The Hacker News community went crazy about this topic
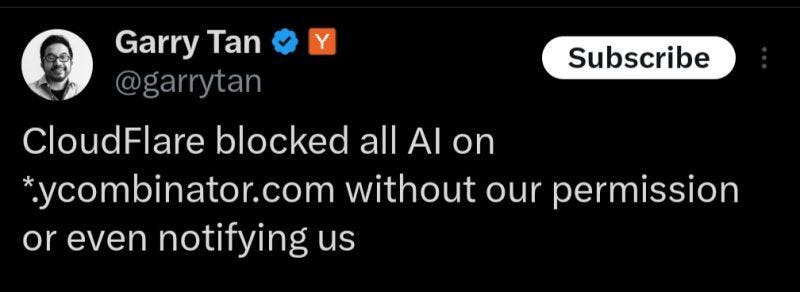
And even Garry Tan, the CEO of YCombinator, shared that Cloudflare blocked all AI crawlers on the YCombinator website domain, without even noticing them.
Despite all the buzz around this news, it seems to me that the discussion is just scratching the surface of the implications and mechanics of the AI companies scraping the web.
Before proceeding, let me thank Decodo, the platinum partner of the month. They are currently running a 50% off promo on our residential proxies using the code RESI50.
LLMs and scraping: the struggle (for website owners) is real
We have mentioned previously on these pages that this is the first time in history that we have companies with such budgets to spend on scraping. This means operations are in place at a scale never seen before, with companies extracting data from a large variety of websites, from the most famous to niche ones, sometimes without worrying too much about best practices.
This has a cost for both sides, but with a substantial difference: while AI companies are well funded, website owners need to pay more for the infrastructure to run them.
The pain is real, and in most cases, the downsides are not relieved by the visibility in these AI answers. If your piece of content, available on your website, is chewed and summarized in a ChatGPT answer that satisfies the needs of the prompting human, you won’t see the same human on your website, even if you rank #1 on Google.
Just like when you look to buy a specific product you have in mind, you go to the Amazon website instead of googling it, it’s happening that more and more people (me included) use LLMs when they’re looking for some information, especially the less important ones.
Using ChatGPT (“and friends”) today is like having the Amazon of human knowledge: you always get an answer, although it may not always be the right one.
This raises more than a concern for businesses based on ads displayed on their website: how can my “bike repair” online guide still be relevant if the same information can be found on ChatGPT without visiting my website?
That’s why the Pay-for-Crawl seems a good idea, at least in theory.
This episode is brought to you by our Gold Partners. Be sure to have a look at the Club Deals page to discover their generous offers available for the TWSC readers.
Let’s suppose, for simplicity, that the pay for crawl becomes the industry standard and every AI company adheres to that, for a symbolic price of 1 USD per request.
Let’s continue with our example of the “bike repair” guide website: it has 1000 articles published, so every full scan of the website by an AI company will cost 1000 USD. Let’s say that five companies are doing that, four times a year, so that the owner could theoretically put in his pockets 20k per year. Not bad, at least in theory.
The first fallacy of this example is the price per request: we don’t have official numbers, but we can estimate how many pages a year these AI companies scrape. During a trial, a Google VP said that the Google Index contained around 400 billion entries in 2020. I think we can assume that the amount of scraping done by AI companies is in the range of 100 billion requests per year, which makes the price of 1 USD per request unbelievable. It should probably be divided by 100 or, more likely, by 1000.
In the latest case, even if the whole website is scraped entirely on a daily basis by the hypothetical five actors, the fees to the pockets of the owner would be
\(5 * 1000 * 365 * 0.001 = 1825 USD\)
for a year. Not a great amount, considering that you should install Cloudflare also on your website (and probably pay for it), or consider the cut that it would take on the sum, together with Stripe, which seems to be the platform that Cloudflare is using to collect money in its beta test.
Before continuing with the article, I wanted to let you know that I've started my community in Circle. It’s a place where we can share our experiences and knowledge, and it’s included in your subscription. Enter the TWSC community at this link.
The second fallacy is that we’re supposing that every AI company would be happy to pay for being allowed to scrape. This technically means that an AI company should adhere to the project and, doing some math, should find it more convenient to scrape being in Cloudflare’s “whitelist” rather than scraping on its own.
Let’s suppose, just for fun, that today, an AI company is using the Bright Data Unblocker API for scraping our bike repair website. Of course, it has the best plan possible, which could be even lower than the $1 for 1k requests, as shown on their website. Why should this company pay the same amount for scraping this website, facing also possible limitations from the target website, while it could scrape it autonomously?
To be attractive to AI companies, the price to pay should be so low that it won’t be convenient for the website owners.
The idea behind the Pay per Crawl is not to trash. I agree that, even if the data is public, websites should gain something for sharing it (or, at least, not being damaged by the scraping operations).
This is a principle behind Databoutique.com: if someone scrapes a website, this can be shared and sold to the scraping community so that fewer people have to scrape the same website for obtaining the same data. Even better: websites themselves could sell datasets on the platform, reducing the need for web scraping and monetizing their public data.
This model has its limits, and we're far from reaching the full potential of the platform, but we firmly believe that this is a much healthier approach than today’s far west.
Made by AI companies or not, the first step for measuring how much of the traffic on your website is made by bots is detecting them. And about this topic, I’ve read something that made me laugh hard.
From the Clouflare Blog, Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives. Cloudflare created a couple of brand new domains that should not be crawled by Perplexity, given the robots.txt and Cloudflare Bot Detection setup. Instead, it was, since they’re using undeclared user agents and IPs from different ASNs. This is not surprising at all: from a user perspective, it can be frustrating asking for some information about a website and being told that, due to robots.txt limitations, the model is not able to retrieve data.
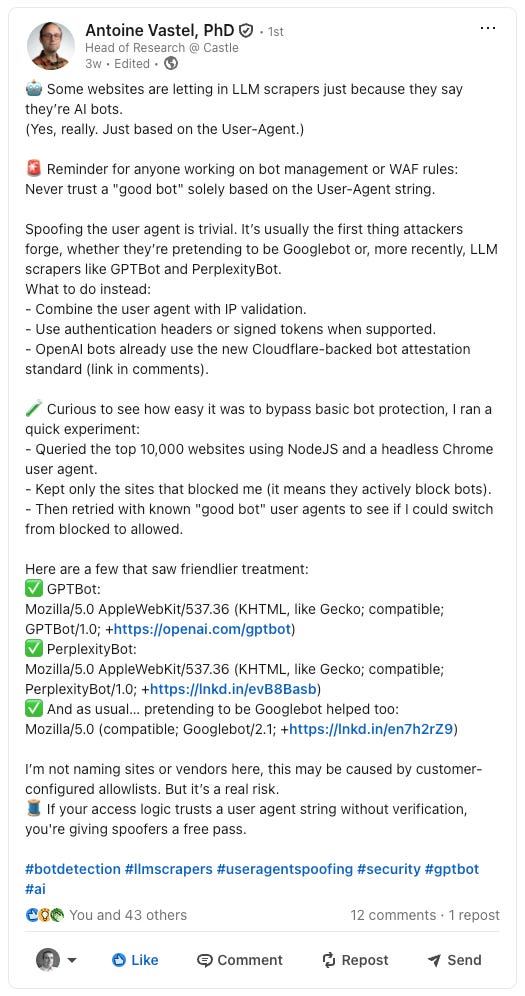
Some websites are so desperately trying to intercept traffic generated by LLMs that are whitelisting their User Agents for scraping them (just like it happened with Googlebot a while ago).
Of course, if you’re reading these pages, you know how easy it is to change the user agent of a request, so allowing a specific one without verifying other parameters like IPs is just like leaving the keys in the front door lock.
The Web Scraping Club is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Conclusion on The Web Scraping Club
During a summer holiday three years ago, the Web Scraping club came to light.
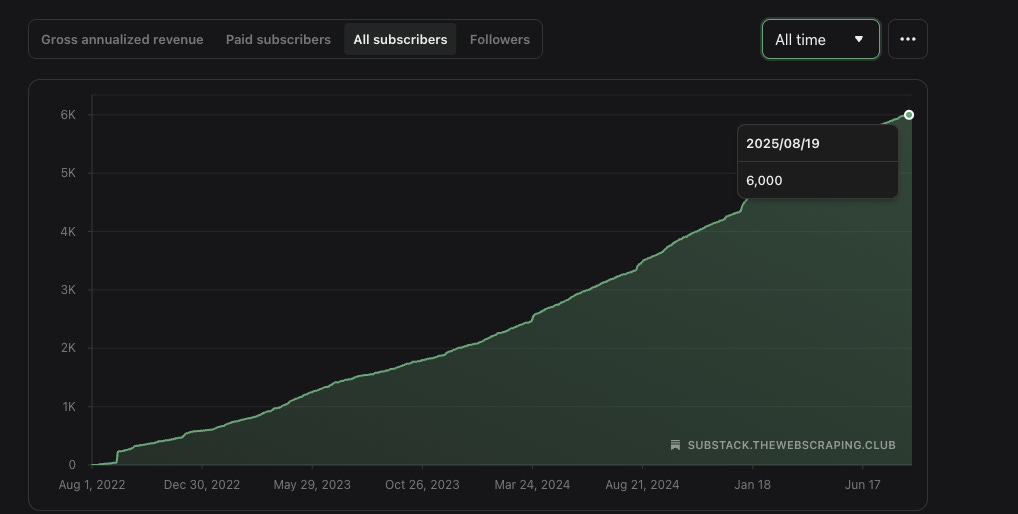
Today, we’re a community of more than 6000 readers, almost doubled during the last year (on the same day, the previous year we were 3460, +73% YoY).
This is a fantastic journey, and I wanted to thank all of you. I’ve always had something in mind for bringing more value to the community, some experiments are on hold (like the Circle community), but I’m working on something huge that I hope will see the light before the end of September. A big thank you also to Antonello Zanini and Federico Trotta, that are helping me in improving this project by providing new points of view and experiences in it.
Last but not least, I'm proud to share that on October 1st, I'll be at the Oxycon with my talk "How AI Reshaped My Workflow as a Scraper Developer and Content Creator"
I'll share with you how LLMs and AI in particular changed my workflows both as a content creator, but mainly as a scraping professional, speeding up the whole process of extracting data from the web.