
THE LAB #18: How to scrape Reddit with Scrapy
Scraping subreddits without any commercial product

This post is sponsored by Bright Data, award-winning proxy networks, powerful web scrapers, and ready-to-use datasets for download. Sponsorships help keep The Web Scraping Free and it’s a way to give back to the readers some value.

In this case, for all The Web Scraping Club Readers, using this link you will have an automatic free top-up. It means you get a free credit of $50 upon depositing $50 in your Bright Data account.
What is Reddit?
Reddit is a social news aggregation and discussion website that has been around since 2005. It is a platform where users can post content such as links, text posts, images, and videos. Other users can then vote on the posts and comment on them, which results in a ranking system that determines which posts are displayed at the top of the page.
Reddit has become one of the most popular websites on the internet, with over 430 million active users as of 2021. It is known for its unique community-driven structure, which allows users to create and manage their own communities, known as subreddits.
In 2021 it gained even more popularity because of the subreddit “WallStreetBets”, which propelled the price of Gamestop stocks from 3$ to more than 450$, before going back to 60$. You can read a great write-up of this story in this article.
Because of Reddit’s popularity, it’s becoming a great source for extracting some valuable data, be it sentiment analysis on some companies, comments to the news, or, as we just have seen, financial crazes by retail investors.
How to scrape Reddit then?
In October I wrote about Datadome and, as an example of a website protected by it, I’ve mentioned Reddit, with also a screenshot proving it.

This solution would make scraping it really expensive in the long run. But while preparing this article, I noted that Datadome disappeared from the security tools applied.
Something that is confirmed also by the fact that now it’s possible to scrape it with a simple Scrapy program, without the need of any headful browser. Of course, this must be done always in an ethical and legit way, without overloading the target website.
I’ve browsed the web for some news about this fact but I’ve found nothing, so maybe it has been disabled only temporarily or maybe the contract ended. I can only imagine the bills to pay for protecting such a visited site.
In any case, against the tide of how web scraping is going, this makes the scraping much easier and today we’ll see two solutions, one is pretty basic where we use Scrapy to parse the HTML code, while in the second we’ll query directly the GraphQL API.
Before proceeding, some self-promotion. I’ve been invited by Smartproxy as a guest in their next webinar. We’ll talk about web scraping in general, the challenges to tackle when managing large-scale projects, and the tools and tricks learned in my 10 years of experience in this field.

To subscribe to the webinar, you can use the following link to the platform. It’s free and I promise I won’t be too much boring.
First solution: Scrapy to parse HTML
As always, all the code can be found in the Github repository, reserved for paying readers.
As we said, this solution is plain vanilla.
We start reading a file containing the list of subreddits we want to scrape and parse the JSON contained in the code to grab the URLs of the posts and some stats we would not find on the page of the single comment.

Then, entering the single comment page, we complete the scraping with the following function.
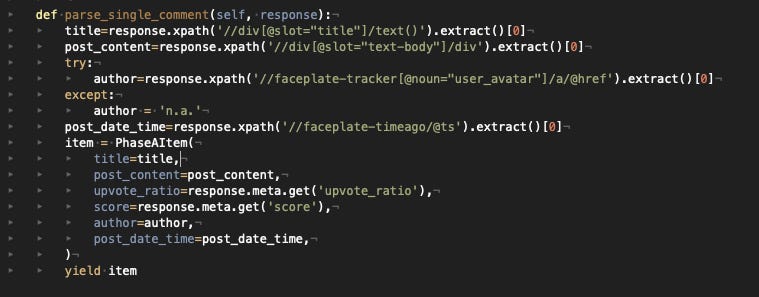
Definitely, it’s not rocket science but it works. We get every single comment of a subreddit, some stats about upvotes, its author, the title, and the content of the comment, in HTML format.
Second option: scrape the GraphQL API
This is the solution I like the most.
API change less frequently than HTML, require less bandwidth and, in this case, we have all the data we need without entering in the single comment page, reducing drastically the number of requests to be made. We have seen what’s GraphQL and how it works, and its benefits for web scraping in this past article.
