
THE LAB #77: Building a Web Scraping Knowledge Assistant with RAG
How to include scraped data in your AI assistant

If you’re working in a company that uses web data, you know for sure that it’s just the first layer of a more complex product. In fact, web-scraped data has traditionally been stored in files or databases (cloud storage buckets, data lakes, or data warehouses) and then analyzed using Business Intelligence (BI) tools, both commercial and proprietary. For example, a team might scrape product prices or customer reviews from the web, save the raw data as CSV/JSON files, load it into an SQL data warehouse, and then use BI platforms like Tableau or Power BI to create dashboards and reports. Modern web scraping solutions even output data in structured formats (CSV, JSON, Excel, etc.) specifically to facilitate this pipeline, making it easy to feed the results into existing analytics systems. This process allows analysts to slice and dice the data for insights, but it requires manual effort to formulate queries or build visualizations.
Today, Large Language Models (LLMs) are changing this paradigm. Instead of relying solely on static dashboards or SQL queries, organizations can use AI assistants to derive insights from scraped data via natural language prompts. In other words, rather than a human writing a query or interpreting a chart, an AI assistant can directly answer questions about the data. Think about having your ChatGPT-like interface and write some prompts to get insights, bypassing the dashboard creation. I’ve seen this kind of approach in several products before LLMs came out but with no great success. The evolving AI landscape and the weekly improvements we see in LLMs could change the landscape, shifting data exploration from a BI-centric approach to an AI-centric one.
Imagine asking, “Which competitor had the highest price last quarter?” instead of finding the right dashboard or Excel report by yourself to get the response. This approach promises faster, more intuitive access to information for non-technical users without the overhead of building charts or writing code. In the past companies where I worked, I’ve seen too many times a proliferation of different dashboards per group of users (if not per user), sometimes extracting different numbers from each other.
Of course, a new set of challenges arise: what about hallucinations? If we don’t see the underlying number of an answer, can we be 100% sure that the answer is correct?
In this post (and the next one in the Lab series), we'll build an end-to-end project where we’ll start by scraping the articles in this newsletter, putting them in a database suitable for AI use, retrieving this knowledge, and then publishing a web app that can use an enriched version of a GPT model.
Improving LLM Knowledge
Integrating custom data (like your scraped dataset) into an LLM can be done primarily in two ways: by fine-tuning the model or by using Retrieval-Augmented Generation (RAG), and each of these methods has pros and cons. Let’s see how they differ and which approach could be the best for our use case.
Fine-Tuning vs. Retrieval-Augmented Generation
Fine-tuning means training the base LLM on additional data so it absorbs new knowledge. Essentially, you take a pre-trained model and continue training it on your domain-specific dataset, adjusting its weights to embed that knowledge. For example, if you scraped a collection of technical articles, you could fine-tune an LLM on those articles. After fine-tuning, the model intrinsically knows the information (to the extent it was represented in the training data). Fine-tuning is often done by providing the model with a large set of question-answer pairs or text passages from your data so it learns to respond with that information when relevant. In effect, the model is augmented from the inside – the knowledge becomes part of its parameters. The next time you query the model, it can draw on this baked-in information without needing external help.
Retrieval-Augmented Generation (RAG) takes a different approach: the model remains unchanged, but we give it access to an external knowledge base (usually via a vector search). When a query comes in, the system will retrieve relevant documents from your data and feed those into the model along with the question. The LLM then generates its answer with the help of that supplemental context. For boomers like myself, consider it like inserting a CD in the Neo’s head in Matrix to learn new skills and moves. In our case, the knowledge base could be a collection of scraped web articles stored in a specialized database. RAG is like an open-book exam for the LLM – at query time it looks up the relevant “page” of data and uses it to formulate a response, instead of relying solely on its internal memory.
As you can imagine, one key difference is where the additional knowledge stays: with fine-tuning, the knowledge is embedded in the model itself (the model’s weights are updated). With RAG, the knowledge stays external, in a database or index, and is fetched as needed. Fine-tuning is akin to teaching the model new facts permanently, whereas RAG is like equipping the model with a dynamic library it can reference on the fly.
The two approaches have different pros and cons:
Fine-Tuning:
Pros: Once fine-tuned, the model can respond faster and more integratedly to new knowledge. It doesn't need lengthy prompts with documents each time. A well-fine-tuned model typically outperforms the base model on domain-specific questions because it has a deeper understanding of that niche terminology and content.
Cons: Fine-tuning can be resource-intensive and time-consuming – you need sufficient training data and computing power (or budget if using a service). It also makes the model static concerning that training snapshot. If your scraped data changes or new information comes in, you’d have to fine-tune again to update the model. There’s also a risk of the model forgetting or overriding some of its original knowledge if not carefully managed. Importantly, fine-tuning means your data becomes part of the model’s parameters, which could be a privacy concern if the model weights are exposed or if using a third-party service to fine-tune (your data is uploaded for training). Last but not least, once the knowledge is embedded in the model, you cannot cite any article used to improve it.
Retrieval-Augmented Generation (RAG):
Pros: No need to modify the LLM itself – you leave the base model as-is and simply provide relevant context at query time. This makes updating or expanding the knowledge base easy: add or remove documents in your external index, and the model will use the latest data. It’s very flexible and keeps your proprietary data external (which can be more secure). RAG can reduce hallucinations by grounding answers in real sources – essentially, the model has the “receipts” to back up its answer. It also typically requires less upfront work than full fine-tuning; most effort goes into setting up the retrieval system.
Cons: RAG introduces more moving parts – you need a system for embedding and indexing documents and retrieving them at runtime. At query time, you pay the cost in latency and token length for feeding documents into the model’s prompt. If the retrieved documents aren’t relevant (due to a bad query or vector mismatch), the answer will suffer. The LLM is also limited by its input size; if the documents plus question exceeds the model’s context window, you might have to truncate or select fewer documents. Additionally, the raw text of documents might influence the model's style, which could lead to less coherent or conversational answers unless you prompt it to refine the wording.
In short, fine-tuning bakes in a focused understanding, whereas RAG allows real-time access to knowledge. For our use case of integrating constantly updated scraped data, RAG seems a better approach: you can continuously pull in new web data and have your assistant use it immediately rather than periodically retraining the whole model.
Before moving on, it’s worth noting that fine-tuning and RAG aren’t mutually exclusive; they can complement each other. For instance, you might fine-tune a model to adjust its tone or ability to follow instructions (or to add knowledge that is small and static), and still use RAG to give it access to a larger knowledge base that updates frequently. In practice, though, RAG alone often provides a simpler and more scalable path for enabling an AI assistant to handle custom knowledge, which is the path we’ll focus on in our implementation.
Using a Local Model vs. an External API
Another consideration is what LLM to use for your AI assistant: a local (open-source) model you run yourself or a hosted model via an API (like OpenAI’s GPT-3.5/GPT-4 or others). Both fine-tuning and RAG can be done with either, but there are trade-offs:
Local Open-Source LLMs – Models such as LLaMA 2, Mistral, or Falcon can be run on your own servers. The big benefit here is control and privacy. Your scraped data never leaves your environment, which is important if it contains sensitive information. You can fine-tune them freely on your data or modify how they work. Cost-wise, running a local model might be cheaper for large volumes of queries (no API fees), but you have to invest in hardware or cloud infrastructure to host it. The downside is that many open models could not match the performances of the newest GPTs. You might need to use larger or more specialized models to get comparable performance, which can be complex to manage. Additionally, maintaining and updating the model (and possibly the vector database if on-prem) is on you. In case you do have a highly domain-specific dataset and the expertise, a local model can be fine-tuned to excel in that domain, making it a strong solution for a “private GPT.”
External API LLMs (e.g. OpenAI’s) – Using an API like OpenAI’s GPT-4 means you don’t have to worry about running the model; you just send your prompts to their service and get the completion. This is very convenient and typically gives you access to cutting-edge model quality with no infrastructure hassle. For our scenario, you could use RAG by simply prepending the retrieved documents to your prompt and asking the API to answer. The drawbacks here relate to customization and privacy. Not every model is available for fine-tuning (OpenAI, for example, allows you to do it on GPT4-o and GPT4-mini). You’re also subject to the provider’s rules (for example, they might have content filters that could prevent some scraping-related queries). From a privacy standpoint, you are sending your data (query and retrieved context) to a third party, so I won’t suggest this approach for sensitive or copyrighted data. Another limitation is cost – each API call costs tokens, which can add up when you’re including a lot of context (scraped text) in prompts.
In general, if your use case involves highly sensitive data or requires full control, a local LLM is recommended despite the extra effort. If your priority is the best possible language ability and quick setup, a hosted model like OpenAI’s might be the better choice. In this post’s implementation, we’ll illustrate using OpenAI’s GPT API for simplicity and quality, but the retrieval system we build could just as easily feed into an open-source model like Llama2 via HuggingFace or LangChain libraries. The retrieval mechanism (vector database + similarity search) remains the same; only the final answer-generating model would differ.
Considering these decisions, let’s integrate my scraped articles into an AI assistant. We’ll use the RAG approach with an OpenAI model, which aligns well with continuously updated web data and avoids the need for costly fine-tuning jobs.
The script is in the GitHub repository's folder 77.RAG, which is available only to paying readers of The Web Scraping Club.
If you’re one of them and cannot access it, please use the following form to request access.
Scraping TWSC with Firecrawl
Firecrawl is a web scraping engine exposed as a REST API and SDK. It is specifically designed to turn websites into LLM-ready data (in formats like clean text or markdown), handling all the heavy lifting, such as crawling links, rendering JavaScript, and so on. The great benefit of Firecrawl is that with one API call, you can scrape an entire site. This makes it perfect for quickly grabbing all the content from my newsletter to feed into an AI.
For The Web Scraping Club blog, we’ll use its sitemap to discover all article URLs. (The blog is hosted on Substack, which provides an XML sitemap listing all posts.) Firecrawl could crawl the site without a sitemap, but using it as a starting point can be more efficient and ensure we don't miss any pages.
First, we set up Firecrawl by installing its Python SDK and authenticating with an API key (assuming you have signed up and obtained a key):
from firecrawl import FirecrawlApp
import os
os.environ["FIRECRAWL_API_KEY"] = "YOURKEY" # or load from .env
app = FirecrawlApp()
# Define the sitemap URL (we can loop this for multiple years if needed)
map_result = app.map_url('https://substack.thewebscraping.club/sitemap.xml', params={
'includeSubdomains': True
})
print(map_result)
for article in map_result['links']:
if '/p/' in article:
print(article)
response = app.scrape_url(url=article, params={'formats': [ 'markdown' ]})
With just a few lines of code, our articles are already in Markdown format.
Choosing a Vector Database for RAG
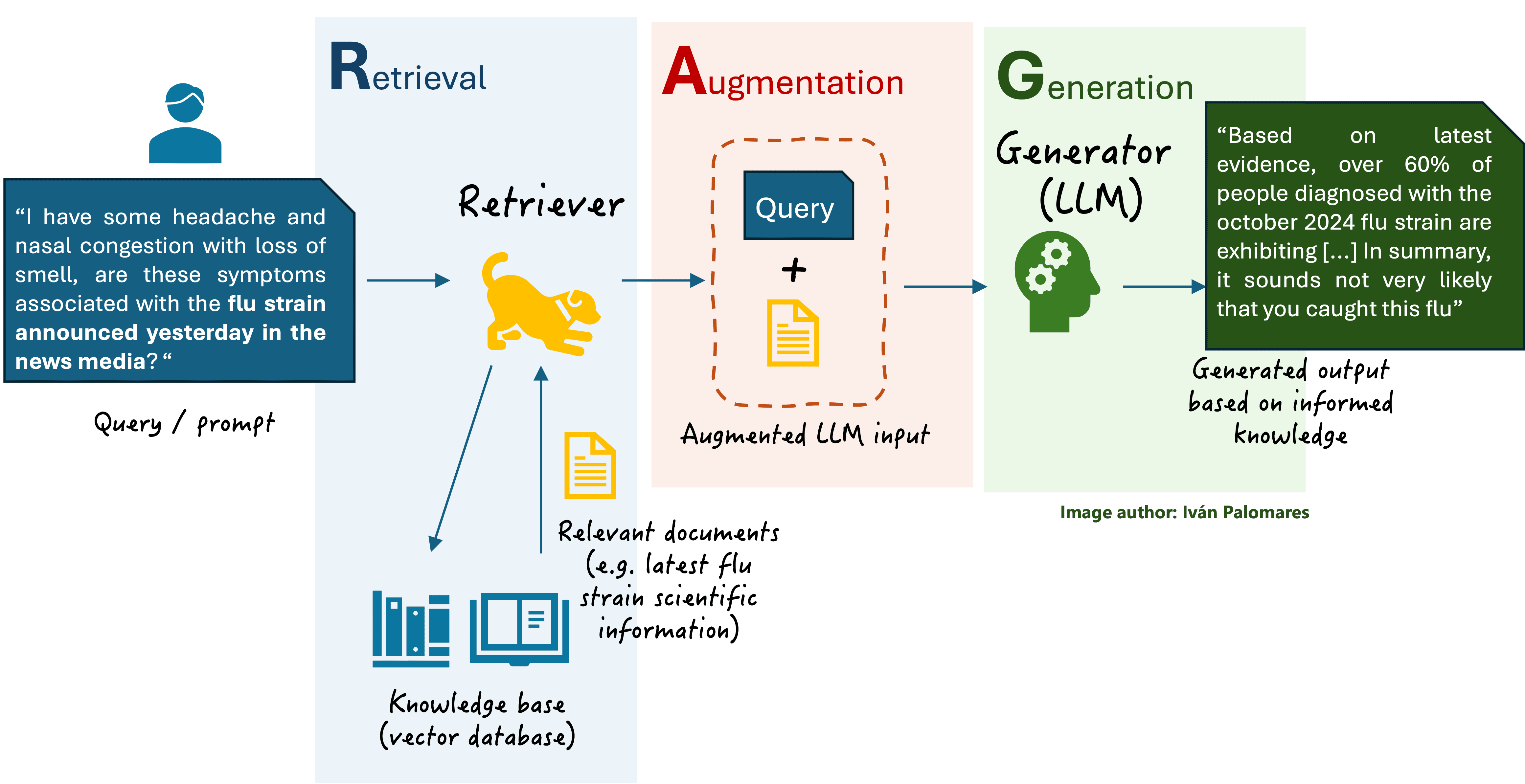
A vector database is a key component of RAG implementation. It stores your documents' embeddings (vector representations) and allows fast similarity search to fetch relevant documents for a given query embedding. Many options are available, including open-source libraries and managed cloud services, but for our implementation, we will use Pinecone.
