
The Lab #57: Improving your Playwright scraper and avoid CDP detection
How to use the latest advancements to avoid CDP detection in your Playwright scrapers

Your Playwright/Puppeteer/Selenium scraper that you created some time ago and helped you bypass the target’s antibot has stopped working in the past months, after the release of the new antibot version. Sounds familiar?
Well, from what I’ve perceived from The Web Scraping Club community, especially in the Discord server, this has been a common issue, especially when targeting Cloudflare and Akamai-protected websites (but I don’t have any data to share, only gut feeling).
It’s not something uncommon: every time a new version of an anti-bot is released, there’s the chance that it will break our scrapers. It’s their job to aim at any red flag and hunt the bots down!
One of the latest techniques used by anti-bots is described in this post on the Datadome blog and it’s about the detection of the CDP (Chrome Developer Protocol) usage when sending commands from a browser automation suite to the browser itself.
As mentioned in the article:
The Chrome DevTools Protocol (CDP) is a set of APIs and tools that enables developers to interact programmatically with Chromium-based browsers. It allows for debugging, profiling, and inspecting web applications by providing access to the browser’s internals. CDP is also the underlying protocol used by the main bot frameworks—such as Puppeteer, Playwright, and Selenium—to instrument Chromium-based browsers. Thus, being able to detect that a browser is instrumented with CDP is key to detect most modern bot frameworks.
CDP detection targets the underlying technology used for automation rather than specific inconsistencies and side effects added by a particular bot framework. This provides us a more generic fingerprinting detection, even for unknown automation frameworks—including the ones that try to stay under the radar by providing anti-detect features.
This detection technique is quite ubiquitous nowadays and it has been integrated into most of the well-known testing websites like BrowserScan.
A quick test to find out if the test page you’re using is aware of this technique is to open its page with your browser (you should receive a green light), then open the dev tools and reload the page. If the test changes its results, saying you’re a bot, it means that the page is updated.
This is what happens in BrowserScan when the page is opened with no dev tools.

and then with the dev tools open.
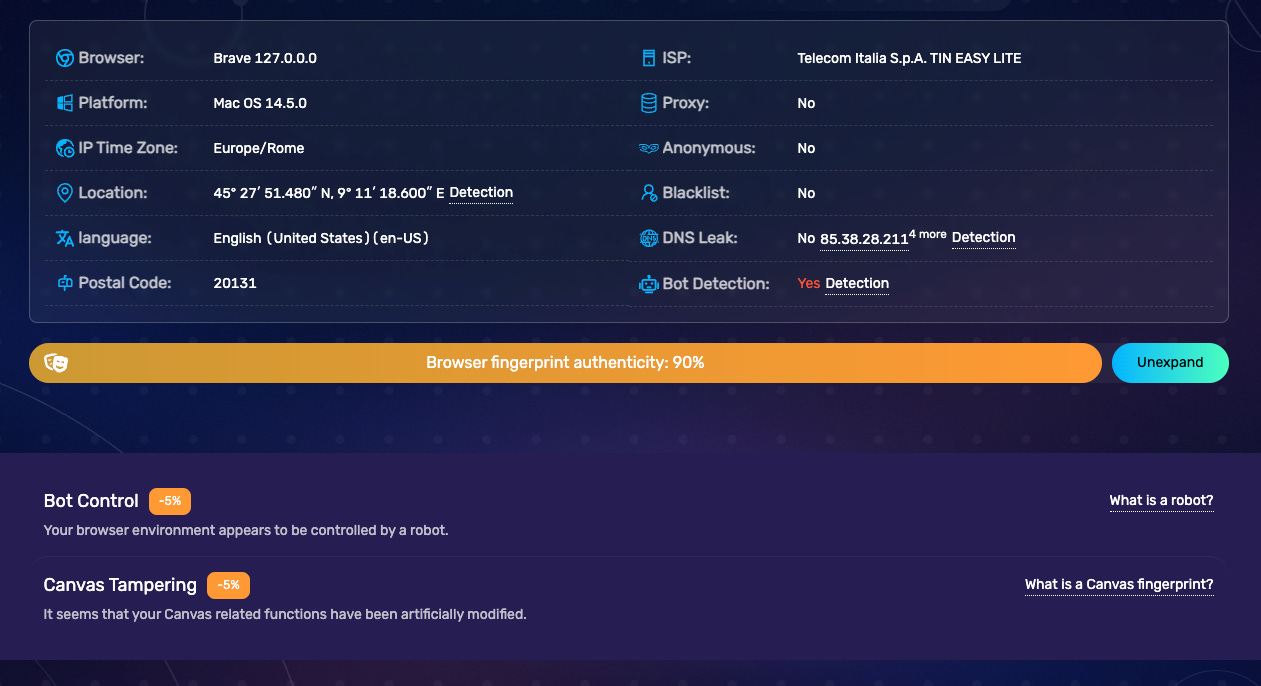
When opening the page with a standard Playwright installation, we got the same result.

How to mitigate CDP detection in your Playwright Bot
As Antoine explained in the Datadome post, this detection technique looks for signals in the underlying protocol used by the main browser automation tools like Playwright, Puppeteer, and Selenium.
This means that switching browsers or using an anti-detect one doesn’t change the situation, since they are all controlled by the Chrome Developer Protocol.
What should be fixed is the Playwright library itself so that it doesn’t send the “Runtime.enable” command.
As suggested in the article, some libraries like Nodriver are already providing natively this solution (unluckily I still cannot test it since I’m stuck on a dependencies loophole on my Mac).
But how can we migrate our Playwright scraper to a more “undetected version” without rewriting it totally?
As always, if you want to have a look at the code, you can access the GitHub repository, available for paying readers. You can find this example inside the folder 57.UNDETECTED-CHROMEDRIVER
If you’re one of them but don’t have access to it, please write me at pier@thewebscraping.club to get it.
Let’s see how to implement a library that, with the minimum effort, can make our scraper pass this CDP test.
