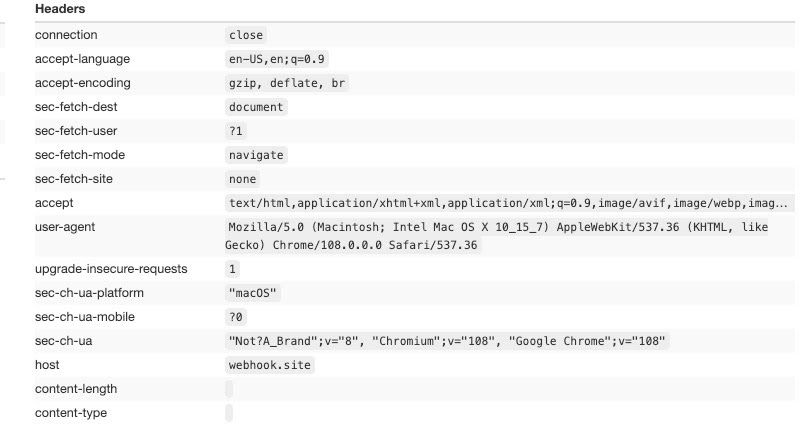
It looks very similar to Chromium, if not for the sec-ch-ua value. This is the User Agent Client Hint and it is used by some browsers to share more details on the browser version.
It is categorized as a Low Entropy Hint since, like sec-ua-mobile or sec-ua-platform, gives away a piece of information that is not enough to create a fingerprint of the user (on contrary to High Entropy Hints).
Final Remarks
In this post, we have seen how the different tools we use generate the request headers.
Despite the fact a request properly set is not usually enough for deceiving an anti-bot, for sure it’s a must-have for our scrapers.
We have seen also the concept of Client Hints and how Low Entropy Hints differentiate from High Entropy ones by the sensitivity of the information they share with the server.