
No-Code Web Scraping with Make.com
A step by step guide for effortlessly creating a web data pipeline

During my career in web scraping and especially in the past 2 years spent writing The Web Scraping Club, I had the opportunity to talk daily with people involved in the industry.
While companies are eager to acquire more and more web data, plenty of professionals are willing to automate their recurring tasks by acquiring web data for different types of analysis. And most importantly, many of them are non-technical people, like marketers, sales, or managers. They want to build a data pipeline that extracts web data and delivers it to the tool they’re more familiar with.
To satisfy these needs, many no-code web scraping solutions have been released on the market in the past years, even thanks to the LLMs boom.
In today’s article, we’re seeing how to create a web data pipeline that, starting from a website, delivers web scraped data to a CSV file on an AWS S3 bucket. To do so, we’ll use Make.com automation software, that allows users to connect to hundreds of different systems and softwares with just some clicks.
The idea is to read a website’s sitemap, extract all the product pages, parse them with ChatGPT to get structured data in output, then create a CSV and upload it on S3.
Let’s see what are the steps we need to take.
Prerequisites for Web Scraping with Make.com
Before embarking on this journey, make sure you have an AWS account for storage, and a Make.com account to create the data pipeline. We’ll also need an OpenAI API Key, for parsing the data from the product page.
Setting Up the Scenario on Make.com
To initiate the web scraping process, log in to your Make.com account and create a new scenario. A scenario is the foundation for your workflow, and it’s composed of different nodes, each one related to a specific task.
In this picture, you’re seeing the final shape of the scenario we’re going to build in this post.

Getting the sitemap.xml
The first node is an HTTP one, that enables us to create a basic HTTP request and save a file in output.

For this example, we decided to scrape some information from product pages from the Moscot.com website, an eyewear brand.
Once understood what’s the correct sitemap file containing the URLs of the product pages, it’s enough to put its URL in the proper field inside the node.
Extracting URLs from the Sitemap and iteration
After downloading the sitemap.xml, we need to parse the file with the specific XML parse node.
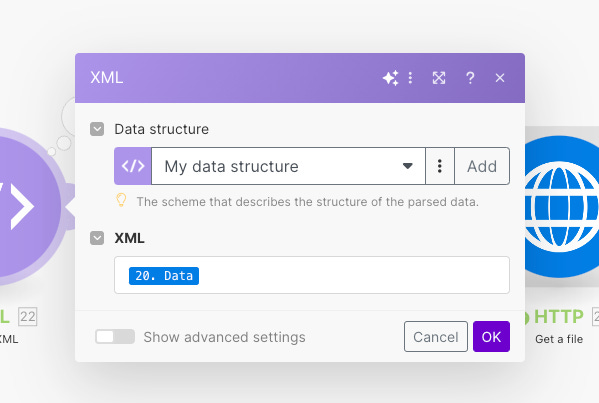
Then, we add an iterator module to your scenario and connect it to the XML parsing module. Set the source data field to the XML content that includes the URL nodes, represented by the URL XML tag.
<url>
<loc>https://moscot.com/en-gb/products/frankie</loc>
<lastmod>2024-06-09T08:16:26-04:00</lastmod>
<changefreq>daily</changefreq>
<image:image>
<image:loc>https://cdn.shopify.com/s/files/1/2403/8187/products/frankie-color-blonde-pos-2.jpg?v=1697426988</image:loc>
<image:title>FRANKIE</image:title>
<image:caption>#color_blonde | The FRANKIE in Blonde</image:caption>
</image:image>
</url>So, for every URL block, we’ll trigger a new action on the following node.

Configure the iterator to iterate over each URL listed in the sitemap, ensuring that each URL will be processed in subsequent steps.
Downloading HTML Content from Each URL
With the URLs in hand, the next phase involves downloading the HTML content of each URL. Add another HTTP module to your scenario, selecting the action to get a file. Connect this module to the iterator to ensure it dynamically pulls each URL as the iterator processes them. Map the URL field, situated in the loc attribute, to the output of the iterator and configure the module to save the HTML content. This setup fetches the HTML content of each product page, laying the groundwork for data extraction.

Parsing HTML Content
Make.com has an interesting built-in node that transforms HTML into Markdown text, making it more digestible for the following steps.

Sending HTML to ChatGPT for Data Extraction
After the HTML has been translated to plain Markdown text, we can use the ChatGPT connector available on Make.com, in particular, we’re using the Transform Text to Structured Data node.

We’ll write a general prompt to give the context to the model and then, field by field, we’ll write what we want ChatGPT to extract for us.
In our case, I wanted to extract the product name, full price, price, ISO code of the currency used on the page, URL of the main image of the product, and product details.
Due to the limitations on the number of requests per minute I can make to the GPT-4o model, I needed also to add a sleep node after the ChatGPT one, otherwise, I would have been rate-limited.
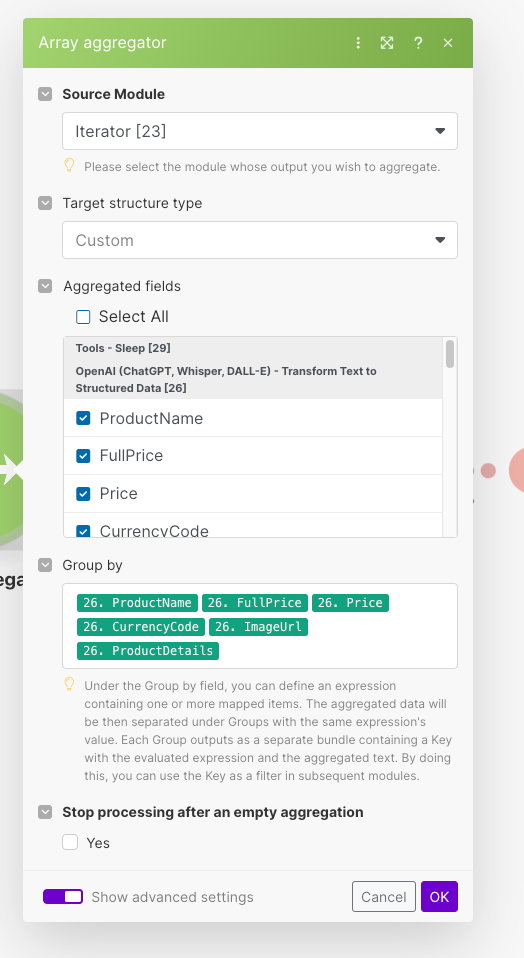
Aggregating items in a single data structure
To close the iteration loop, we need to add a built-in aggregator node, that gets every single result from ChatGPT and appends it to an array of items, defined by our final data structure.
Appending Data to a CSV File
Once the structured data is extracted, the next task is to append this data to a CSV file.
We’re adding a CSV node, in particular a Create CSV file (advanced) node, which allows us to map every field exited from the aggregator node to the same output field of the CSV.
Uploading the CSV File to AWS S3
The final step in this process involves uploading the CSV file to AWS S3. Add an AWS S3 module to your scenario and configure it to upload a file. Provide your AWS access and secret keys, specify the S3 bucket name where you want to upload the file, and set the file path to the CSV file you wish to upload. Choose a desired file name for the uploaded file. Save the configuration and run a test to verify that the file is successfully uploaded to S3.

Finalizing and Running the Automation
Sending the file to AWS was the last step of our data pipeline, which is ready to be executed and scheduled.
The starting signal can be a trigger, a scheduled time, or a manual start, depending on our needs.
Conclusion
As you might have seen in this tutorial, we didn’t need any code if not a high-level understanding of what an XML is, how to use ChatGPT properly, feeding it with markdown instead of pure HTML, how to get AWS keys, and stuff like that. If you’re a bit tech-savvy but not a programmer, this approach can be life-changing for your productivity at work, with some limitations.
First of all, we do not consider that several websites have an anti-bot in place. In this case, retrieving the sitemap or the pages by simply using an HTTP request node on Make.com is not enough and we’ll need to create a proper web scraper.
In a second instance, this approach is far from efficient, especially for the time constraint we have on the OpenAI APIs. If we want to speed up our no-code scraper, we can use an HTML node allowing us to write our selectors to extract data.

But even if we manage to reduce the execution time of our scraper, it would be extremely expensive to run for websites with thousands of pages. Since Make.com bills per operation (so every single node in our pipeline counts as an operation), having 1000 pages to scraper in our case would mean 5000+ operations per single scrape. Consider that 20k operations on the basic plan cost 16 dollars per month, while the operational costs of a coded scraper of this size would probably be less than a euro.
While this is for sure a solution that cannot be adopted on a larger scale, it could give a great productivity boost automating tasks requiring a small and sporadic use of web data.