
Web Scraping from 0 to hero: tips and tricks for Microsoft Playwright
Playwright's features useful for web scraping

Welcome back for a new episode of “Web Scraping from 0 to Hero”, our biweekly free web scraping course provided by The Web Scraping Club.
In the latest article, we created a plain vanilla scraper with Microsoft Playwright and today we’ll see some cool features of this browser automation tool that we can use in your web scraping projects.

How the course works
The course is and will be always free. As always, I’m here to share and not to make you buy something. If you want to say “thank you”, consider subscribing to this substack with a paid plan. It’s not mandatory but appreciated, and you’ll get access to the whole “The LAB” articles archive, with 30+ practical articles on more complex topics and its code repository.
We’ll see free-to-use packages and solutions and if there will be some commercial ones, it’s because they are solutions that I’ve already tested and solve issues I cannot do in other ways.
At first, I imagined this course being a monthly issue but as I was writing down the table of content, I realized it would take years to complete writing it. So probably it will have a bi-weekly frequency, filling the gaps in the publishing plan without taking too much space at the expense of more in-depth articles.
The collection of articles can be found using the tag WSF0TH and there will be a section on the main substack page.
BrowserContext: when does it need to be persistent?
In our example in the previous article, we started our Playwright scraper with the following instructions:
with sync_playwright() as p:
browser = p.chromium.launch(channel='chrome', headless=False,slow_mo=200)
page = browser.new_page()
page.goto('https://www.valentino.com/en-gb/', timeout=0)We basically started a sync session of Playwright and opened a Chrome window with a page in incognito mode.
This sequence of commands is a shortcut, since what we’ve done is open a browser, start a BrowserContext and, within this context, open a page to use for browsing.
In Microsoft Playwright, a BrowserContext is an abstraction that represents an independent session of browser activity, similar to an incognito session in a traditional web browser. Each BrowserContext can have its own set of cookies, local storage data, and session storage data, which means that activities performed in one context do not affect or interfere with those in another, providing a clean slate for each test or automation task.
The primary advantage of using BrowserContexts is their ability to simulate multiple users interacting with a web application simultaneously, without the need for multiple browsers to be opened and managed. Additionally, BrowserContexts allow for custom configurations, such as viewport size, geolocation, language, and permissions, enabling us to configure our scrapers differently from one context to another.
Sometimes, browsing in incognito mode could be seen as a red flag from the target website, so what we should do? Luckily, we have the Persistent Context option.
A Persistent Context is a specialized type of BrowserContext that Playwright offers, designed to mimic the behavior of a regular (non-incognito) browser session. Unlike standard BrowserContexts that are ephemeral and lose their data once the session ends, a Persistent Context retains its data across sessions. This means cookies, local storage, and session storage persist even after the browser is closed, saved on a folder on your hard disk.
This allows scenarios such as testing the login sessions that need to remain active across browser restarts or cookie usage in different runs of the scraper.
The key difference between a standard BrowserContext and a Persistent Context lies in their data persistence behavior. While standard BrowserContexts are ideal for isolated, stateless testing scenarios requiring a fresh environment, Persistent Contexts are more useful for scrapers that require data continuity and state persistence across browser sessions.
Which browser can I use with Playwright?
Microsoft Playwright natively supports a variety of browsers, giving scraping professionals a good array of opportunities. The browsers supported and bundled with the installation are Chromium, Firefox, and WebKit, which cover a broad spectrum of user experiences, including those similar to Google Chrome, Mozilla Firefox, and Apple's Safari.
Switching between these browsers in Playwright is straightforward, thanks to its unified API.
To switch browsers, developers simply instantiate a new browser object with the desired browser type. In fact, we can use the following commands to launch a Chromium, Firefox or Webkit browser:
playwright.chromium.launch()
playwright.firefox.launch()
playwright.webkit.launch()But that’s not over: if we want to launch a Chrome browser instead of a Chromium, we can rely on the channel parameter in the launch function, just like we did in the previous post example.
browser = p.chromium.launch(channel='chrome', headless=False,slow_mo=200)According to the Playwright's documentation, it stands for the
Browser distribution channel. Supported values are "chrome", "chrome-beta", "chrome-dev", "chrome-canary", "msedge", "msedge-beta", "msedge-dev", "msedge-canary".
All these values are needed mostly by web developers who need to test their apps on a multitude of browser versions, but for web scraping, the ones that matter most are chrome and msedge, which launch an instance of Chrome and Edge browsers.
Last but not least, you can still launch all the Chromium-based browsers installed on your machine by declaring their path for the executable file in the executablePath parameter:
browser = p.chromium.launch_persistent_context(
user_data_dir='./userdata',
channel='chrome',
executable_path='/Applications/Brave Browser.app/Contents/MacOS/Brave Browser')
With this instruction, we’re creating a persistent context by launching a session of Brave browser on our machine.
Connection with CDP: using a browser on a remote machine
Microsoft Playwright integrates with the Chrome DevTools Protocol (CDP) to offer advanced control and automation capabilities, particularly for Chromium-based browsers. CDP is a powerful interface that allows for deep interaction with the browser, enabling tasks such as manipulating network conditions, capturing console logs, and directly interacting with the Document Object Model (DOM). We have seen this option in some of the past articles of The Lab, where we used it to connect to anti-detect browsers installed on a different machine or using a different port on the same one.
To utilize CDP within Playwright, developers can establish a connection to a browser context's underlying Chromium instance. This is accomplished by accessing the CDP session associated with either a page or the entire browser context. Once connected, developers can send commands and listen to events directly through the CDP, allowing for fine-grained control over the browser's behavior and inspection capabilities. Here is the command to use:
with sync_playwright() as p:
SBR_WS_CDP = 'ws://SERVERIP:PORT'
browser = p.chromium.connect_over_cdp(endpoint_url=SBR_WS_CDP)This direct connection to CDP is particularly useful for controlling remote browsers. By running a Chromium-based browser in a server environment and connecting to it via Playwright's CDP integration, developers can remotely execute the scrapers.
Changing default arguments in Playwright
To check if our scraper looks like a real browser we usually test them on different pages that check some key browser’s attributes. One of the most famous is the Sannysoft test, which raises some red flags if we load it with a standard chromium setup.
with sync_playwright() as p:
browser = p.chromium.launch(headless=False,slow_mo=200)
page = browser.new_page()
page.goto('https://bot.sannysoft.com/', timeout=0)
The WebDriver value is a browser’s property that when set to True, like in this case, indicates whether the user agent is controlled by automation.
This can be fixed by passing a parameter to Chrome
CHROMIUM_ARGS= [
'--disable-blink-features=AutomationControlled',
]
with sync_playwright() as p:
browser = p.chromium.launch(headless=False,slow_mo=200, args=CHROMIUM_ARGS)
Since we need to impersonate a real human browsing with our scraper, it’s better to use a real instance of Chrome instead of Chromium, but after setting the channel property to the command, we have another issue.
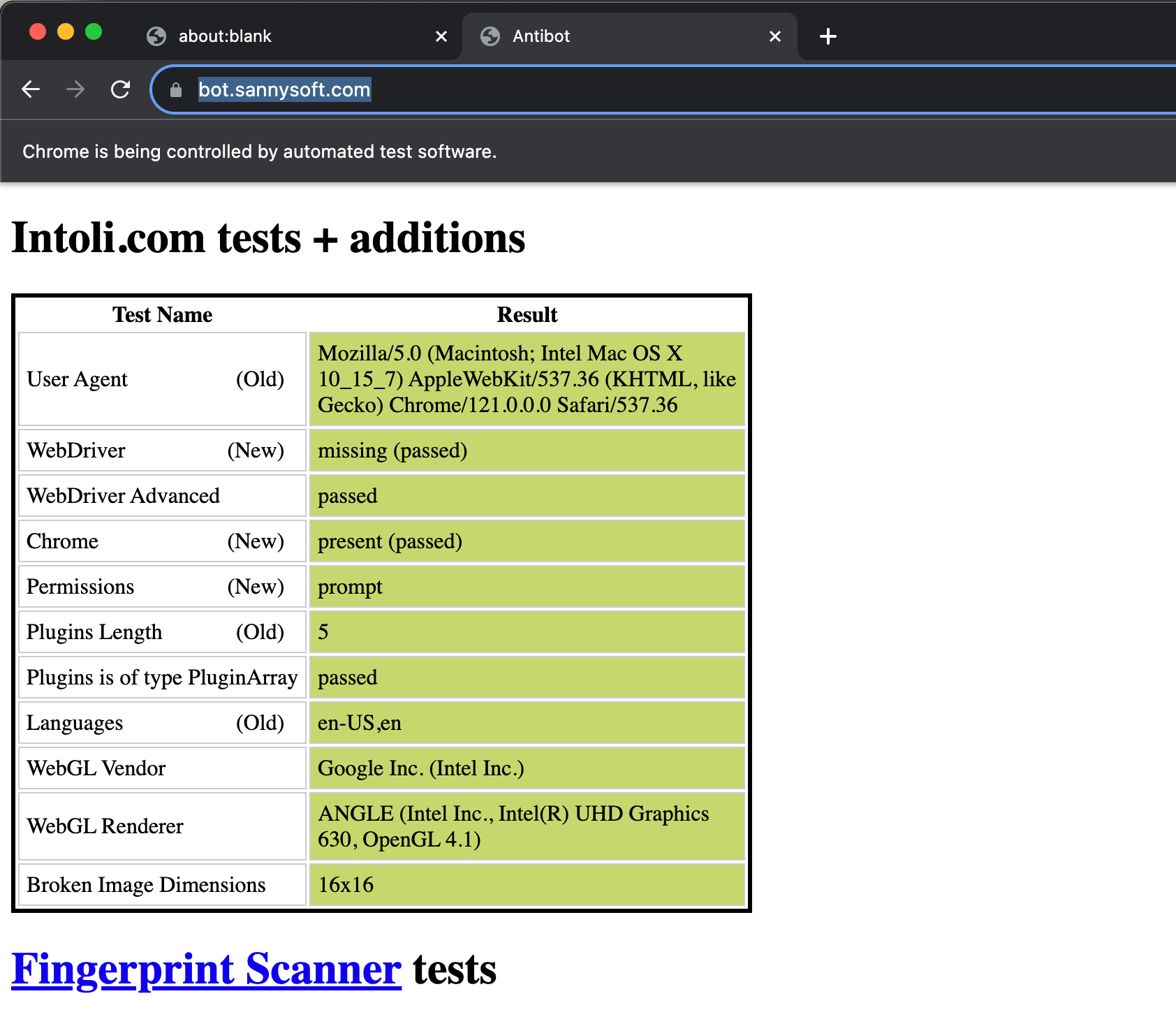
This upper banner that says Chrome is being controlled by an automated test software and of course, we don’t want it when creating our scraper.
CHROMIUM_ARGS= [
'--disable-blink-features=AutomationControlled',
]
with sync_playwright() as p:
#browser = p.chromium.launch(headless=False,slow_mo=200)
browser = p.chromium.launch_persistent_context(user_data_dir='./userdata/',channel='chrome', headless=False,slow_mo=200, args=CHROMIUM_ARGS,ignore_default_args=["--enable-automation"])
page = browser.new_page()We added the ignore_default_args=["--enable-automation"] to disable the enable-automation switch and restore the traditional behavior.
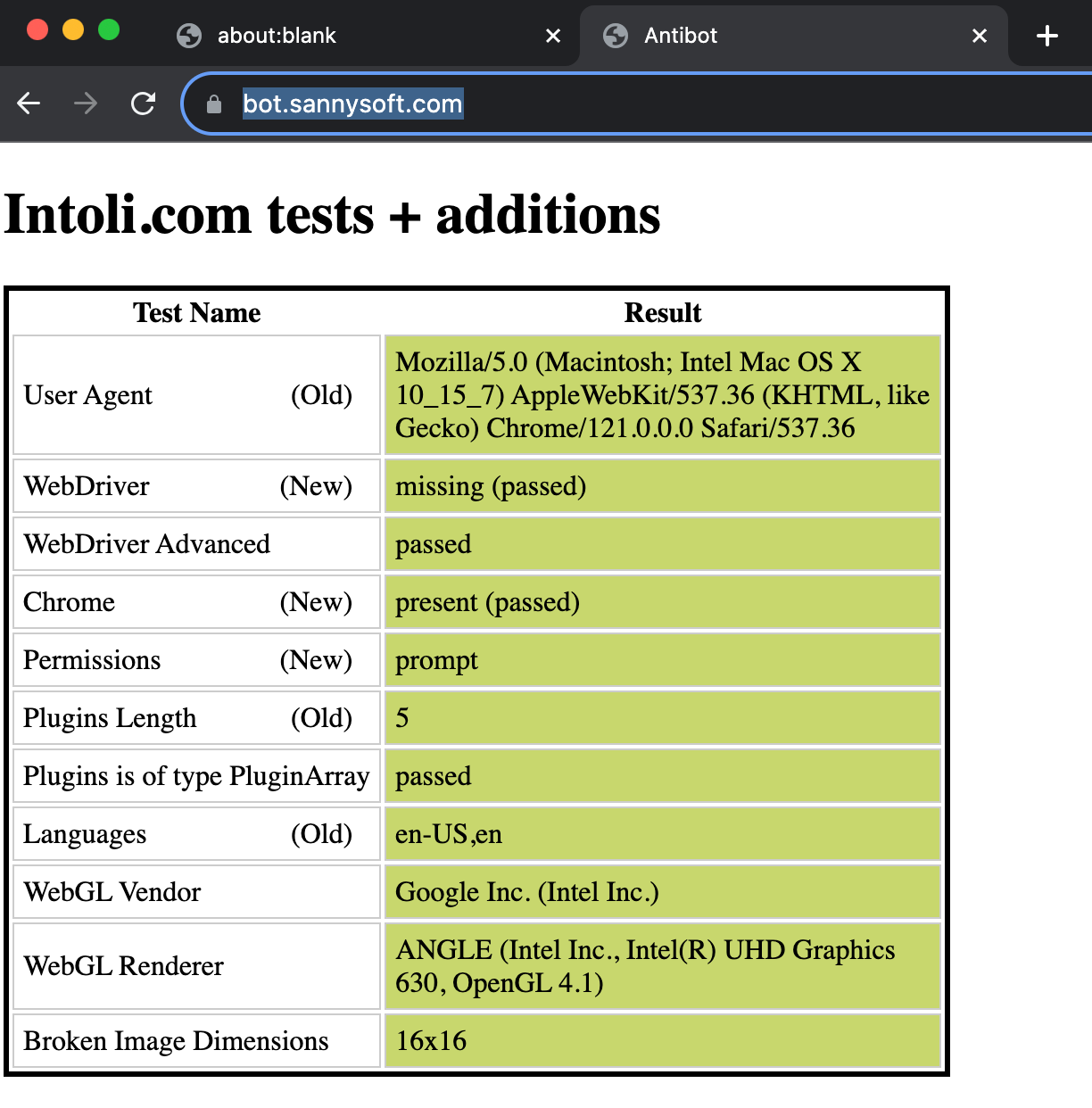
Here we have the final spider setup.
CHROMIUM_ARGS= [
'--disable-blink-features=AutomationControlled',
]
with sync_playwright() as p:
#browser = p.chromium.launch(headless=False,slow_mo=200)
browser = p.chromium.launch_persistent_context(user_data_dir='./userdata/',channel='chrome', headless=False, args=CHROMIUM_ARGS,ignore_default_args=["--enable-automation"])
page = browser.new_page()
page.goto('https://bot.sannysoft.com/', timeout=0)
time.sleep(10)
page.close()
browser.close()
This is a basic setup for a scraper, more options are used to avoid undesired behaviors, as you can see in the code of The Lab posts, where we often use Playwright to bypass the most tough antibot.
In the next post of “Web Scraping From 0 to Hero”, we’ll take a step back and see the main components needed for a modern web scraping infrastructure and make a deep dive into some of them.